




1 html+css布局
1.1 html5新特性🌟
-
语义化标签。【header、nav、footer、aside、article、section】
-
音频、视频API。【audio、video】
-
input的type新类型。【calendar、data、time、email、url、search】
-
input的新属性。【required、placeholder、autofocus、multiple、autocomplete】
-
本地存储localStorage和sessionStorage。localStorage浏览器关闭后不丢失,sessionStorage浏览器关闭后修饰
-
拖拽释放API、画布API、地理API、新的webworder、webscoket、geolocation
1.2 怪异盒模型🌟
提问:盒模型宽度如何计算?计算时有什么区别?有哪两种情况
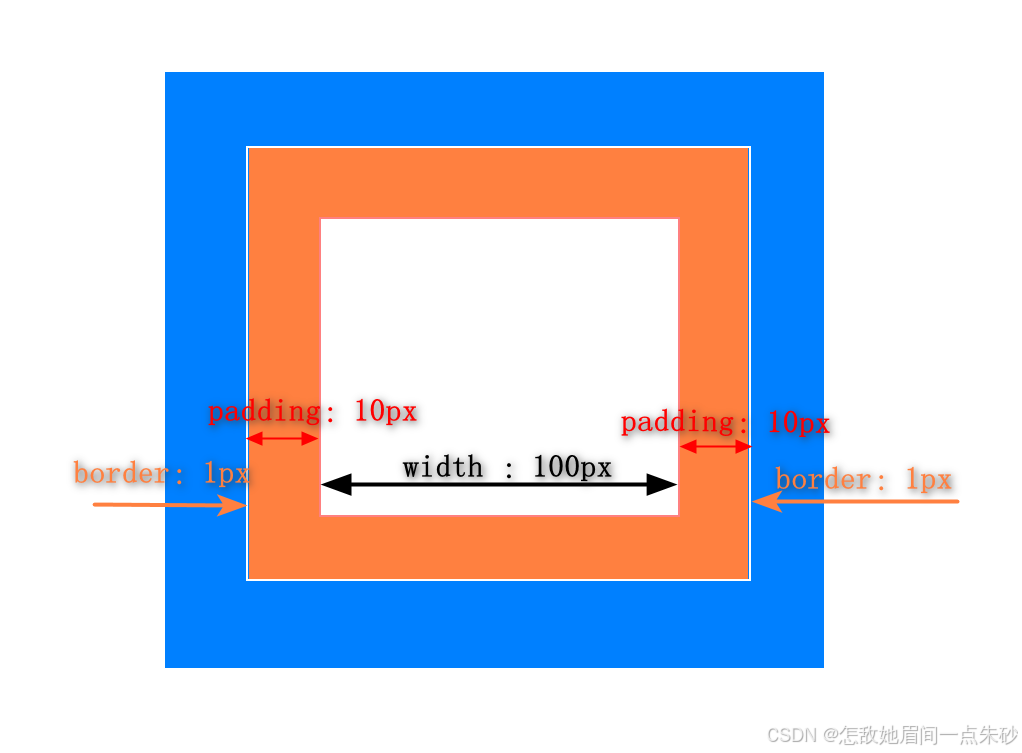
回答:普通盒模型和怪异盒模型两种,普通的宽度是width+padding+border;怪异的是把padding和border都挤在width里面。
-
普通盒模型
-
默认盒子属性:box-sizing: content-box;
-
offsetWidth = (width + padding + border) 不算margin
-
-
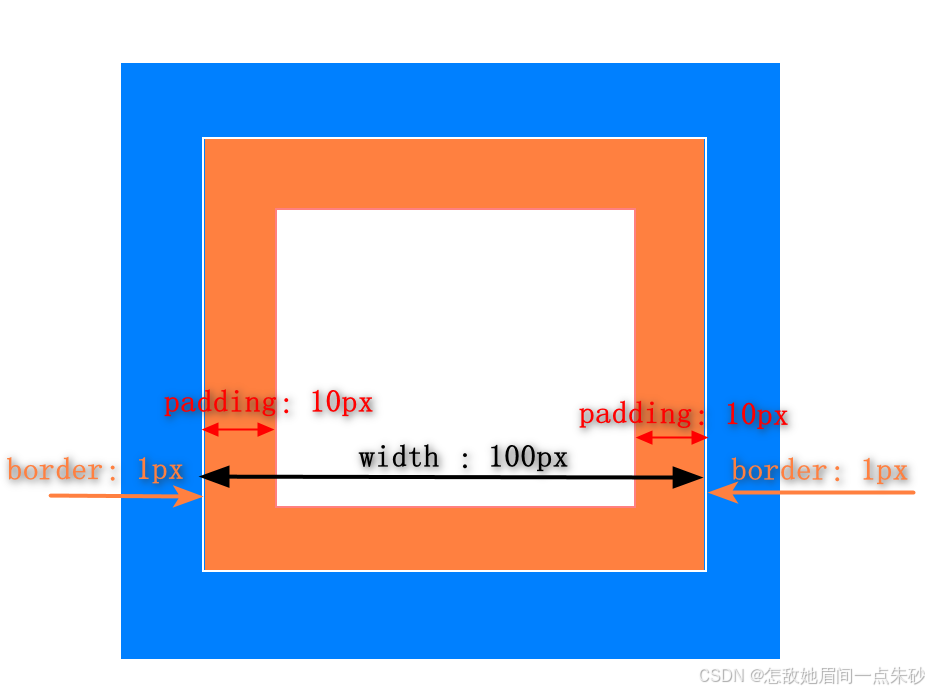
怪异盒模型
-
设置语句:box-sizing: border-box;
-
offsetWidth = width padding和border都挤压到内容里面
-
1.3 CSS3的选择器🌟
-
通配符选择器(*)、标签选择器、类选择器、id选择器
-
属性(参数)选择器
-
组合选择器
- A,B 选择匹配A或者匹配B的元素;
- A B A后代中的B;
- A:B A的直接子元素中的B;
- A + B A的下一相邻元素B;
- A~B。 A的下N个相邻元素B。
-
伪类选择器:link、visited、hover、active、first-child、last-child、nth-child(n)
-
伪元素选择器:before、after、section、first-letter、first-line
1.4 布局模式🌟
单独制作移动端页面(主流):流式布局、flex弹性布局、less+rem+媒体查询布局、混合布局
响应式页面兼容移动端(其次):媒体查询、bootstrap
1.4.1 flex布局
元素结构:容器内部放子元素,容器设置display:flex
父项属性:
-
flex-direction:设置主轴方向;
-
justify-content:设置主轴上子元素的排列方式
-
flex-wrap:子元素是否换行
-
align-content:设置侧轴上子元素的排列方式(单行)
-
align-items:设置侧轴上子元素的排列方式(多行)
-
flex-flow:复合属性,相当于同时设置flex- direction和flex-wrap
子项属性
-
flex:子项目占比
-
align-self:子项在侧轴的排列方式
-
order:子项的排列顺序
1.4.2 flex布局应用场景
-
搜索栏:搜索框和搜索按钮
-
导航栏:单行导航和多行导航
1.5 盒子塌陷🌟
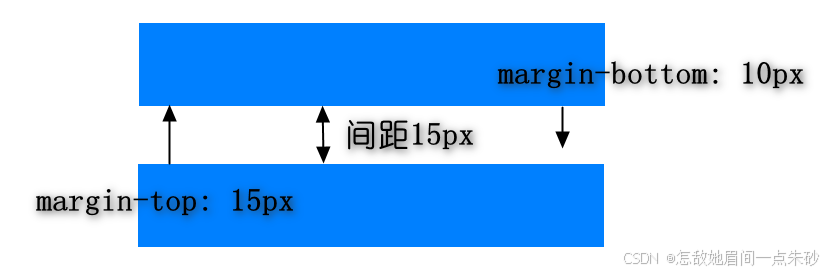
margin纵向重叠取重叠区最大值,不进行叠加
1.5.1 margin纵向重叠
margin纵向重叠取重叠区最大值,不进行叠加
1.5.2 margin负值问题
-
margin-top和margin-left 是负值,元素会向上或者向左移动
-
margin-right 负值,右侧元素左移,自身不受影响
-
margin-bottom负值,下侧元素上移,自身不受影响
1.6 BFC🌟
BFC是一块独立的渲染区域,内部元素的渲染不会影响到边界以外的元素。
-
Block Format Context :块级格式化上下文
-
一块独立的渲染区域,内部元素的渲染不会影响边界以外的元素
-
形成BFC的条件
-
float 不设置成none
-
position 是absolute或者fixed
-
overflow 不是visible
-
display是flex或者inline-block 等
-
-
应用:
-
清除浮动
-
1.7 重绘和重排(回流)🌟
重绘:DOM树中没有元素被增加或者删除,只是样式的改变。
回流:DOM树中的元素被增加或者删除。
常见引起回流的场景:
-
添加或者删除可见的DOM元素;
-
元素的尺寸或者位置发生变化;
-
元素内容变化,比如文字数量和图片大小;
-
浏览器窗口大小发生变化;
-
CSS伪类的激活。
1.8 清除浮动的五种方式🌟
-
额外标签法
#clear{ clear:both; } -
父元素添加法
#parent{ overflow:hidden; } -
父元素设置高度
-
after伪元素法
#parent:after{
content:"";
display:block;
height:0;
clear:both;
visibility:hidden;
}
#parent{
*zoom:1;
}5.before和after双伪元素
#parent:after,#parent:before{
content:"";
display:table;
}
#parent:after{
clear:both;
}
#parent{
*zoom:1;
}1.9 元素居中🌟
1.9.1 定位回顾
-
relative相对自身定位
-
absolute 依据最近的一层的定位元素定位
-
定位元素:设置了absolute、relative、fixed
-
找不到最近定位元素 ,依据body
-
1.9.2 行内元素居中
-
水平居中: text-align: center
-
垂直居中: line-height:盒子高度
1.9.3 块级元素居中
-
水平居中:
-
margin : 0 auto;
-
-
水平垂直都居中
-
position:absolute; top: 50%;left: 50%;transform:translate(-50%,-50%)
-
position:absolute; top: 0;left: 0;right: 0; bottom: 0; margin: auto;
-
容器设置:display:flex ; justify-content: center; align-items: center
-
容器:display:table-cell; text-align:center; vertical-align: middle; 子元素:display: inline-block;
-
1.10 em、rem、vh、vw单位
-
em:相对于自身字体大小的单位
-
rem:相对于html标签字体大小的单位
-
vh:相对于视口高度大小的单位,20vh == 视口高度/100*20
-
vw:相对于视口宽度大小的单位, 20vw == 视口宽度/100*20
1.11 移动端响应式
1.11.1 流式布局(百分比)
-
不能改变字体大小,可改变元素尺寸,高度固定
1.11.2 flex (弹性盒)
-
使用方便,通常配合其他方案一起使用
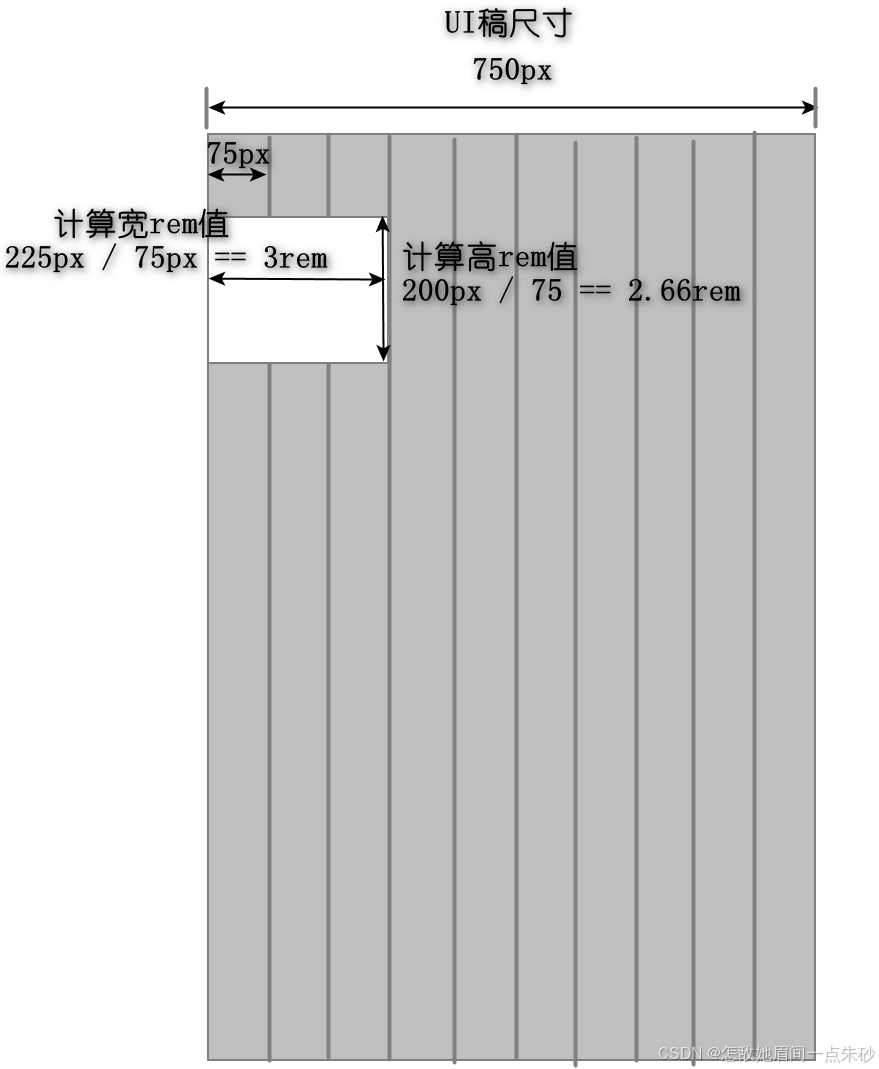
1.11.3 rem + 媒体查询/flexible.js
-
改变单位,字体大小元素尺寸均可改变
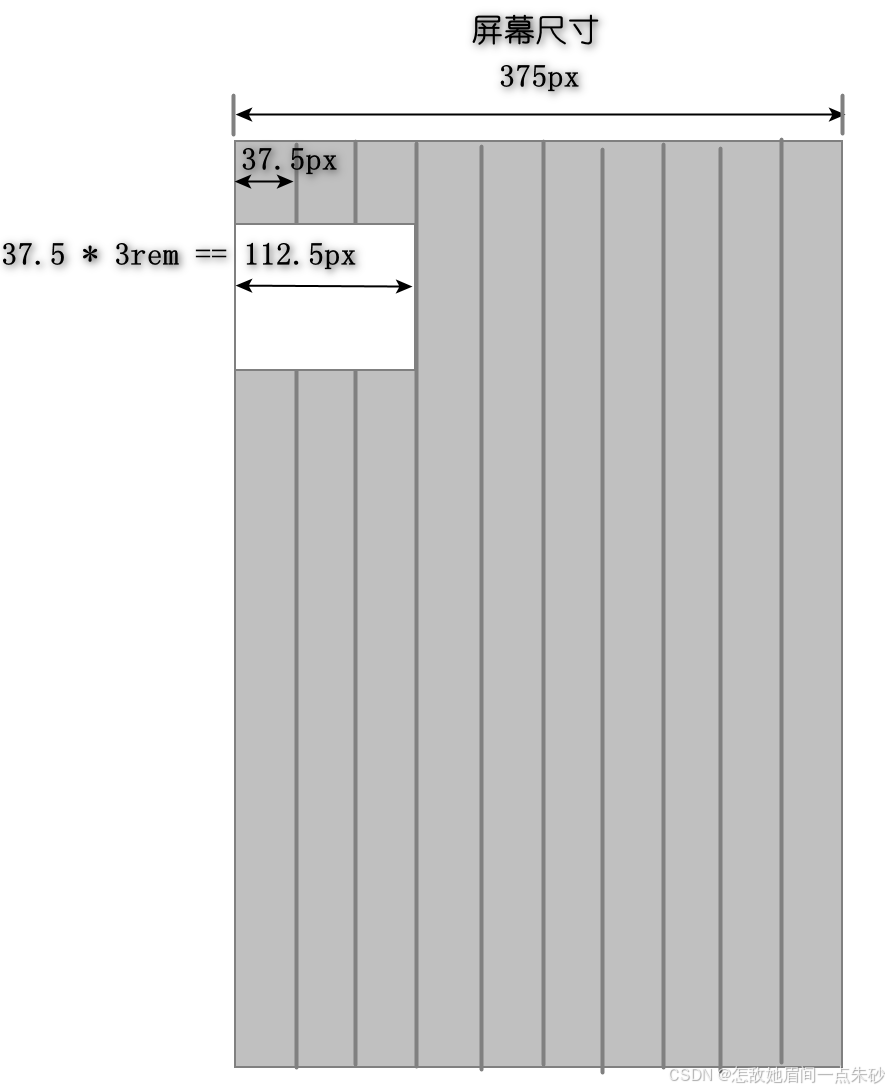
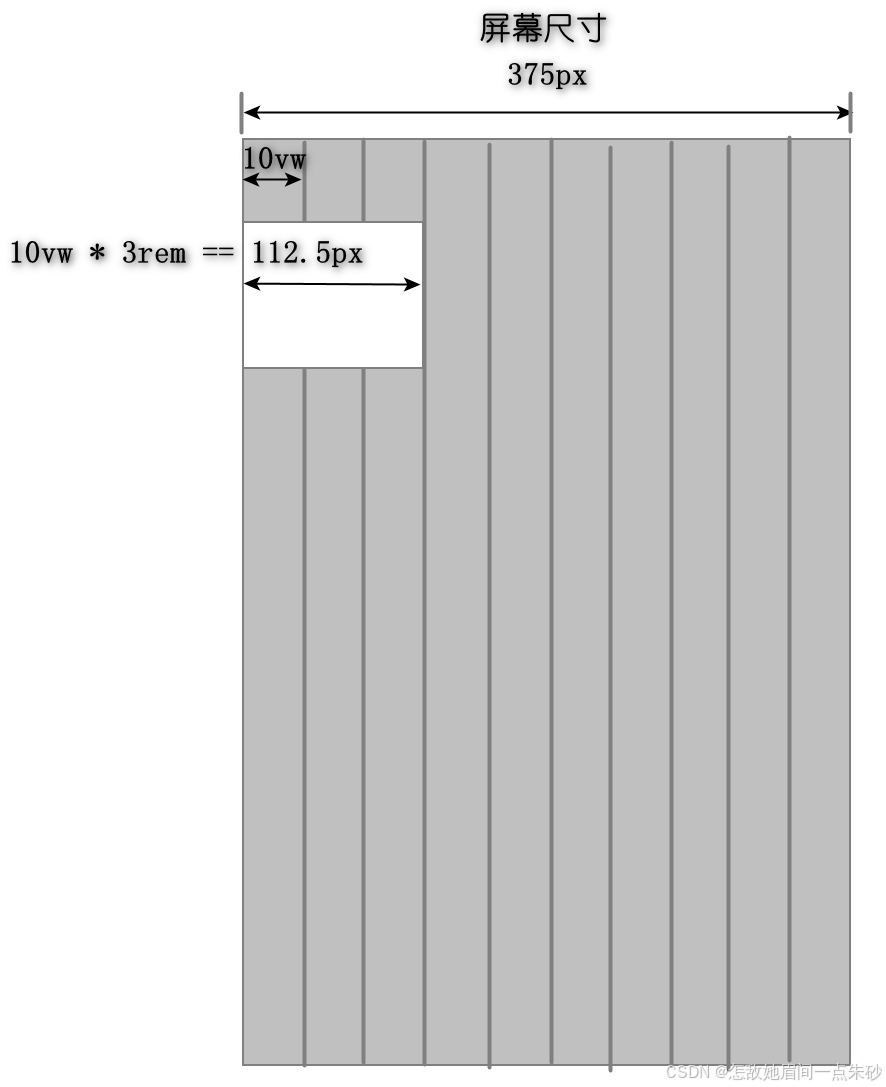
1.11.4 rem + vw
-
兼容性不如前面的
1.12 DOM事件流🌟
事件流描述的是从页面接收事件的顺序,事件发生时会在元素节点之间按照特定的顺序传播,这个传播过程即DOM事件流。
阶段:捕获阶段——>目标阶段——>冒泡阶段
1.12.1 事件委托
将子元素的事件委托给父元素。
假设有一个ul里面有100个li,现在需要向每一个li绑定一个点击事件,如果什么都不考虑的话,我们就可以拿到这个li的数组,然后来进行循环遍历,分别去绑定;但是这样需要遍历100次,效率比较差。
还有一个重要原因是,假设后期我又添加了100个li,那么后期添加的li并没有点击事件。
解决方法:将子元素的点击事件绑定到父元素ul上面去,这样后面添加的li也会拥有绑定事件。
事件绑定的原理:冒泡
触发事件的是:子元素
找触发事件的对象:event.target
target和currentTarget的区别:
-
currentTarget:要求绑定的元素一定是触发事件的元素,这样我们才能通过它,找到我们触发事件的元素
-
target:绑定事件的元素,不一定是触发事件的元素
1.13 CSS3的新特性🌟
-
新增选择器:属性选择器、结构伪类选择器、伪元素选择器
-
CSS过渡:transition:要过渡的属性 花费时间 运动曲线 何时开始
-
2D转换
-
动画keyframes
-
3D移动
1.14 圣杯布局和双飞翼布局
1.14.1 作用
-
实现pc端三栏布局,中间一栏最先渲染
-
实现两边宽度固定,中间自适应
-
效果图

