






猫眼经典影片的爬取
在进行数据爬取的时候一定要设置好cookie
cookie_url='https://maoyan.com/'
response=requests.get(cookie_url)
cookie=response.cookies
_csrf=cookie['_csrf']
uuid=cookie['uuid']
uuid_n_v=cookie['uuid_n_v']
猫眼设置了反爬机制需要构造header
header={
'Upgrade-Insecure-Requests':'1',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language':'zh-CN,zh;q=0.9',
'Host':'maoyan.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Cookie':'uuid_n_v={};_csrf={};uuid;{}'.format(uuid_n_v,_csrf,uuid),
}
对每个电影详情页的url进行获取
url_list=[]
response=requests.get(url,headers=header,allow_redirects=False).text
tree=etree.HTML(response)
div=tree.xpath("//div[@class='movies-list']//dd")
for li in div:
detail_url=li.xpath("./div/a/@href")[0]
if detail_url is not None:
detail_url='https://maoyan.com'+detail_url
url_list.append(detail_url)
对详情页的评分人数,评分,国家的等信息进行解析获取
在爬取的时候遇到报错,就是数据获取为空,所以就是获取每个数据都会进行判断
response=requests.get(detail_url,headers=header,allow_redirects=False)
tree=etree.HTML(response.text)
name=tree.xpath("//div[@class='movie-brief-container']/h1/text()")
print(name)
if len(name)==0:
name=None
else:
name=name[0]
types=tree.xpath("//div[@class='movie-brief-container']/ul/li[1]/a/text()")
movie=tree.xpath("//div[@class='movie-brief-container']/ul/li[2]/text()")
if len(movie)==0:
country=None
minute=None
else:
movie = movie[0].replace('\n', '')
if '/' in movie:
country = movie.split('/')[0]
minute = movie.split('/')[1]
else:
country = movie
minute = '暂无'
screen_time=tree.xpath("//div[@class='movie-brief-container']/ul/li[3]/text()")
if len(screen_time)==0:
screen_time='暂无'
else:
screen_time=screen_time[0]
score=tree.xpath("//div[@class='movie-index-content score normal-score']/span/span/text()")
people_score=tree.xpath("//span[@class='score-num']/span/text()")
box_office=tree.xpath("//div[@class='movie-index-content box']//span/text()")
在这里想必很多人都知道对评分人数,累计票房等设置了字体反爬机制,所以在这里需要下这个

在代码中需要对这个数据进行解析``
from fontTools.ttLib import TTFont
fonts=TTFont('f0a30a4dda64b4f8f344858115f54fc92296.woff')
fonts.saveXML('a.xml')
解析成xml后,打开解析的文件,在这里我们需要下载High-Logic
FontCreator软件,用这软件把f0a30a4dda64b4f8f344858115f54fc92296.woff打开

然后对比打开的a.xml
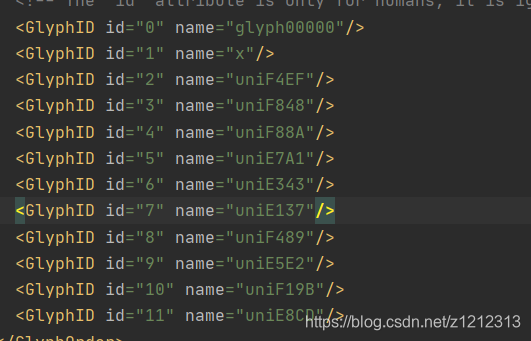
找到规律
data_temp={'e137':'8','e343':'1','e5e2':'4','e7a1':'9','e8cd':'5',
'f19b':'2','f489':'0','f4ef':'6','f848':'3','f88a':'7','x':'.'}
对字体进行解密,在这里我还发现,如果在用xpath获取数据时,
不能直接
tree.xpath("//div[@class='movie-index-content score normal-score']/span/span/text()")[0]
这样获取出来的是空的值
所以我只能用笨办法这样获取数据
def font_anaylis(score,people_score,box_office):
score=str(score).replace('[', '').replace(']', '').replace('\\u', '').replace("'", "")
if score is not '':
#print(score)
if '.' in score:
score=score.split('.')
score=data_temp[score[0]]+'.'+data_temp[score[1]]
elif len(score)>4:
score='无'
else:
score = data_temp[score]
else:
score='暂无'
people_score=str(people_score).replace('[','').replace(']','').replace('\\u','').replace("'","")
if people_score is not '':
#print(people_score)
if '.' in people_score:
l1=people_score[:people_score.index('.')]