1.14.2 圣杯布局
-
为了让中间盒子最先渲染,所以中间盒子放在三个盒子的第一个位置

-
左中右盒子全部浮动

-
防止中间内容被两侧覆盖,一个用padding

-
两侧使用margin负值,分别放置左右两边
-
左边margin-left: 100%

-
左边平移padding宽度

-
右边盒子margin-right : -200px (设置成自身宽度,且是负值,平移到上一行)

-
1.14.3 双飞翼布局
-
中间盒子最先渲染

-
全部浮动

-
为了不让左右盒子覆盖中间盒子内部,中间盒子内部设置margin

-
左边盒子设置margin-left: -100%;

-
右边盒子设置 margin-left: -200px ;和圣杯布局设置不一样原因是圣杯布局的margin是放在同一个外层盒子中,而双飞翼布局是三个独立的盒子,右盒子是被挤下去的

1.15 手写clearfix
.clearfix::after {
content: '';
display: table;
clear: both;
}
/* 兼容IE低版本 */
.clearfix {
*zoom: 1;
}1.16 样式预处理器
1.16.1 sass
CSS 本身可能很有趣,但是样式表正变得越来越大、 越来越复杂、越来越难以维护。这就是预处理可以提供帮助的地方。 Sass 为你提供了 CSS 中还不存在的特性,例如变量、 嵌套、混合、继承和其它实用的功能,让编写 CSS 代码变得再次有趣。
1.16.2 sass和scss的区别
CSS 是 Sass 3 引入新的语法,其语法完全兼容 CSS3,并且继承了 Sass 的强大功能。Sass 和 SCSS 其实是同一种东西,我们平时都称之为 Sass,两者之间不同之处有以下两点:
-
文件扩展名不同,Sass 是以“.sass”后缀为扩展名,而 SCSS 是以“.scss”后缀为扩展名
-
语法书写方式不同,Sass 是以严格的缩进式语法规则来书写,不带大括号({})和分号(;),而 SCSS 的语法书写和我们的 CSS 语法书写方式非常类似。
先来看一个示例:
Sass 语法:
$font-stack: Helvetica, sans-serif //定义变量
$primary-color: #333 //定义变量
body
font: 100% $font-stack
color: $primary-colorSCSS 语法:
$font-stark Helvetica, sans-serif;
$primary-color: #333;
body {
font: 100% $font-stack;
color: $primary-color;
}编译出来的 CSS
body {
font: 100% Helvetica, sans-serif;
color: #333;
}由于 SCSS 是 CSS 的扩展,因此,所有在 CSS 中正常工作的代码也能在 SCSS 中正常工作。也就是说,对于一个 Sass 用户,只需要理解 Sass 扩展部分如何工作的,就能完全理解 SCSS。大部分扩展,例如变量、parent references 和 指令都是一致的;唯一不同的是,SCSS 需要使用分号和花括号而不是换行和缩进。 例如,以下这段简单的 Sass 代码:
#sidebar
width: 30%
background-color: #faa只需添加花括号和分号就能转换为 SCSS 语法:
#sidebar {
width: 30%;
background-color: #faa;
}另外,SCSS 对空白符号不敏感。上面的代码也可以书写成下面的样子:
#sidebar {width: 30%; background-color: #faa}1.16.3 sass 的作用
-
变量
$font-stack: Helvetica, sans-serif; $primary-color: #333; body { font: 100% $font-stack; color: $primary-color; } body { font: 100% Helvetica, sans-serif; color: #333; } -
嵌套
nav { ul { margin: 0; padding: 0; list-style: none; } li { display: inline-block; } a { display: block; padding: 6px 12px; text-decoration: none; } } nav ul { margin: 0; padding: 0; list-style: none; } nav li { display: inline-block; } nav a { display: block; padding: 6px 12px; text-decoration: none; } -
模组
// _base.scss $font-stack: Helvetica, sans-serif; $primary-color: #333; body { font: 100% $font-stack; color: $primary-color; } // styles.scss @import 'base'; .inverse { background-color: 'green'; color: white; } body { font: 100% Helvetica, sans-serif; color: #333; } .inverse { background-color: #333; color: white; } -
混合(mixin)
要创建一个mixin,您可以使用
@mixin指令并为其命名。我们将其命名为mixintransform。我们还在$property括号内使用了变量 ,因此我们可以传递任何所需的变换。创建混入之后,您可以将其用作CSS 声明@include,以混入的名称开头。@mixin transform($property) { -webkit-transform: $property; -ms-transform: $property; transform: $property; } .box { @include transform(rotate(30deg)); } .box { -webkit-transform: rotate(30deg); -ms-transform: rotate(30deg); transform: rotate(30deg); } -
操作符 +-*/
.container { width: 100%; } article[role="main"] { float: left; width: 600px / 960px * 100%; } aside[role="complementary"] { float: right; width: 300px / 960px * 100%; }
1.17 iconfont
1.17.1 字体图标的优劣
优势
-
轻量级:一个图标字体要比一系列的图像要小。一旦字体加载了,图标就会马上渲染出来,不需要下载一个个图像。这样可以减少HTTP的请求数量,而且和HTML5的离线存储配合,可以对性能做出优化。
-
灵活性:不调字体可以像页面中的文字一样,通过font-size属性来对其进行大小的设置,而且还可以添加各种文字效果,如color、hover、filter、text-shadow、transform等效果。灵活的简直不像话!
-
兼容性:图标字体支持现代浏览器,甚至是低版本的IE浏览器,所以可以放心的使用它。
-
相比于位图放大图片会出现失真、缩小又会浪费掉像素点,图标字体不会出现这种情况。
劣势
-
图标字体只能被渲染成单色,或者是CSS3的渐变色
-
版权上也有着对应的限制,当然还是有很多免费的图标字体可以供我们下载。
-
当自己创作图标字体的时候,是比较耗费时间的,重构人员的后期维护成本也比较高
1.17.2 字体图标库
Iconfont-阿里巴巴矢量图标库
阿里妈妈MUX倾力打造的矢量图标管理、交流平台。 设计师将图标上传到Iconfont平台,用户可以自定义下载多种格式的icon,平台也可将图标转换为字体,便于前端工程师自由调整与调用。
Icons - Material Design
Google 设计团队出品,用于常见操作和项目。 在桌面上下载,在Android,iOS和Web的数字产品中使用它们。
Ionicons
高级设计的图标,用于Web,iOS,Android和桌面应用程序。 支持SVG和Web字体。 完全开源,MIT由Ionic Framework团队授权和构建。
LivIcons Evolution
真正的动态 SVG 图标。 这是面向 Web 开发人员和网站所有者的产品。 LivIcons Evolution 是经典 LivIcons 包的下一代现代产品,带有交叉浏览器矢量图标,每个都有独立的迷你动画。 它们基于由 JavaScript 驱动的 SVG(可缩放矢量图形),适用于所有现代浏览器,在任何设备上都看起来很完美。 是的,Retina 也是。
Fontello
可以根据您的需求很轻松地制作自定义图标 webfont。
Font Awesome
一套绝佳的图标字体库和 CSS 框架。 Font Awesome为您提供可缩放的矢量图标,您可以使用CSS所提供的所有特性对它们进行更改,包括:大小、颜色、阴影或者其它任何支持的效果。
1.17.3 阿里巴巴矢量图标
创建线上图标库的使用方法
-
选中图标添加购物车
-
点击最右侧购物车图标,创建项目
-
分三种使用方式 unicode 、fontclass、symbol
注意:使用unicode,静态页使用浏览器访问,要+http前缀
阿里图标三种模式
-
unicode 模式
-
它本身和引用外部自定义字体没有区别。只是一个表现出来是图形,另一个是文字。对系统来说,没有区别。
-
引用 iconfont 和引用自定义字体,使用的代码是一样
-
定义字体族
@font-face { font-family: 'iconfont'; /* 自定义字体族名,可以是任意名, */ src: url('//at.alicdn.com/t/font_1357308_kygursq6jw.eot'); /* 字体描述文件链接 */ src: url('//at.alicdn.com/t/font_1357308_kygursq6jw.eot?#iefix') format('embedded-opentype'), /* 兼容 IE9 */ url('//at.alicdn.com/t/font_1357308_kygursq6jw.woff2') format('woff2'), /* 兼容 IE6-IE8 */ url('//at.alicdn.com/t/font_1357308_kygursq6jw.woff') format('woff'), /* 兼容 chrome, firefox, opera, Safari, Android, iOS 4.2+ */ url('//at.alicdn.com/t/font_1357308_kygursq6jw.ttf') format('truetype'), /* 兼容 chrome, firefox, opera, Safari, Android, iOS 4.2+ */ url('//at.alicdn.com/t/font_1357308_kygursq6jw.svg#iconfont') format('svg'); /* 兼容 iOS 4.1及以上 */ } 复制代码-
使用字体族(无论是文本还是icon)
.iconfont { font-family: "iconfont" !important; /*使用自定义字体或者icon*/ /* 上面一句,和我们平时定义「微软雅黑」(font-family: "Microsoft YaHei", sans-serif;)字体是同样的语法 */ /* 只是「微软雅黑」在大部分电脑都会自带有,浏览器能直接找到系统的「微软雅黑」字体描述文件,不需要我们自己定义字体族,不需要使用外部的字体描述文件 */ } 复制代码-
「&#」的意思,「&#」 开头的是HTML实体。所有 html 显示的内容,都可以通过 &# 的形式表述。例如,汉字的HTML实体由三部分组成,
&#(中文对应ASCII码);。例如,把“最新” 转换成“最新” -
为什么中英文能直接显示,不需要使用「&#」形式表示呢?因为中英文有 ASCII 进行自动转义。而 iconfont 不在 ASCII 中定义。是自定义的。
-
iconfont 相当于使用了剩余的 unicode 编码,将自定义的图标描述通过 &# 开头的 HTML 实体的形式表现出来。
-
以「&#」开头的后接十进制数字,以「&#\x」开头的后接十六进制数字
-
-
Font class
-
该模式和 unicode 模式是同样的原理,通过 unicode 编码保存。只是使用方式不同。
-
unicode 是直接将内容写到 innerHTML 中转义,而 font class 则是通过 css 的 :before 伪类,将通过 content 来定义。
-
在 font class 中,「&#\x」被转义符「\」替换,因为「&#\x」是 html 实体字符,只会被 html 解析,不能在 css 中被解析。
-
通过阿里iconfont 给出的 css 链接,在浏览器中直接查看该文件可以看到其定义
-
-
Symbol
-
该模式和上述二者有本质区别,Symbol 模式是通过 svg 技术来描绘图标,没有运用到 unicode 编码
-
即通过不同的 svg 标签来描绘不同的图标。
-
由于使用的是 svg 技术,属于图形,而不仅仅是字符。所以该模式支持彩色图标。
-
通过阿里 iconfont 给出的 js 链接,在浏览器中直接查看该文件可以看到其定义
-
不同文件后缀的含义
-
EOT(Embedded Open Type)是微软创造的字体格式。在 IE 系列的浏览器下使用。
-
SVG(Scalable Vector Graphics (Font))是一种用矢量图格式改进的字体格式。注意这里的 svg 与 symbol 的 svg 是两个概念。前者是 svg 类型的字体描述,后缀是直接描述svg 图形。该模式在 ios 移动端中才支持
-
OTF(OpenType Font)和 TTF(TrueType Font)是 Apple 公司和 Microsoft 公司共同推出的字体文件格式,随着 windows 的流行,已经变成最常用的一种字体文件表示方式。目前主流浏览器都支持该模式。
-
WOFF(Web Open Font Format),WOFF字体通常比其它字体加载的要快些,使用了 OTF 和 TTF 字体里的存储结构和压缩算法。目前主流浏览器都支持该模式
-
其具体兼容性情况,我们可以通过打开 iconfont 的 Font class 链接,通过备注信息得知。
1.18 行内、块级、行内块🌟
行内元素:span
特征:
-
设置宽高无效;
-
对margin仅设置左右方向有效,上下无效,padding设置上下左右都有效;
-
不会自动进行换行;
块级元素:div、h1~h6、ul、li、ol、dl、dt、dd、form
特征:
-
能够识别宽高;
-
margin和padding的上下左右均对其有效;
-
可以自动换行;
-
多个块级标签写在一起,默认排序方式为从上到下1。
行内块元素
特征:
-
不自动换行;
-
能够识别宽高;
-
默认排序方式为从左到右。
1.19 link和@import的区别
-
加载方式:
<link>是 HTML 标签,用于在 HTML 文档的<head>部分链接外部样式表。它允许并行加载 CSS 文件,这意味着浏览器可以同时加载多个 CSS 文件。@import是 CSS 规则,用于在 CSS 文件内部导入其他样式表。它在 CSS 文件中使用,通常位于文件的顶部。@import规则会导致样式表的顺序加载,这意味着浏览器必须先加载包含@import规则的样式表,然后才能加载被导入的样式表。
-
性能:
- 由于
<link>允许并行加载,通常比@import更快,因为它减少了页面加载的总时间。 @import由于是顺序加载,可能会导致页面渲染延迟,因为浏览器必须等待所有导入的样式表加载完成。
- 由于
-
兼容性:
<link>是 HTML 标准的一部分,几乎所有浏览器都支持。@import是 CSS 规则,虽然大多数现代浏览器支持它,但在某些旧浏览器中可能存在兼容性问题。
-
使用场景:
<link>通常用于链接主要的样式表。@import适用于在主样式表中导入较小的、模块化的样式片段,或者用于媒体查询中导入特定媒体类型的样式。
-
媒体类型:
<link>可以通过media属性指定样式表应用的媒体类型。@import也可以指定媒体类型,但通常不如<link>灵活。
-
权重:
- 使用
<link>导入的样式表具有相同的权重。 - 使用
@import导入的样式表可能会有不同的权重,具体取决于它们在主样式表中的位置。
- 使用
总的来说,<link> 通常被认为是更好的选择,因为它提供了更好的性能和更广泛的兼容性。然而,@import 在某些特定的模块化设计中仍然有其用途。
1.20 canvas
`canvas` 是 HTML5 中的一个元素,它允许通过使用 JavaScript 在网页上绘制图形。`canvas` 提供了一个二维绘图 API,可以用来创建复杂的图形、动画、游戏图像、数据可视化等。
以下是一些关于 `canvas` 的基本概念和使用方法:
1.创建 Canvas 元素
在 HTML 中创建一个 `canvas` 元素非常简单:
<canvas id="myCanvas" width="200" height="100" style="border:1px solid #000000;">
</canvas>2. 获取绘图上下文
要在 `canvas` 上绘制,需要获取绘图上下文。通常使用 `2d` 上下文:
var canvas = document.getElementById('myCanvas');
var ctx = canvas.getContext('2d');3. 绘制形状
使用上下文对象可以绘制各种形状,如矩形、圆形、线条等:
// 绘制矩形
ctx.fillStyle = '#FF0000';
ctx.fillRect(0, 0, 150, 75);
// 绘制圆形
ctx.beginPath();
ctx.arc(75, 75, 50, 0, Math.PI * 2, true);
ctx.fillStyle = 'green';
ctx.fill();
ctx.closePath();4. 绘制文本
`canvas` 也可以用来绘制文本:
ctx.font = '20px Arial';
ctx.fillStyle = 'black';
ctx.fillText('Hello, Canvas!', 10, 50);5. 图像操作
可以在 `canvas` 上绘制图像,并对其进行操作,如裁剪、缩放等:
var img = new Image();
img.onload = function() {
ctx.drawImage(img, 0, 0, 150, 100);
}
img.src = 'path/to/image.png';6. 动画
`canvas` 可以用来创建动画,通过清除画布并重新绘制帧来实现:
function drawFrame() {
ctx.clearRect(0, 0, canvas.width, canvas.height);
// 绘制新的帧
requestAnimationFrame(drawFrame);
}
drawFrame();7. 像素操作
`canvas` 允许你获取和操作图像的每个像素,这可以用于图像处理:
var imageData = ctx.getImageData(0, 0, 150, 100);
var data = imageData.data;
// 操作像素数据
ctx.putImageData(imageData, 0, 0);`canvas` 是一个非常强大的工具,可以用于创建复杂的图形和动画。然而,它也有局限性,比如不支持文本搜索和选择,以及复杂的布局和交互。对于这些情况,可能需要使用其他技术,如 SVG 或 HTML/CSS。
1.21 src和href的区别🌟
浏览器会识别href引用的文档并行下载该文档,并且不会停止对当前文档的处理
当浏览器解析到src引用时,会暂停浏览器的渲染,直到该资源加载完毕。这也是将js脚本放在底部而不是头部的原因。
2 JavaScript
2.1 JS基础数据类型🌟

-
七种基本数据类型:number、bigint、string、boolean、null、undefined、symbol
-
一种饮用类型:object
2.2 检测数据类型的方法🌟
-
typeof:可以区分基本数据类型。
语法:
typeof[检测数据]特点:
对于基本类型,除null以外,均可以返回正确的结果;null类型返回object
对于引用类型,除function以外,一律返回object类型;function返回function
-
instanceof:检测数据的原型链上是否有这个属性,可以区分复杂数据类型。
手写instanceof代码:
function myinstanceof(left,right){ let proto = left.__proto__ let prototype = right.prototype while(true){ if(proto = null) return false; if(proto == prototype) return true; proto = proto.__proto__; } } -
constructor:用于引用数据类型,适合使用在引用数据类型上/原型链上不会干扰。检测数据.constructor === class
-
object.prototype.tostring.call()适用于所有类型。
2.3 闭包🌟
定义:在函数作用域创建的变量会因为函数执行结束而销毁,但并非所有都希望销毁,希望每次调用可以改变该变量。
形式:两个函数,父亲函数里面还有一个子函数,子函数内部使用到了父亲函数的变量,子函数将父亲函数里面的变量作为返回值返回。
缺点:内存泄漏、内存溢出
使用场景:
-
缓存:如商品搜索等;
-
实现变量私有化;
-
函数防抖:在事件触发n秒后再执行回调,如果在n秒内又被触发,则重新计算,相当于多次执行,只执行一次;
-
节流。
2.3.1 防抖
经典场景:
(1)输入框实时输入oninput
(2)减少触发输入的频率,提高代码性能
防抖流程:
-
声明一个全局timeID存储定时器id
-
每一次触发事件,先清除上一次定时器,以本次触发为准
-
清除定时器
2.3.2 节流
经典场景:降低高频事件触发频率
(1)鼠标移动:onmousemove
(2)滚动条事件:onscroll
节流流程:
-
声明一个全局变量记录本次触发时间
-
每一次触发事件的事件,获取当前时间
-
判断当前时间-上一次触发时间》=节流间隔
-
存储本次触发时间,用于下一次判断
2.4 作用域和作用域链🌟
作用域:在JavaScript中,作用域分为全局作用域和函数作用域,作用域最大的用处就是隔离变量,不同作用域下同名变量不会有冲突。
-
全局作用域:代码在程序的任何地方都能被访问,window对象的内置属性都拥有全局作用域。
-
函数作用域:在固定的代码片段才能被访问
作用域链:一般情况下,变量取值到创建这个变量的函数的作用域中取值。但是如果当前作用域中没有查到值,就会向上级作用域去查,直到查到全局作用域,这个查找过程形成的链条就叫做作用域链
2.4.1 作用域
作用域是指在程序中定义变量的区域,该位置决定了变量的生命周期。通俗地理解,作用域就是变量与函数的可访问范围,即作用域控制着变量和函数的可见性和生命周期。
在 ES6 之前,ES 的作用域只有两种:全局作用域和函数作用域。
-
全局作用域中的对象在代码中的任何地方都能访问,其生命周期伴随着页面的生命周期。
-
函数作用域就是在函数内部定义的变量或者函数,并且定义的变量或者函数只能在函数内部被访问。函数执行结束之后,函数内部定义的变量会被销毁。
ES6支持块级作用域
-
块级作用域特点:在代码块内部定义的变量在代码块外部是访问不到的,并且等该代码块中的代码执行完成之后,代码块中定义的变量会被销毁。
-
块级作用域形式:就是使用一对大括号包裹的一段代码,比如函数、判断语句、循环语句,甚至单独的一个{}都可以被看作是一个块级作用域。
//if块 if(1){} //while块 while(1){} //函数块 function foo(){} //for循环块 for(let i = 0; i<100; i++){} //单独一个块 {} -
ES6中如何使块级作用域生效:使用let和const关键字
for(var i = 0; i<100; i++){ } console.log(i) for(let i = 0; i<100; i++){ } console.log(i)引申考题:隔一秒钟打印出来一个自然数,自然数递增
for(let i = 0; i<10; i++){ setTimeout(function(){ console.log(i) },1000*i) } for(var i = 0; i<10; i++){ setTimeout(function(){ console.log(i) },1000*i) }
let、const关键字解决var关键字变量提升的问题
-
由于变量提升,变量值容易被覆盖
var myname = "王美丽" function showName(){ console.log(myname); if(0){ var myname = "闷倒驴" } console.log(myname); } showName() -
本该销毁的变量销毁不掉
for(var i = 0; i<100; i++){ } console.log(i)
let、const关键字解决问题的原理
-
let和const关键字创建的变量存储在词法环境中,var关键字创建的变量存储在变量环境中
-
块级内部代码执行结束,立马销毁内部let、const创建的变量
-
let和const创建的变量,初始化不提升,创建提升,所以造成暂时性死区
-
访问变量先在当前执行上下文的词法环境中查找,再到变量环境中查找
function fun(){ var a = 11; let b = 22; { let b = 33; var c = 44; let d = 55; console.log(a); console.log(b); } console.log(b); console.log(c); console.log(d); } fun()第一步:刚开始执行fun函数
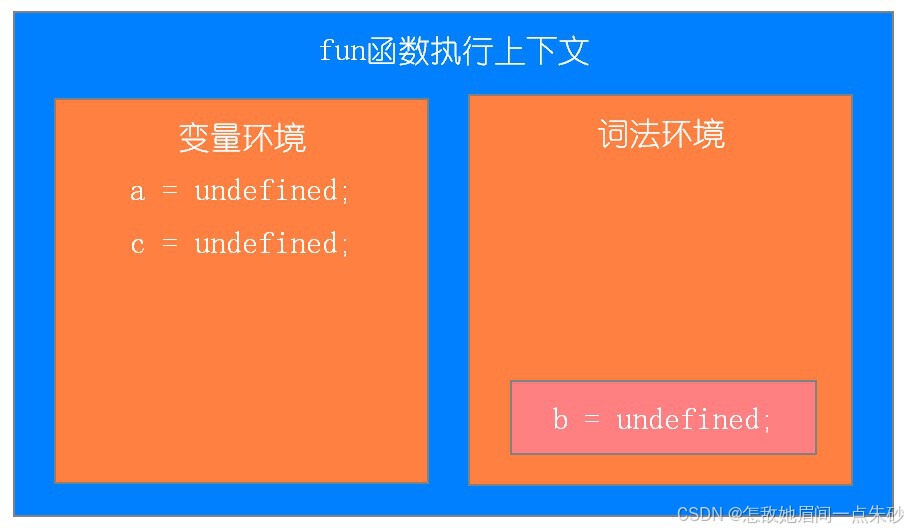
第二步:执行内部代码块