alist1=[]
j=0
for i in range(3,len(l1),4):
people_scores1=data_temp[l1[j:i+1]]
alist1.append(people_scores1)
j += 4
total_score1=''.join(alist1)
l2=people_score[people_score.index('.')+1:]
alist2= []
j = 0
for i in range(3, len(l2), 4):
people_scores2 = data_temp[l2[j:i + 1]]
alist2.append(people_scores2)
j += 4
total_score2=''.join(alist2)
if len(l2)%2!=0:
s=l2[-1]
total_score=total_score1+'.'+total_score2+s
#print(total_score)
else:
total_score=total_score1+'.'+total_score2
#print(total_score)
else:
alist = []
j = 0
for i in range(3, len(people_score), 4):
people_scores = data_temp[people_score[j:i + 1]]
alist.append(people_scores)
j += 4
total_score = ''.join(alist)
#print(total_score)
else:
total_score='暂无'
#print(total_score)
box_office=str(box_office).replace('[','').replace(']','').replace('\\u','').replace("'","")
if box_office=='暂无':
total_office=box_office
#print(total_office)
else:
box_office=box_office.split(',')
box=box_office[0]
if '.' in box:
box1=box[:box.index('.')]
l1 = []
j = 0
for i in range(3, len(box1), 4):
bo1 = data_temp[box1[j:i + 1]]
l1.append(bo1)
j += 4
box1 = ''.join(l1)
box2=box[box.index('.')+1:]
l2=[]
j=0
for i in range(3,len(box2),4):
bo=data_temp[box2[j:i+1]]
l2.append(bo)
j+=4
box2=''.join(l2)
total_office=box1+'.'+box2+box_office[1]
else:
if len(box)==0:
total_office='空'
else:
list=[]
j=0
for i in range(3, len(box), 4):
bo= data_temp[box[j:i + 1]]
list.append(bo)
j += 4
box = ''.join(list)
total_office=box+box_office[1]
#print(total_office)
return score,total_score,total_office
这样基本数据都能获取,只不过在运行几次后,就会给你阻断了,获取的数据就会为空。
完整代码如下
import requests
from fontTools.ttLib import TTFont
from lxml import etree
import pandas as pd
from multiprocessing.dummy import Pool
import time
fonts=TTFont('f0a30a4dda64b4f8f344858115f54fc92296.woff')
fonts.saveXML('a.xml')
#print(fonts.getGlyphNames())
data_temp={'e137':'8','e343':'1','e5e2':'4','e7a1':'9','e8cd':'5',
'f19b':'2','f489':'0','f4ef':'6','f848':'3','f88a':'7','x':'.'}
cookie_url='https://maoyan.com/'
response=requests.get(cookie_url)
cookie=response.cookies
_csrf=cookie['_csrf']
uuid=cookie['uuid']
uuid_n_v=cookie['uuid_n_v']
header={
'Upgrade-Insecure-Requests':'1',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language':'zh-CN,zh;q=0.9',
'Host':'maoyan.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Cookie':'uuid_n_v={};_csrf={};uuid;{}'.format(uuid_n_v,_csrf,uuid),
}
result=[]
url='https://maoyan.com/films?showType=3&offset=0'
urls_page=['https://maoyan.com/films?showType=3&offset={}'.format(num*30) for num in range(0,2)]
url_list=[]
def page_num(url):
response=requests.get(url,headers=header,allow_redirects=False).text
tree=etree.HTML(response)
div=tree.xpath("//div[@class='movies-list']//dd")
for li in div:
detail_url=li.xpath("./div/a/@href")[0]
if detail_url is not None:
detail_url='https://maoyan.com'+detail_url
url_list.append(detail_url)
def get_url(detail_url):
#需要设置cookie,不然数据返回的是空的值
#new_cookie=requests.get(new_url,headers=header)
#print(new_cookie.cookies)
response=requests.get(detail_url,headers=header,allow_redirects=False)
tree=etree.HTML(response.text)
name=tree.xpath("//div[@class='movie-brief-container']/h1/text()")
print(name)
if len(name)==0:
name=None
else:
name=name[0]
types=tree.xpath("//div[@class='movie-brief-container']/ul/li[1]/a/text()")
movie=tree.xpath("//div[@class='movie-brief-container']/ul/li[2]/text()")
if len(movie)==0:
country=None
minute=None
else:
movie = movie[0].replace('\n', '')
if '/' in movie:
country = movie.split('/')[0]
minute = movie.split('/')[1]
else:
country = movie
minute = '暂无'
screen_time=tree.xpath("//div[@class='movie-brief-container']/ul/li[3]/text()")
if len(screen_time)==0:
screen_time='暂无'
else:
screen_time=screen_time[0]
score=tree.xpath("//div[@class='movie-index-content score normal-score']/span/span/text()")
people_score=tree.xpath("//span[@class='score-num']/span/text()")
box_office=tree.xpath("//div[@class='movie-index-content box']//span/text()")#票房单位
score,people_score,box_office=font_anaylis(score, people_score, box_office)
detail_txt(score, people_score, box_office, name, types, country, minute, screen_time)
def font_anaylis(score,people_score,box_office):
score=str(score).replace('[', '').replace(']', '').replace('\\u', '').replace("'", "")
if score is not '':
#print(score)
if '.' in score:
score=score.split('.')