第三步:执行代码块中console.log(a) console.log(b)
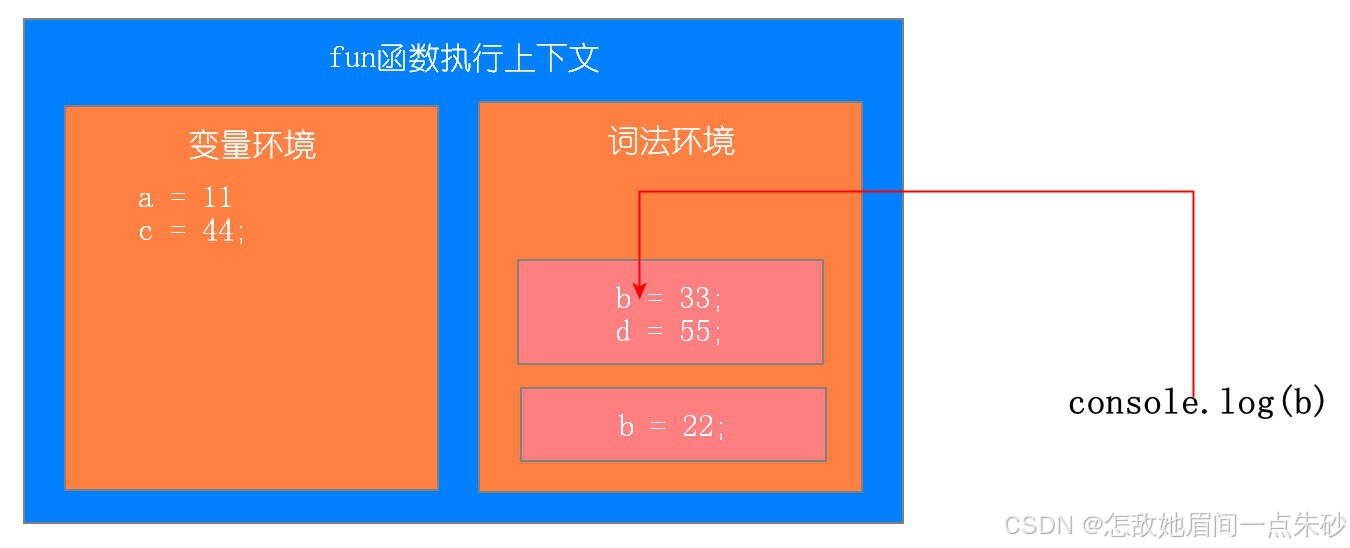
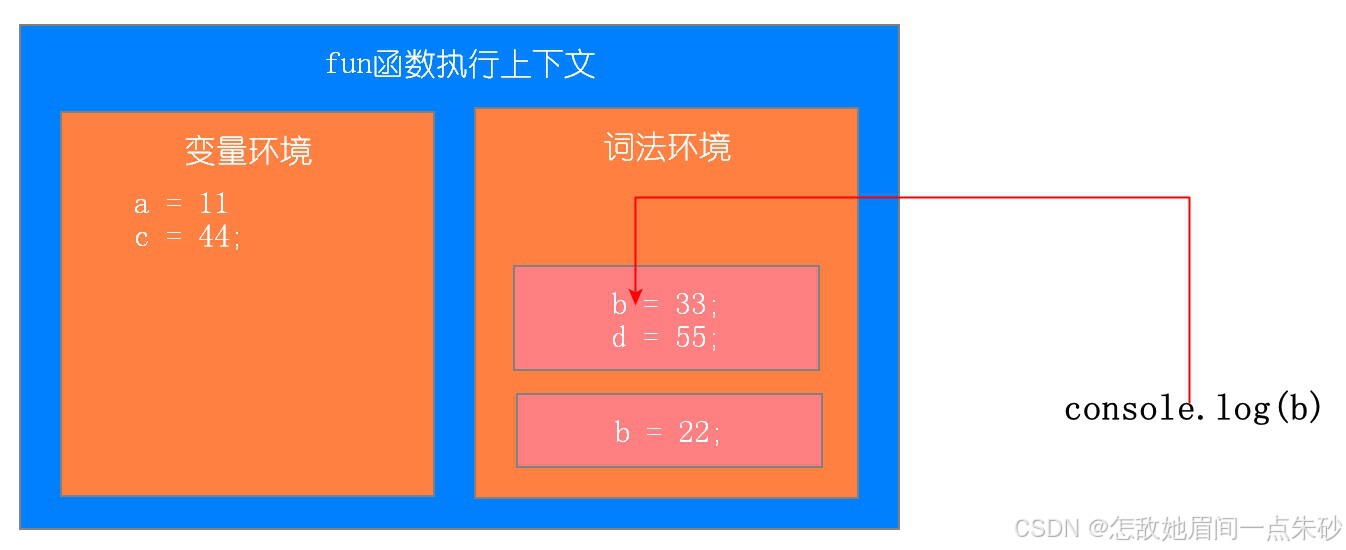

第四步:代码块执行结束,相应词法环境中的变量弹出
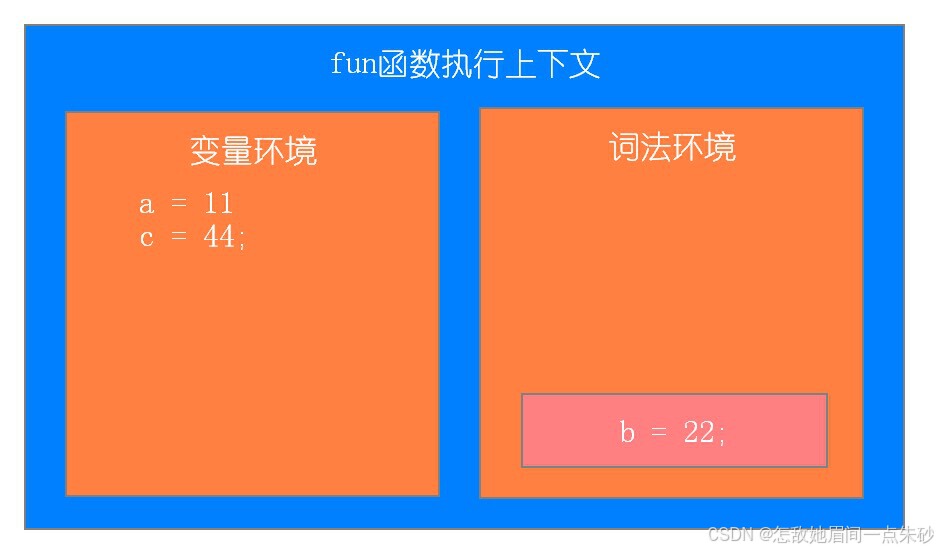
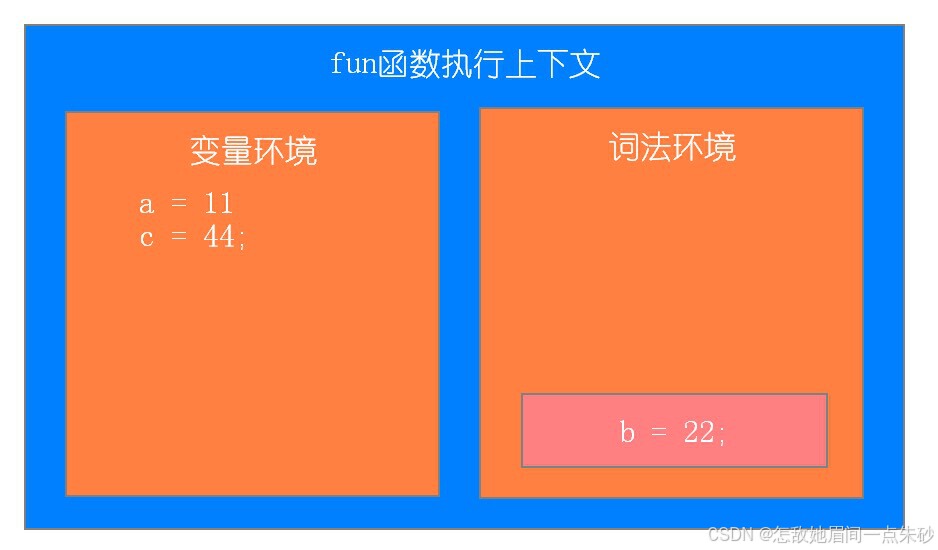
第五步:执行console.log(b);console.log(c);
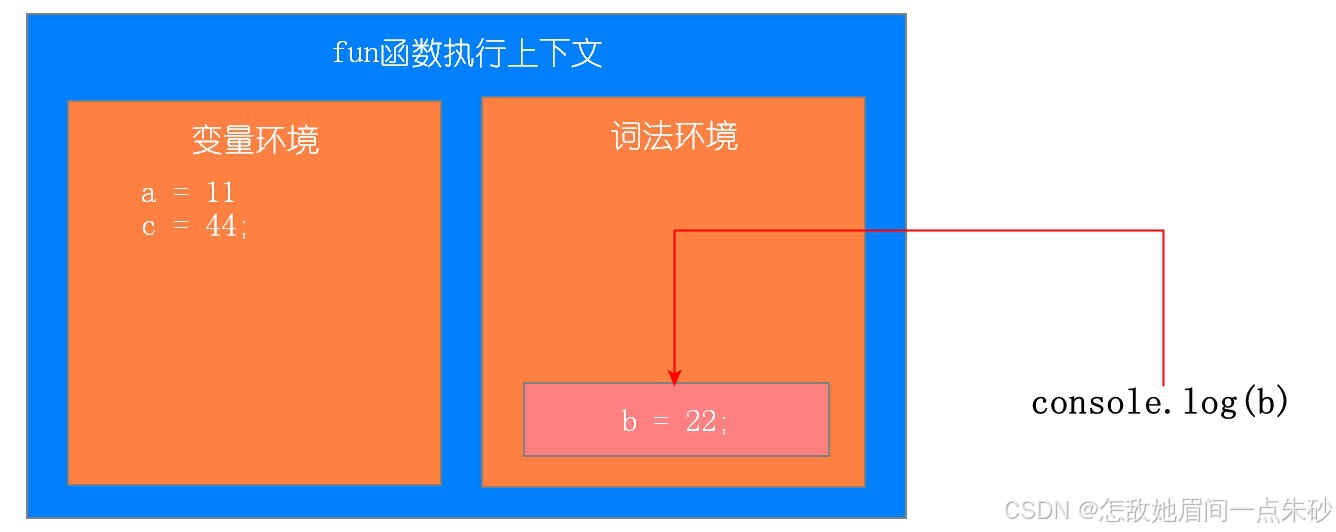
第六步:执行console.log(d),找不到报错
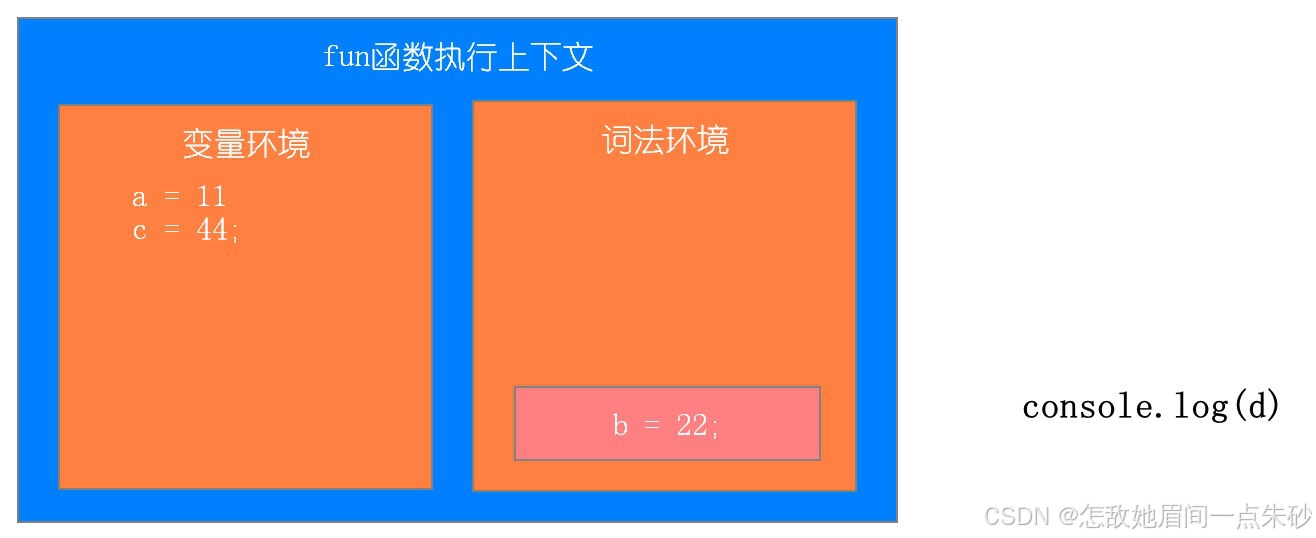
关于变量提升问题
-
var的创建和初始化被提升,赋值不会被提升。
-
let的创建被提升,初始化和赋值不会被提升,所以会造成暂时性死区(就是访问不到)。
-
function的创建、初始化和赋值均会被提升。
作用域的特点:是代码编译阶段就决定好的,和函数是怎么调用的没有关系。
function bar() {
var myName = "王美丽";
let test1 = 100;
if (1) {
let myName = "丑八怪";
console.log(test);
}
}
function foo() {
var myName = "闷倒驴";
let test = 2;
{
let test = 3;
bar();
}
};
var myName = "大喇叭";
let myAge = 10;
let test =1;
foo();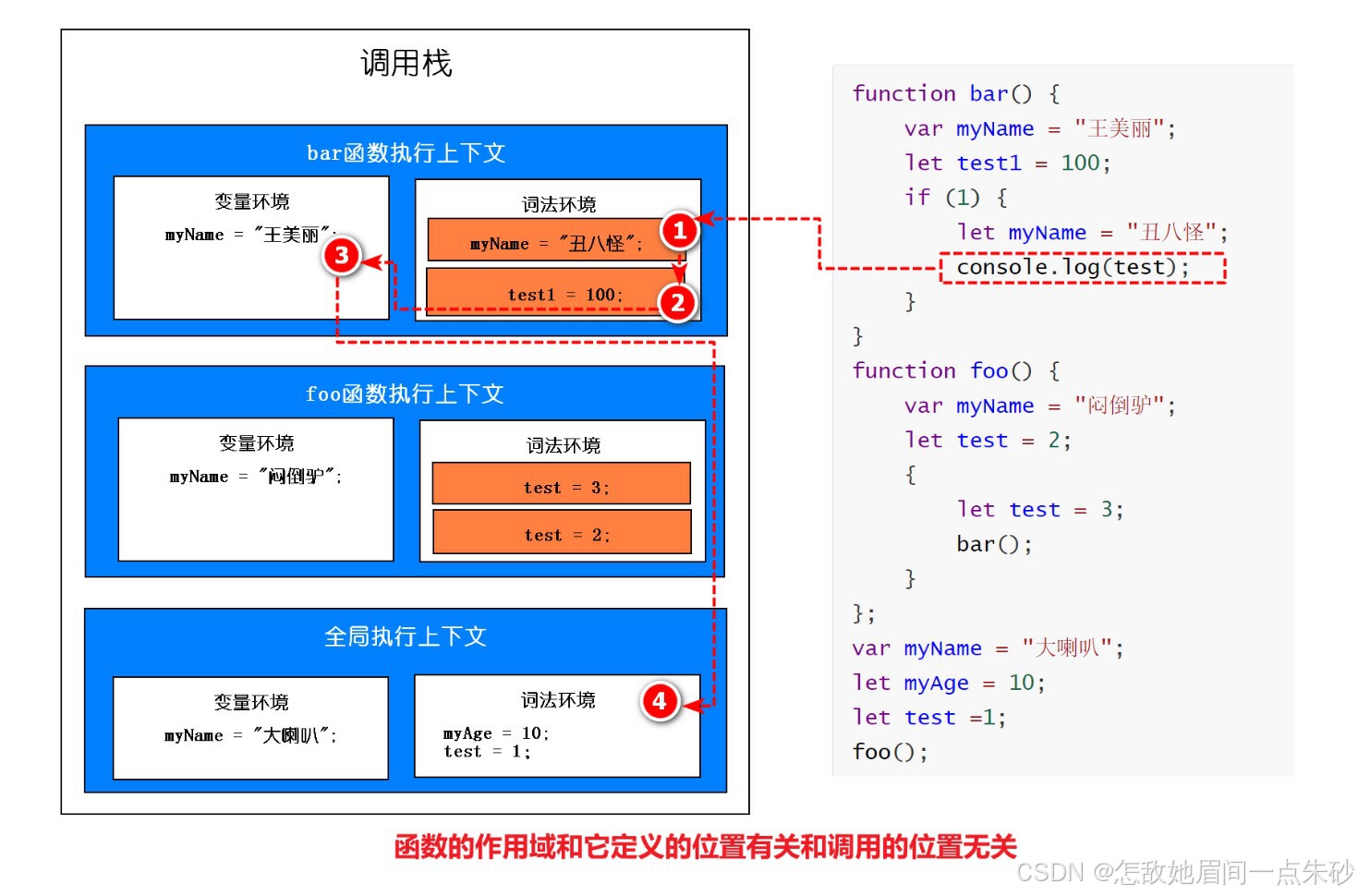
2.4.2 作用域链
作用域链:当一个函数中使用了某个变量,首先会在自己内部作用域查找,然后再向外部一层一层查找,直到全局作用域,这个链式查找就是作用域链
let num = 1;
function fun1 (){
function fun2(){
function fun3(){
console.log(num);
}
fun3()
}
fun2()
}
fun1();
2.4.3 闭包
1 什么是闭包
function foo() {
var myName = "王美丽";
let test1 = 1;
const test2 = 2;
var innerBar = {
getName:function(){ console.log(test1) return myName },
setName:function(newName){ myName = newName }
}
return innerBar
}
var bar = foo();
bar.setName("闷倒驴");
bar.getName();
console.log(bar.getName())
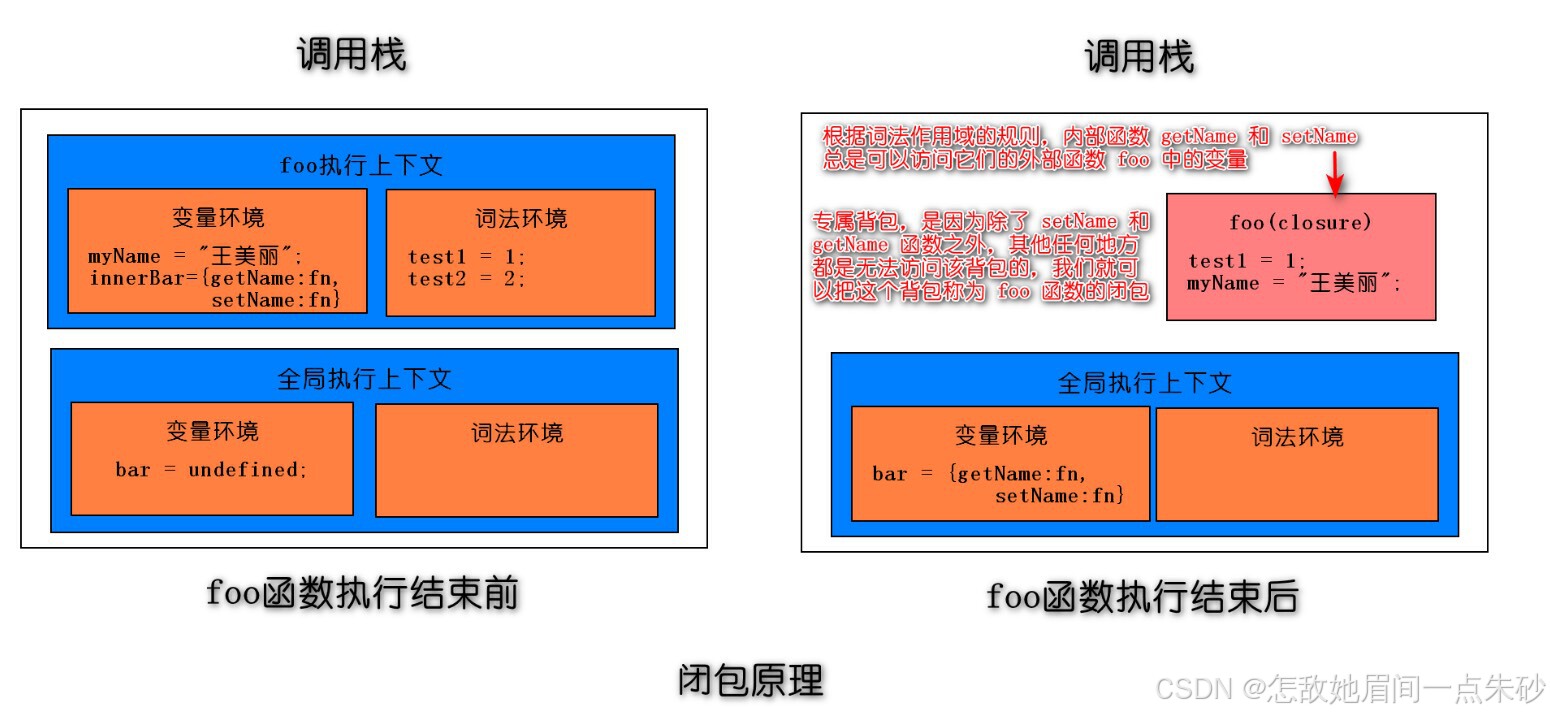
2 闭包形成的原理
-
作用域链,当前作用域可以访问上级作用域中的变量
-
全局变量只用页面关闭才会销毁
3 闭包解决的问题
-
函数作用域中的变量在函数执行结束就会销毁,但是有时候我们并不希望变量销毁
-
在函数外部可以访问函数内部的变量
4 闭包带来的问题
-
容易造成内存泄露
-
内存泄漏:占用的内存没有及时释放,内存泄露积累多了就容易导致内存溢出
-
闭包
function fn1() { var a = 4 function fn2() { console.log(++a) } return fn2 } var f = fn1() f()
-
-
5 闭包的应用
-
模仿块级作用域
for(var i = 0; i < 5; i++) { (function(j){ setTimeout(() => { console.log(j); }, j * 1000); })(i) } for (var i = 0; i < lis.length; i++) { (function (j) { lis[j].onclick = function () { alert(j) } })(i) }埋点计数器
function count () { var num = 0; return function(){ num++; return num; } } var num = count(); -
柯里化
function curryingCheck(reg) { return function (txt) { return reg.test(txt) } } var isPhone = curryingCheck(/^(13[0-9]|14[5|7]|15[0|1|2|3|4|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$/) console.log(isPhone('15810606459')) // true var isEmail = curryingCheck(/^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$/) console.log(isEmail('wyn@nowcoder.com')) // false
2.5 内存空间
2.5.1 内存空间分配
JavaScript 中主要有三种类型内存空间,分别是代码空间、栈空间和堆空间。
代码空间主要是存储可执行代码
2.5.2 栈和堆空间
function foo(){
var a = "闷倒驴";
var b = a;
var c = {name:"王美丽"};
var d = c;
}
foo()为什么不能把存储在堆中的数据存储在栈中?
因为 JavaScript 引擎需要用栈来维护程序执行期间上下文的状态,如果栈空间大了话,所有的数据都存放在栈空间里面,那么会影响到上下文切换的效率,进而又影响到整个程序的执行效率。
堆栈特点
-
栈空间都不会设置太大,主要用来存放一些原始类型的小数据。而引用类型的数据占用的空间都比较大,所以这一类数据会被存放到堆中,堆空间很大,能存放很多大的数据,不过缺点是分配内存和回收内存都会占用一定的时间
-
原始类型的赋值会完整复制变量值,而引用类型的赋值是复制引用地址
2.5.3 引用类型的深浅拷贝
赋值:简单数据类型直接在栈中开辟一块新的内存,存储赋值的数据;引用数据类型,在栈中开辟一块空间,存储赋值的数据对应的堆中的存储地址,源数据和拷贝的新数据对应的是同一块堆空间中的数据
都是针对复杂数据类型,简单数据类型没有深浅拷贝。
浅拷贝:浅拷贝复制的是对象的引用地址,没有开辟新的栈,复制的结果是两个对象指向同一个地址,所以修改其中一个对象的属性,另一个对象的属性也跟着改变了。【默认情况下引用数据类型都是浅拷贝】
深拷贝:深拷贝会开辟新的栈,两个对象对应两个不同的地址,修改对象A的属性,并不会影响到对象B。【默认情况下基本数据类型(number、string、null、undefined、boolean)都是深拷贝。】
赋值例子:
var user = {userName:'闷倒驴',sex:'女',body:{weight:'50kg',height:'160'}}
// 赋值
var userCopy = user;
user.sex = '男';
user.body.weight = '100斤';浅拷贝例子:
var user = {userName:'闷倒驴',sex:'女',body:{weight:'50kg',height:'160'}}
// 浅拷贝
var userCopy = Object.assign({}, user);
user.sex = '男';
user.body.weight = '100斤';当执行完userCopy浅拷贝之后,内存空间如图所示:
执行完 user.sex = '男'; user.body.weight = '100斤'; 之后,如下图所示
深拷贝例子:
var user = { userName: '闷倒驴', sex: '女', body: { weight: '50kg', height: '160' } }
// 深拷贝
var userCopy = JSON.parse(JSON.stringify(user));
user.sex = '男';
user.body.weight = '100斤';当执行完userCopy深拷贝之后,内存空间如图所示:
当执行完userCopy深拷贝之后,内存空间如图所示:
浅拷贝方法
1.Object.assign()
Object.assign() 方法可以把任意多个的源对象自身的可枚举属性拷贝给目标对象,然后返回目标对象。
let obj1 = { person: {name: "kobe", age: 41},sports:'basketball' };
let obj2 = Object.assign({}, obj1);
obj2.person.name = "wade";
obj2.sports = 'football'
console.log(obj1); // { person: { name: 'wade', age: 41 }, sports: 'basketball' }2.函数库lodash的_.clone方法
该函数库也有提供_.clone用来做 Shallow Copy,后面我们会再介绍利用这个库实现深拷贝。
var _ = require('lodash');
var obj1 = {
a: 1,
b: { f: { g: 1 } },
c: [1, 2, 3]
};
var obj2 = _.clone(obj1);
console.log(obj1.b.f === obj2.b.f);// true3.展开运算符...
展开运算符是一个 es6 / es2015特性,它提供了一种非常方便的方式来执行浅拷贝,这与 Object.assign ()的功能相同。
let obj1 = { name: '王美丽', address: { x: 100, y: 100 } }
let obj2 = { ...obj1 }