score=data_temp[score[0]]+'.'+data_temp[score[1]]
elif len(score)>4:
score='无'
else:
score = data_temp[score]
else:
score='暂无'
people_score=str(people_score).replace('[','').replace(']','').replace('\\u','').replace("'","")
if people_score is not '':
#print(people_score)
if '.' in people_score:
l1=people_score[:people_score.index('.')]
alist1=[]
j=0
for i in range(3,len(l1),4):
people_scores1=data_temp[l1[j:i+1]]
alist1.append(people_scores1)
j += 4
total_score1=''.join(alist1)
l2=people_score[people_score.index('.')+1:]
alist2= []
j = 0
for i in range(3, len(l2), 4):
people_scores2 = data_temp[l2[j:i + 1]]
alist2.append(people_scores2)
j += 4
total_score2=''.join(alist2)
if len(l2)%2!=0:
s=l2[-1]
total_score=total_score1+'.'+total_score2+s
#print(total_score)
else:
total_score=total_score1+'.'+total_score2
#print(total_score)
else:
alist = []
j = 0
for i in range(3, len(people_score), 4):
people_scores = data_temp[people_score[j:i + 1]]
alist.append(people_scores)
j += 4
total_score = ''.join(alist)
#print(total_score)
else:
total_score='暂无'
#print(total_score)
box_office=str(box_office).replace('[','').replace(']','').replace('\\u','').replace("'","")
if box_office=='暂无':
total_office=box_office
#print(total_office)
else:
box_office=box_office.split(',')
box=box_office[0]
if '.' in box:
box1=box[:box.index('.')]
l1 = []
j = 0
for i in range(3, len(box1), 4):
bo1 = data_temp[box1[j:i + 1]]
l1.append(bo1)
j += 4
box1 = ''.join(l1)
box2=box[box.index('.')+1:]
l2=[]
j=0
for i in range(3,len(box2),4):
bo=data_temp[box2[j:i+1]]
l2.append(bo)
j+=4
box2=''.join(l2)
total_office=box1+'.'+box2+box_office[1]
else:
if len(box)==0:
total_office='空'
else:
list=[]
j=0
for i in range(3, len(box), 4):
bo= data_temp[box[j:i + 1]]
list.append(bo)
j += 4
box = ''.join(list)
total_office=box+box_office[1]
#print(total_office)
return score,total_score,total_office
def detail_txt(score,people_score,box_office,name,types,country,minute,screen_time):
lists=[]
lists.append(score),lists.append(people_score),lists.append(box_office),lists.append(name),\
lists.append(types),lists.append(country),lists.append(minute),lists.append(screen_time)
result.append(lists)
def to_csv(result):
df=pd.DataFrame(result,columns=['评分','评分人数','累计票房','电影名','电影类型','国家','时长','上映时间'])
df.to_csv('maoyan1.csv',index=False)
def main():
pool=Pool(10)
start=time.time()
pool.map(page_num,urls_page)
pool.map(get_url,url_list)
to_csv(result)
pool.close()
pool.join()
end=time.time()
times=end-start
print(times)
#return times
if __name__=="__main__":
main()
不知道有没有更好的办法















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