obj1.address.x = 200;
obj1.name = '闷倒驴'
console.log('obj2', obj2) // obj2 { name: 'Kobe', address: { x: 200, y: 100 } }4.Array.prototype.concat()
let arr = [1, 3, {
username: '王美丽'
}];
let arr2 = arr.concat();
arr2[2].username = '闷倒驴';
console.log(arr); //[ 1, 3, { username: '闷倒驴' } ]5.Array.prototype.slice()
let arr = [1, 3, {
username: ' 王美丽'
}];
let arr3 = arr.slice();
arr3[2].username = '闷倒驴'
console.log(arr); // [ 1, 3, { username: '闷倒驴' } ]深拷贝方法
1.JSON.parse(JSON.stringify())
let arr = [1, 3, {
username: '闷倒驴'
}];
let arr1 = JSON.parse(JSON.stringify(arr));
arr1[2].username = '王美丽';
console.log(arr, arr1)这也是利用JSON.stringify将对象转成JSON字符串,再用JSON.parse把字符串解析成对象,一去一来,新的对象产生了,而且对象会开辟新的栈,实现深拷贝。
这种方法虽然可以实现数组或对象深拷贝,但不能处理函数和正则,因为这两者基于JSON.stringify和JSON.parse处理后,得到的正则就不再是正则(变为空对象),得到的函数就不再是函数(变为null)了。
比如下面的例子:
let arr = [1, 3, {
username: '闷倒驴'
},function(){}];
let arr1 = JSON.parse(JSON.stringify(arr));
arr1[2].username = '王美丽';
console.log(arr, arr1)object.assign()
let A={
blog:'juejin',
author:'Axjy',
C:{
book:'vivi'
}
}
let B=Object.assign({},A)2.函数库lodash的_.cloneDeep方法
该函数库也有提供_.cloneDeep用来做 Deep Copy
var _ = require('lodash');
var obj1 = {
a: 1,
b: { f: { g: 1 } },
c: [1, 2, 3]
};
var obj2 = _.cloneDeep(obj1);
console.log(obj1.b.f === obj2.b.f);// false3.jQuery.extend()方法
jquery 有提供一個$.extend可以用来做 Deep Copy
// $.extend(deepCopy, target, object1, [objectN])//第一个参数为true,就是深拷贝
var $ = require('jquery');
var obj1 = {
a: 1,
b: { f: { g: 1 } },
c: [1, 2, 3]
};
var obj2 = $.extend(true, {}, obj1);
console.log(obj1.b.f === obj2.b.f); // false4.手写递归方法
使用递归
//判断数据类型
function getDataType(data){
return Object.prototype.toString.call(data).slice(8,-1)
}
//拷贝数据
const deepClone = function(data){
if(data===null||data===undefined){
return undefined
}
const dataType = getDataType(data)
if(dataType==='Date'){
let cloneDate = new Date();
cloneDate.setTime(data.getTime())
return cloneDate
}
if(dataType==='Object'){
let copiedObject=[]
for(let key in data){
copiedObject[key]=deepClone(data[key])
}
return copiedObject
}
if(dataType==='Array'){
let copiedArray=[]
for(var i=0;i<data.length;i++){
copiedObject.push(deepClone(data[i]))
}
return copiedArray
}
}递归方法实现深度克隆原理:遍历对象、数组直到里边都是基本数据类型,然后再去复制,就是深度拷贝。
有种特殊情况需注意就是对象存在循环引用的情况,即对象的属性直接的引用了自身的情况,解决循环引用问题,我们可以额外开辟一个存储空间,来存储当前对象和拷贝对象的对应关系,当需要拷贝当前对象时,先去存储空间中找,有没有拷贝过这个对象,如果有的话直接返回,如果没有的话继续拷贝,这样就巧妙化解的循环引用的问题。
function deepClone(obj, hash = new WeakMap()) {
if (obj === null) return obj; // 如果是null或者undefined我就不进行拷贝操作
if (obj instanceof Date) return new Date(obj);
if (obj instanceof RegExp) return new RegExp(obj);
// 可能是对象或者普通的值 如果是函数的话是不需要深拷贝
if (typeof obj !== "object") return obj;
// 是对象的话就要进行深拷贝,遇到循环引用,将引用存储起来,如果存在就不再拷贝
if (hash.get(obj)) return hash.get(obj);
let cloneObj = new obj.constructor();
// 找到的是所属类原型上的constructor,而原型上的 constructor指向的是当前类本身
hash.set(obj, cloneObj);
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
// 实现一个递归拷贝
cloneObj[key] = deepClone(obj[key], hash);
}
}
return cloneObj;
}
let obj = { name: 1, address: { x: 100 } };
obj.o = obj; // 对象存在循环引用的情况
let d = deepClone(obj);
obj.address.x = 200;
console.log(d);循环引用:
当对象 1 中的某个属性指向对象 2,对象 2 中的某个属性指向对象 1 就会出现循环引用,(当然不止这一种情况,不过原理是一样的)
2.6 JavaScript垃圾回收机制
C语言是手动垃圾回收,JavaScript是自动垃圾回收
2.6.1 栈中的垃圾回收方式
当一个函数执行结束之后,JavaScript引擎会通过向下移动esp来销毁该函数保存在栈中的执行上下文
function foo(){
var a = 1;
var b = {name:"王美丽"};
function showName(){
var c = 2;
var d = {name:"闷倒驴"};
};
showName()
};
foo()2.6.2 堆中的垃圾回收方式
当函数直接结束,栈空间处理完成了,但是堆空间的数据虽然没有引用,但是还是存储在堆空间中,需要垃圾回收器将堆空间中的垃圾数据回收。
1 代际假说
代际假说有以下两个特点:
-
第一个是大部分对象在内存中存在的时间很短,简单来说,就是很多对象一经分配内存,很快就变得不可访问;
-
第二个是不死的对象,会活得更久。
2 分代收集
为了使垃圾回收达到更好的效果,根据对象的生命周期不一样,使用不同的垃圾回收的算法
在 V8 中会把堆分为新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放的生存时间久的对象
新生区通常只支持 1~8M 的容量,而老生区支持的容量就大很多了。对于这两块区域,V8 分别使用两个不同的垃圾回收器,以便更高效地实施垃圾回收。
副垃圾回收器,主要负责新生代的垃圾回收。
主垃圾回收器,主要负责老生代的垃圾回收。
3 垃圾回收器的工作流程
第一步是标记空间中活动对象和非活动对象。所谓活动对象就是还在使用的对象,非活动对象就是可以进行垃圾回收的对象。
第二步是回收非活动对象所占据的内存。其实就是在所有的标记完成之后,统一清理内存中所有被标记为可回收的对象。
第三步是做内存整理。一般来说,频繁回收对象后,内存中就会存在大量不连续空间,我们把这些不连续的内存空间称为内存碎片。当内存中出现了大量的内存碎片之后,如果需要分配较大连续内存的时候,就有可能出现内存不足的情况。所以最后一步需要整理这些内存碎片,但这步其实是可选的,因为有的垃圾回收器不会产生内存碎片,比如接下来我们要介绍的副垃圾回收器。
4 新生区垃圾回收(副垃圾回收器)
新生区特点:
-
通常把小的对象分配到新生区
-
新生区的垃圾回收比较频繁
-
通常存储容量在1-8M
-
Scavenge算法采用复制机制,如果存储容量过大,会导致每次清理的时间过长,效率低
-
同时因为存储容量小,很容易就写满,所以经过两次垃圾回收依然还存活的对象,会被移动到老生区中
这个策略称为对象晋升策略
-
-
新生代中用 Scavenge 算法来处理垃圾回收
Scavenge算法:将新生区分成两部分,一部分叫对象区域,一部分叫空闲区域,新加入的对象先存放在对象区域,当对象区域写满,进行垃圾回收,具体回收步骤
-
标记:对对象区域中的垃圾进行标记
-
清除垃圾数据和整理碎片化内存:副垃圾回收器会把这些存活的对象复制到空闲区域中,并且有序的排列起来,复制后空闲区域就没有内存碎片了
-
角色翻转:完成复制后,对象区域与空闲区域进行角色翻转,也就是原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域,这样就完成了垃圾对象的回收操作,同时这种角色翻转的操作还能让新生代中的这两块区域无限重复使用下去
5 老生区垃圾回收(主垃圾回收器)
老生区的特点:
-
对象占用空间大
-
对象存活时间长
垃圾回收的过程: 之前使用标记-清除算法,由于会产生碎片化空间,于是又添加标记-整理算法
-
标记-清除算法
-
标记:标记阶段就是从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素称为活动对象,没有到达的元素就可以判断为垃圾数据。
-
清除:将垃圾数据进行清除。
-
碎片: 对一块内存多次执行标记 - 清除算法后,会产生大量不连续的内存碎片。而碎片过多会导致大对象无法分配到足够的连续内存。
-
-
标记-整理算法(如图会产生大量的碎片化空间,没有连续的大存储空间,如果此时要存入一个大对象,就存储不了)
-
标记:和标记 - 清除的标记过程一样,从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素标记为活动对象。
-
整理:让所有存活的对象都向内存的一端移动
-
清除:清理掉端边界以外的内存
-
6 全停顿
V8 是使用副垃圾回收器和主垃圾回收器处理垃圾回收的,不过由于 JavaScript 是运行在主线程之上的,一旦执行垃圾回收算法,都需要将正在执行的 JavaScript 脚本暂停下来,待垃圾回收完毕后再恢复脚本执行。我们把这种行为叫做全停顿(Stop-The-World)。
为了降低老生代的垃圾回收而造成的卡顿,V8 将标记过程分为一个个的子标记过程,同时让垃圾回收标记和 JavaScript 应用逻辑交替进行,直到标记阶段完成,我们把这个算法称为增量标记(Incremental Marking)算法
2.6.3 避免内存泄漏的方式
-
内存溢出:就是你要求分配的内存超出了系统能给你的,系统不能满足需求,于是产生溢出。
-
内存泄漏:是指你向系统申请分配内存进行使用(new),可是使用完了以后却不归还(delete),结果你申请到的那块内存你自己也不能再访问,而系统也不能再次将它分配给需要的程序。就是产生了不可回收的垃圾数据
1 尽可能少地创建全局变量
在ES5中以var声明的方式在全局作用域中创建一个变量时,或者在函数作用域中不以任何声明的方式创建一个变量时,都会无形地挂载到window全局对象上,如下所示:
var num = 1; // 等价于 window.num = 1;
function fun() {
num = 1;
}等价于
function fun() {
window.num = 1;
}我们在fun函数中创建了一个变量num但是忘记使用var来声明,此时会意想不到地创建一个全局变量并挂载到window对象上,另外还有一种比较隐蔽的方式来创建全局变量:
function fun() {
this.num = 1;
}
fun(); // 相当于 window.fun()当foo函数在调用时,它所指向的运行上下文环境为window全局对象,因此函数中的this指向的其实是window,也就无意创建了一个全局变量。当进行垃圾回收时,在标记阶段因为window对象可以作为根节点,在window上挂载的属性均可以被访问到,并将其标记为活动的从而常驻内存,因此也就不会被垃圾回收,只有在整个进程退出时全局作用域才会被销毁。如果你遇到需要必须使用全局变量的场景,那么请保证一定要在全局变量使用完毕后将其设置为null从而触发回收机制。
2 手动清除定时器
在我们的应用中经常会有使用setTimeout或者setInterval等定时器的场景,定时器本身是一个非常有用的功能,但是如果我们稍不注意,忘记在适当的时间手动清除定时器,那么很有可能就会导致内存泄漏,示例如下:
var numbers = [];
var fun = function() {
for(let i = 0;i < 100;i++) {
numbers.push(i);
}
};
window.setInterval(fun, 1000);在这个示例中,由于我们没有手动清除定时器,导致回调任务会不断地执行下去,回调中所引用的numbers变量也不会被垃圾回收,最终导致numbers数组长度无限递增,从而引发内存泄漏。
3 少用闭包
闭包是JS中的一个高级特性,巧妙地利用闭包可以帮助我们实现很多高级功能。一般来说,我们在查找变量时,在本地作用域中查找不到就会沿着作用域链从内向外单向查找,但是闭包的特性可以让我们在外部作用域访问内部作用域中的变量,示例如下:
function foo() {
let local = 123;
return function() {
return local;
}
}
const bar = foo();
console.log(bar()); // -> 123在这个示例中,foo函数执行完毕后会返回一个匿名函数,该函数内部引用了foo函数中的局部变量local,并且通过变量bar来引用这个匿名的函数定义,通过这种闭包的方式我们就可以在foo函数的外部作用域中访问到它的局部变量local。一般情况下,当foo函数执行完毕后,它的作用域会被销毁,但是由于存在变量引用其返回的匿名函数,导致作用域无法得到释放,也就导致local变量无法回收,只有当我们取消掉对匿名函数的引用才会进入垃圾回收阶段。
4 清除DOM引用
以往我们在操作DOM元素时,为了避免多次获取DOM元素,我们会将DOM元素存储在一个数据字典中,示例如下:
const elements = {
button: document.getElementById('button')
};
function removeButton() {
document.body.removeChild(document.getElementById('button'));
}在这个示例中,我们想调用removeButton方法来清除button元素,但是由于在elements字典中存在对button元素的引用,所以即使我们通过removeChild方法移除了button元素,它其实还是依旧存储在内存中无法得到释放,只有我们手动清除对button元素的引用才会被垃圾回收。
5 弱引用
在ES6中新增了两个有效的数据结构WeakMap和WeakSet,就是为了解决内存泄漏的问题而诞生的。其表示弱引用,它的键名可以是对象,同时引用的对象均是弱引用,弱引用是指垃圾回收的过程中不会将键名对该对象的引用考虑进去,只要所引用的对象没有其他的引用了,垃圾回收机制就会释放该对象所占用的内存。
var map = new Map();
{
let x = {}
map.set(x, 'something');
}
console.log(map);
var map = new WeakMap();
{
let x = {}
map.set(x, 'something');
}
console.log(map);2.7 变量提升🌟
在当前上下文中(全局/私有/块级),js代码自上而下执行之前,浏览器会提前处理一些事情把文中所有带var、function关键字的进行提前的声明或者定义。
2.7.1 执行前编译
-
当 JavaScript 执行全局代码的时候,会编译全局代码并创建全局执行上下文,而且在整个页面的生存周期内,全局执行上下文只有一份。
-
当调用一个函数的时候,函数体内的代码会被编译,并创建函数执行上下文,一般情况下,函数执行结束之后,创建的函数执行上下文会被销毁。
-
当使用 eval 函数的时候,eval 的代码也会被编译,并创建执行上下文。
2.7.2 调用栈
JavaScript 中有很多函数,经常会出现在一个函数中调用另外一个函数的情况,调用栈就是用来管理函数调用关系的一种数据结构。
调用栈特点:后进先出
JavaScript 引擎会将执行上下文压入栈中,通常把这种用来管理执行上下文的栈称为执行上下文栈,又称调用栈
var a = 1;
function sum(b,c){
return b+c
};
function addSum(d,e){
var f = 10;
result = add(d,e);
return a+result+f
};
addSum(3,6)第一步:创建全局上下文,并将其压入栈底,执行a = 1;
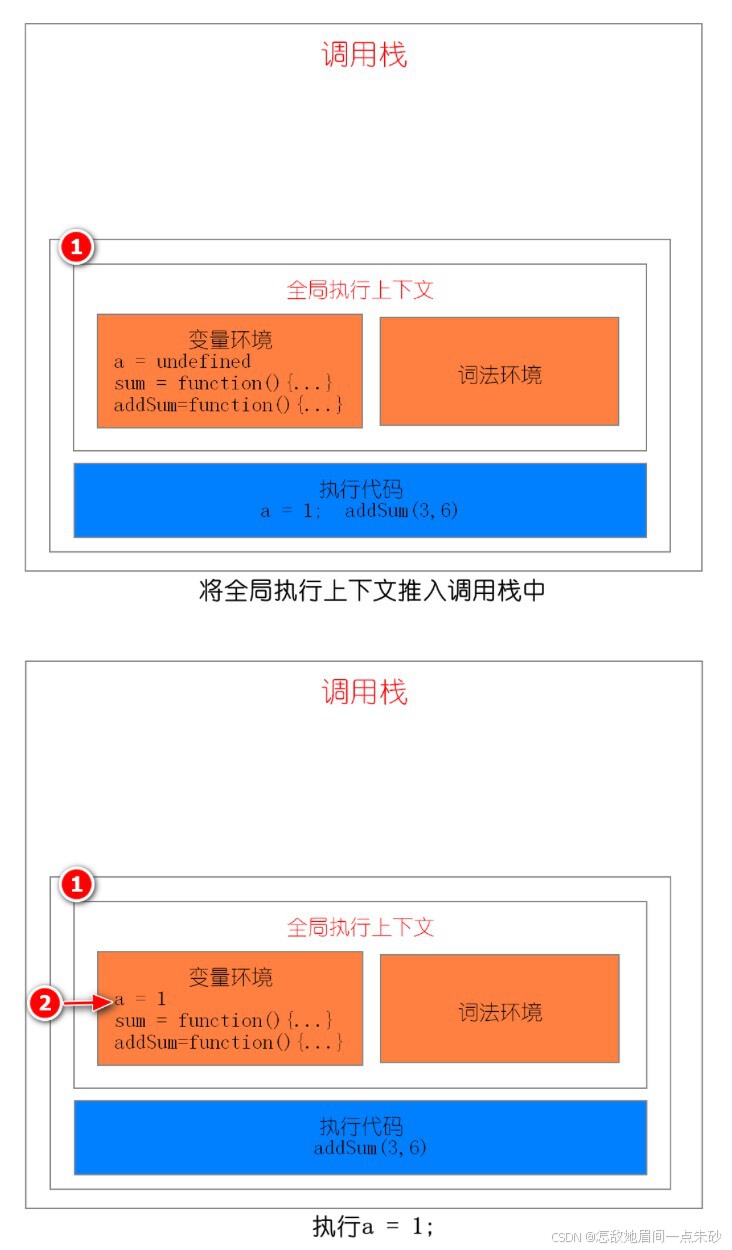
第二步:调用addSum函数,JavaScript 引擎会编译该函数,并为其创建一个执行上下文,最后还将该函数的执行上下文压入栈中。
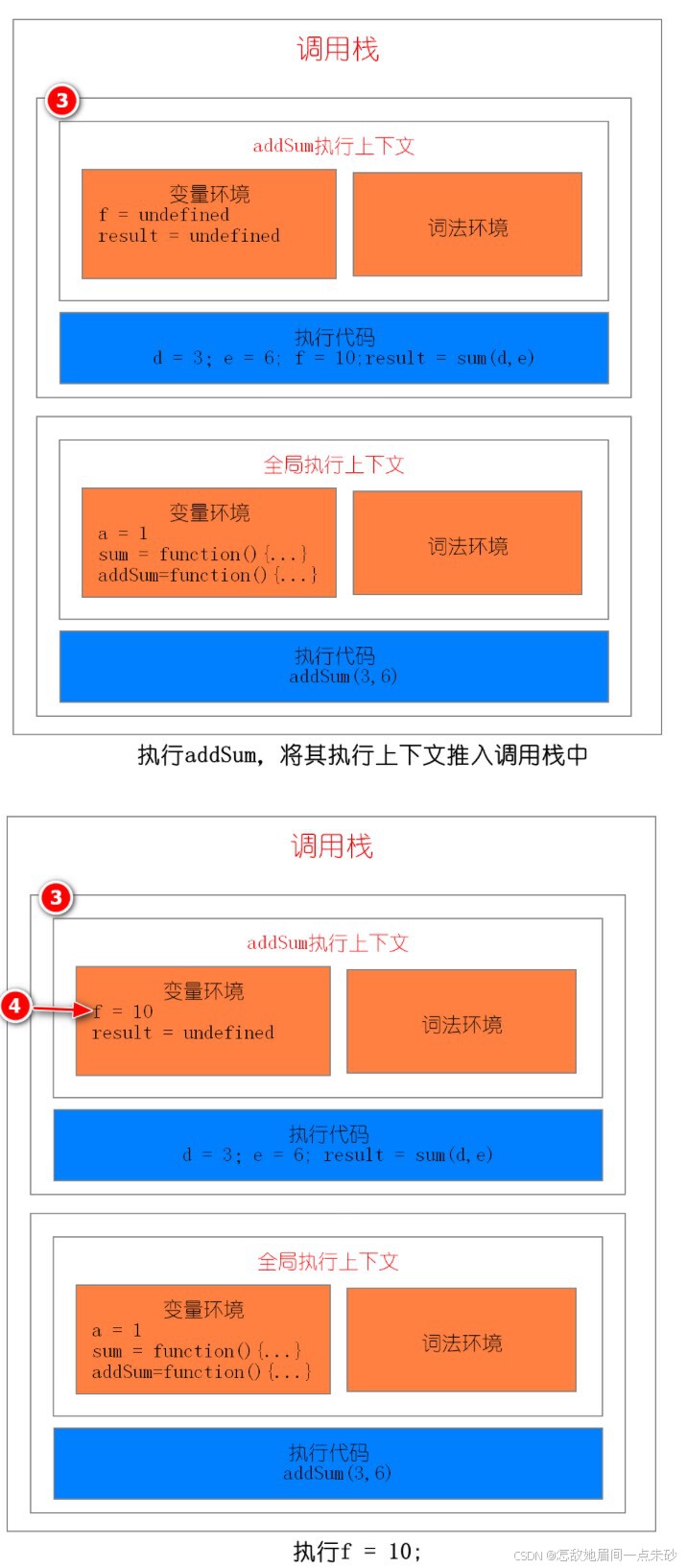
第三步:当执行到 add 函数调用语句时,同样会为其创建执行上下文,并将其压入调用栈
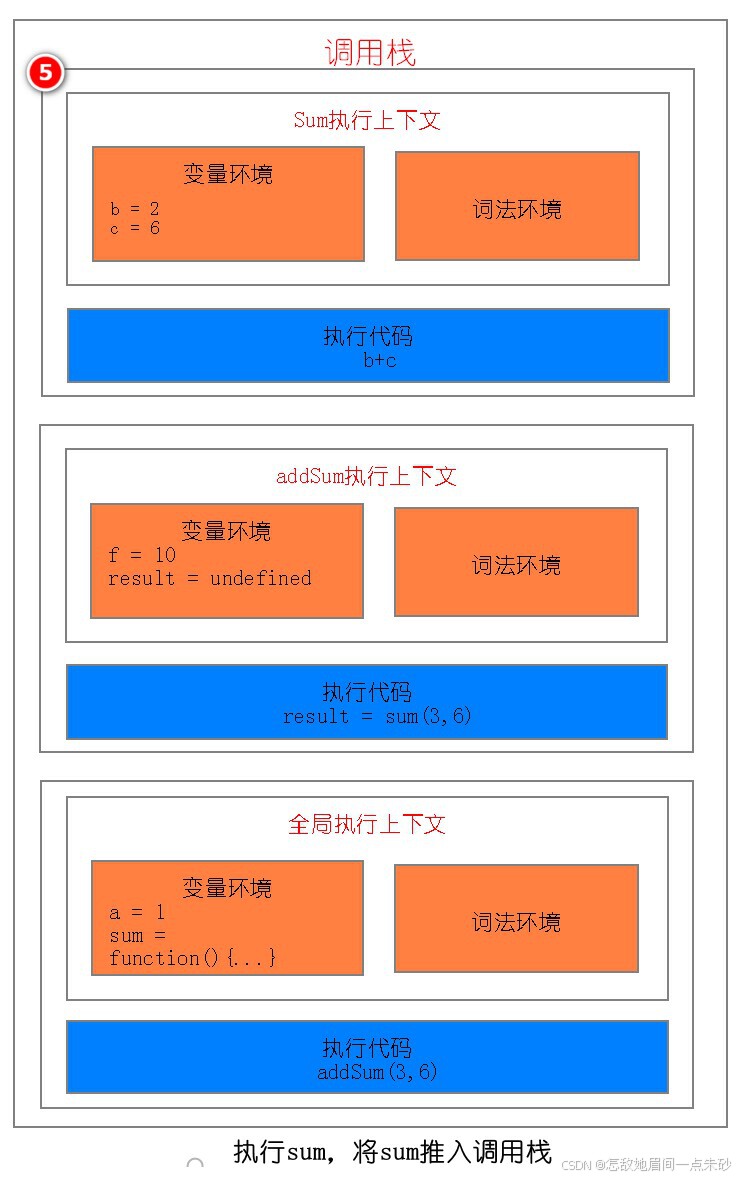
第四步:当 add 函数返回时,该函数的执行上下文就会从栈顶弹出,并将 result 的值设置为 add 函数的返回值,也就是 9
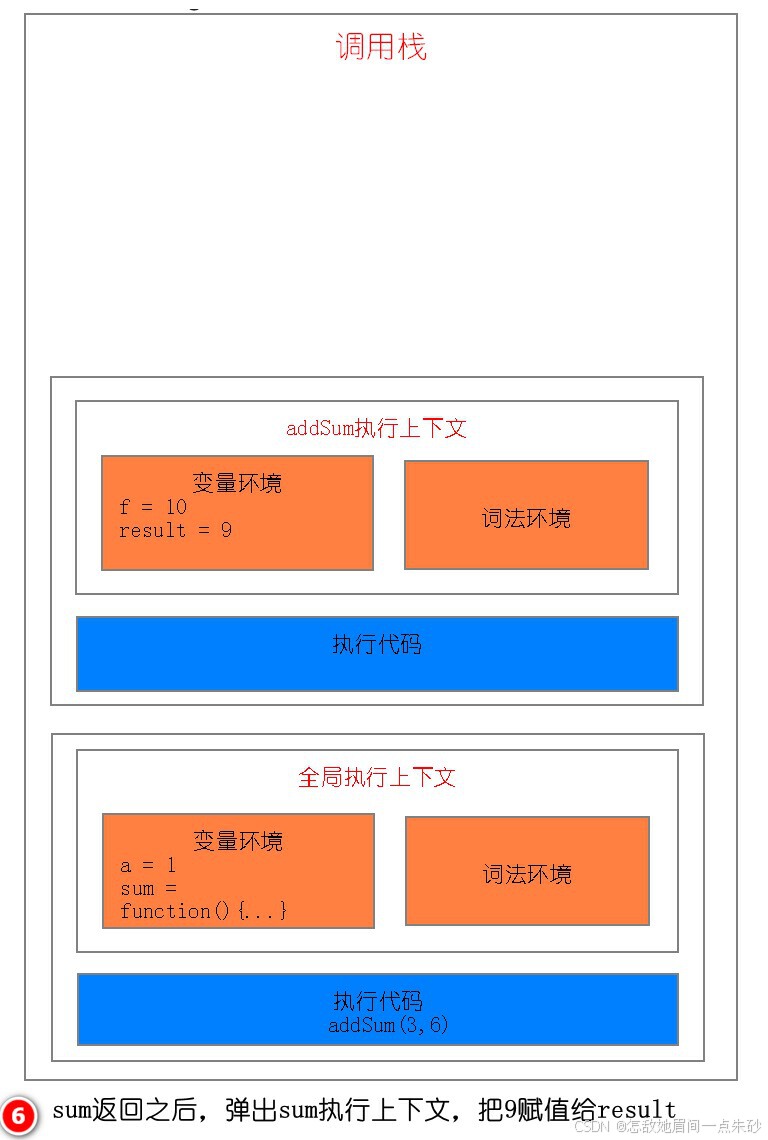
第五步:addSum 执行最后一个相加操作后并返回,addSum 的执行上下文也会从栈顶部弹出,此时调用栈中就只剩下全局上下文了

2.8 this指向
call():可以调用函数,可以改变this指向,还可以继承类。会立即执行
apply():以伪数组形式存在。会立即执行
bind():开发实用最多,改变指向但是不会立即调用函数。
2.8.1 this关键字由来
this关键字由来:在对象内部的方法中使用对象内部的属性是一个非常普遍的需求。但是 JavaScript 的作用域机制并不支持这一点,基于这个需求,JavaScript 又搞出来另外一套 this 机制。
var bar = {
myName:"闷倒驴",
printName: function () { console.log(myName) }
}
let myName = '王美丽';
bar.printName(); // '王美丽'
var bar = {
myName:"闷倒驴",
printName: function () { console.log(this.myName) }
}
let myName = '王美丽';
bar.printName(); // '王美丽'作用域链和 this 是两套不同的系统,它们之间基本没太多联系
2.8.2this在哪里可以使用
全局上下文中的this
console.log(this)来打印出来全局执行上下文中的 this,最终输出的是 window 对象。所以你可以得出这样一个结论:全局执行上下文中的 this 是指向 window 对象的。这也是 this 和作用域链的唯一交点,作用域链的最底端包含了 window 对象,全局执行上下文中的 this 也是指向 window 对象
函数上下文中的this
-
在全局环境中调用一个函数,函数内部的 this 指向的是全局变量 window。
-
通过一个对象来调用其内部的一个方法,该方法的执行上下文中的 this 指向对象本身
function foo(){
// 'use strict';
console.log(this)
};
foo() // window2.8.3 this指向总结
this指向总结
-
当函数被正常调用时,在严格模式下,this 值是 undefined,非严格模式下 this 指向的是全局对象 window;
-
通过一个对象来调用其内部的一个方法,该方法的执行上下文中的 this 指向对象本身
-
ES6 中的箭头函数并不会创建其自身的执行上下文,所以箭头函数中的 this 取决于它的外部函数
-
new 关键字构建好了一个新对象,并且构造函数中的 this 其实就是新对象本身
-
当执行 new CreateObj() 的时候,JavaScript 引擎做了如下四件事:
-
首先创建了一个空对象 tempObj;
-
接着调用 CreateObj.call 方法,并将 tempObj 作为 call 方法的参数,这样当 CreateObj 的执行上下文创建时,它的 this 就指向了 tempObj 对象;
-
然后执行 CreateObj 函数,此时的 CreateObj 函数执行上下文中的 this 指向了 tempObj 对象;
-
最后返回 tempObj 对象。
-
-
-
嵌套函数中的 this 不会继承外层函数的 this 值。
var myObj = { name : "闷倒驴", showThis: function(){ console.log(this); // myObj var bar = function(){ this.name = "王美丽"; console.log(this) // window } bar(); } }; myObj.showThis(); console.log(myObj.name); console.log(window.name);-
解决this不继承的方法
-
内部函数使用箭头函数
-
将在外层函数中创建一个变量,用来存储this,内层函数通过作用域链即可访问
var myObj = { name : "闷倒驴", showThis:function(){ console.log(this); // myObj var bar = ()=>{ this.name = "王美丽"; console.log(this) // window } bar(); } }; myObj.showThis(); console.log(myObj.name); console.log(window.name); var myObj = { name : "闷倒驴", showThis:function(){ console.log(this); // myObj var self = this; var bar = function (){ self.name = "王美丽"; console.log(self) // window } bar(); } }; myObj.showThis(); console.log(myObj.name); console.log(window.name); -
-
2.8.4改变this指向的方法
1 call 和 apply 的共同点
都能够改变函数执行时的上下文,将一个对象的方法交给另一个对象来执行,并且是立即执行的
调用 call 和 apply 的对象,必须是一个函数 Function
2 call 和 apply 的区别
call 的写法
Function.call(obj,[param1[,param2[,…[,paramN]]]])需要注意以下几点:
-
调用 call 的对象,必须是个函数 Function。
-
call 的第一个参数,是一个对象。 Function 的调用者,将会指向这个对象。如果不传,则默认为全局对象 window。
-
第二个参数开始,可以接收任意个参数。每个参数会映射到相应位置的 Function 的参数上。但是如果将所有的参数作为数组传入,它们会作为一个整体映射到 Function 对应的第一个参数上,之后参数都为空。
function func (a,b,c) {}
func.call(obj, 1,2,3)
// func 接收到的参数实际上是 1,2,3
func.call(obj, [1,2,3])
// func 接收到的参数实际上是 [1,2,3],undefined,undefinedapply 的写法
Function.apply(obj[,argArray])需要注意的是:
-
它的调用者必须是函数 Function,并且只接收两个参数,第一个参数的规则与 call 一致。
-
第二个参数,必须是数组或者类数组,它们会被转换成类数组,传入 Function 中,并且会被映射到 Function 对应的参数上。这也是 call 和 apply 之间,很重要的一个区别。
func.apply(obj, [1,2,3])
// func 接收到的参数实际上是 1,2,3
func.apply(obj, {
0: 1,
1: 2,
2: 3,
length: 3
})
// func 接收到的参数实际上是 1,2,33 call 和 apply 的用途
下面会分别列举 call 和 apply 的一些使用场景。声明:例子中没有哪个场景是必须用 call 或者必须用 apply 的,只是个人习惯这么用而已。
call 的使用场景
1、对象的继承。如下面这个例子:
function superClass () {
this.a = 1;
this.print = function () {
console.log(this.a);
}
}
function subClass () {
superClass.call(this); // 执行superClass,并将superClass方法中的this指向subClass
this.print();
}
subClass();
// 1subClass 通过 call 方法,继承了 superClass 的 print 方法和 a 变量。此外,subClass 还可以扩展自己的其他方法。
2、借用方法。还记得刚才的类数组么?如果它想使用 Array 原型链上的方法,可以这样:
let domNodes = Array.prototype.slice.call(document.getElementsByTagName("*"));这样,domNodes 就可以应用 Array 下的所有方法了。
原理:执行数组的slice方法,把this指向伪数组
// slice2()
Array.prototype.slice2 = function (start, end) {
start = start || 0
end = start || this.length
const arr = []
for (var i = start; i < end; i++) {
arr.push(this[i])
}
return arr
}apply 的一些妙用
1、Math.max。用它来获取数组中最大的一项。
let max = Math.max.apply(null, array);同理,要获取数组中最小的一项,可以这样:
let min = Math.min.apply(null, array);2、实现两个数组合并。在 ES6 的扩展运算符出现之前,我们可以用 Array.prototype.push来实现。
let arr1 = [1, 2, 3];
let arr2 = [4, 5, 6];
Array.prototype.push.apply(arr1, arr2);
console.log(arr1); // [1, 2, 3, 4, 5, 6]4 bind
bind 的使用
在 MDN 上的解释是:bind() 方法创建一个新的函数,在调用时设置 this 关键字为提供的值。并在调用新函数时,将给定参数列表作为原函数的参数序列的前若干项。
它的语法如下:
Function.bind(thisArg[, arg1[, arg2[, ...]]])bind 方法 与 apply 和 call 比较类似,也能改变函数体内的 this 指向。
不同的是,bind 方法的返回值是函数,并且需要稍后调用,才会执行。而 apply 和 call 则是立即调用。
来看下面这个例子:
function add (c) {
return this.a + this.b + c;
}
var obj = {a:1,b:2}
add.bind(obj, 5); // 这时,并不会返回 8
add.bind(sub, 5)(); // 调用后,返回 8如果 bind 的第一个参数是 null 或者 undefined,this 就指向全局对象 window。
在vue或者react框架中,使用bind将定义的方法中的this指向当前类
2.9原型链的理解🌟
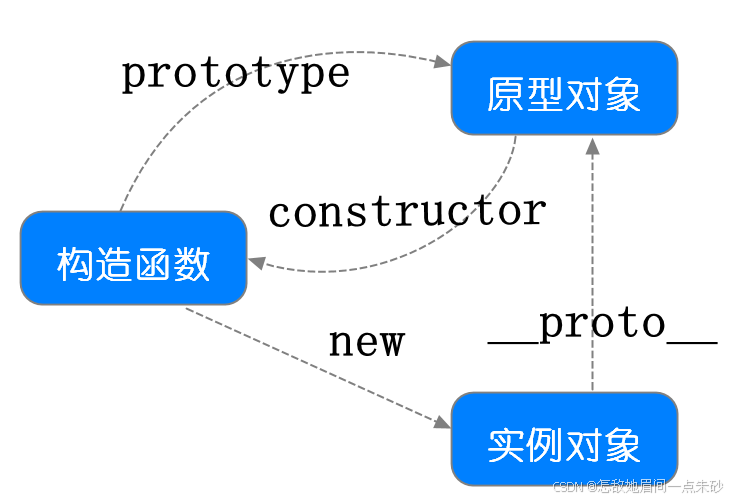
原型对象:构造函数在创建时都会赋予一个prototype属性,指向函数的原型对象,这个对象可以包含所有实例共享的属性和函数。
原型链:对象的每一个实例都具有一个proto属性,指向的是构造函数的原型对象,而原型对象上面同样有一个proto属性指向上一级构造函数的原型对象,层层往上,直到某个原型对象为null。
2.10 new一个实例经历的过程
-
创建一个新对象;
-
将构造函数的作用域给新对象;
-
执行构造函数的代码,为新对象添加属性;
-
返回新对象。
2.11 继承方法和特点🌟
2.11.1 继承是什么?
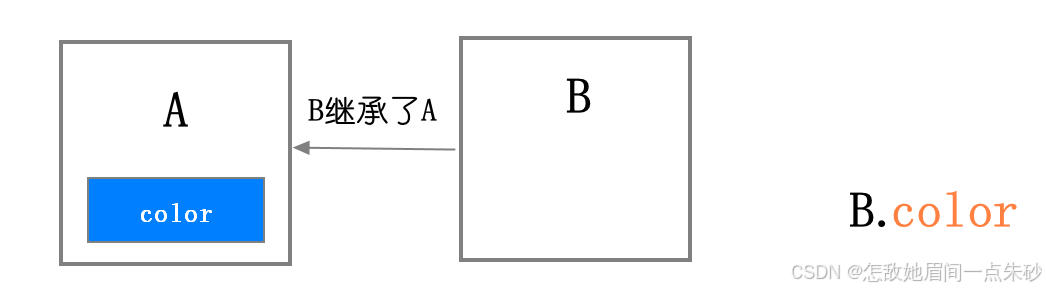
-
继承就是一个对象可以访问另外一个对象中的属性和方法
2.11.2 继承的目的?
-
继承的目的就是实现原来设计与代码的重用
2.11.3 继承的方式
-
java、c++等:class
-
javaScript: 原型链 ES2015/ES6 中引入了 class 关键字,但那只是语法糖,JavaScript 的继承依然和基于类的继承没有一点关系
2.11.4 原型与原型链
JavaScript 只有一种结构:对象。
JavaScript 的每个对象都包含了一个隐藏属性proto,我们就把该隐藏属性 proto 称之为该对象的原型 (prototype),proto 指向了内存中的另外一个对象,我们就把 proto 指向的对象称为该对象的原型,那么该对象就可以直接访问其原型对象的方法或者属性。
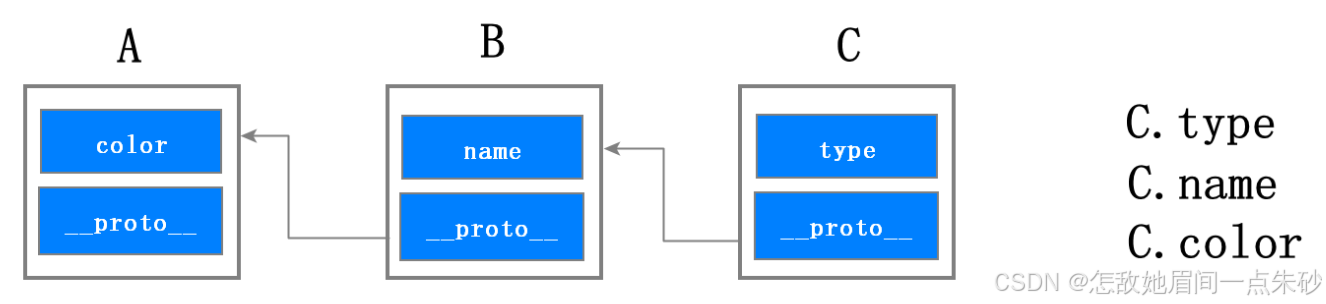
看到使用 C.name 和 C.color 时,给人的感觉属性 name 和 color 都是对象 C 本身的属性,但实际上这些属性都是位于原型对象上,我们把这个查找属性的路径称为原型链
每个实例对象( object )都有一个私有属性(称之为 proto )指向它的构造函数的原型对象(prototype )。该原型对象也有一个自己的原型对象( proto ) ,层层向上直到一个对象的原型对象为 null。根据定义,null 没有原型,并作为这个原型链中的最后一个环节。
总结:继承就是一个对象可以访问另外一个对象中的属性和方法,在JavaScript 中,我们通过原型和原型链的方式来实现了继承特性。
2.11.5 继承的方式
1 构造函数如何创建对象
function DogFactory(type, color) {
this.type = type;
this.color = color
}
var dog = new DogFactory('Dog','Black')创建实例的过程
var dog = {};
dog.__proto__ = DogFactory.prototype;
DogFactory.call(dog,'Dog','Black');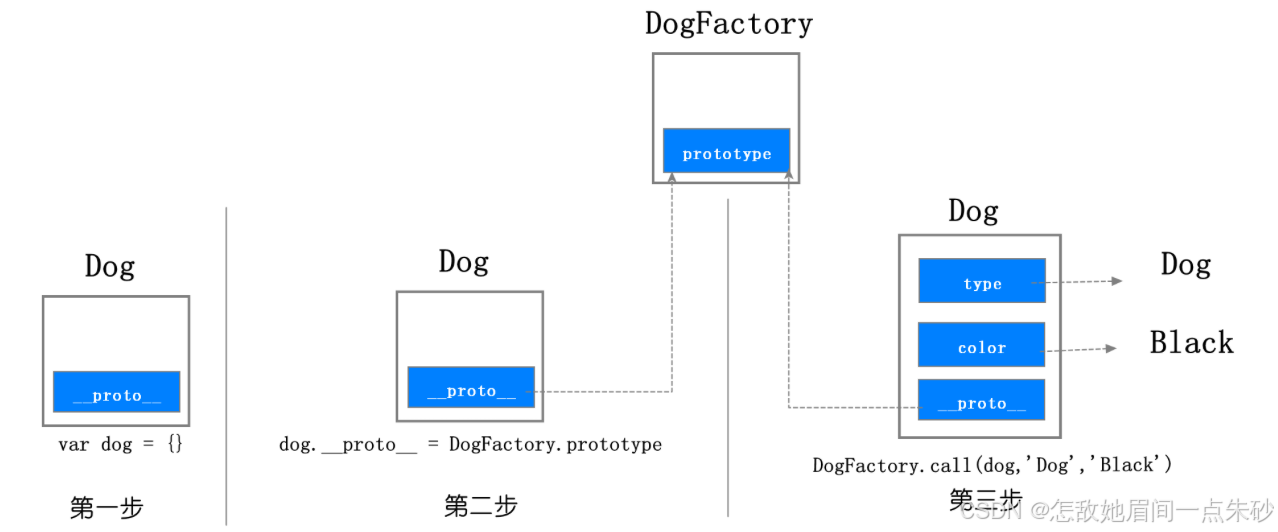
观察上图,我们可以看到执行流程分为三步:
首先,创建了一个空白对象 dog;
然后,将 DogFactory 的 prototype 属性设置为 dog 的原型对象,这就是给 dog 对象设置原型对象的关键一步;
每个函数对象中都有一个公开的 prototype 属性,当你将这个函数作为构造函数来创建一个新的对象时,新创建对象的原型对象就指向了该函数的 prototype 属性,所以通过该构造函数创建的任何实例都可以通过原型链找到构造函数的prototype上的属性
最后,再使用 dog 来调用 DogFactory,这时候 DogFactory 函数中的 this 就指向了对象 dog,然后在 DogFactory 函数中,利用 this 对对象 dog 执行属性填充操作,最终就创建了对象 dog。
实例的proto属性 == 构造函数的proyotype
2 原型链继承
原理: 实现的本质是通过将子类的原型指向了父类的实例,
优点:
-
父类新增原型方法/原型属性,子类都能访问到
-
简单容易实现
缺点:
-
不能实现多重继承
-
来自原型对象的所有属性被所有实例共享
-
创建子类实例时,无法向父类构造函数传参
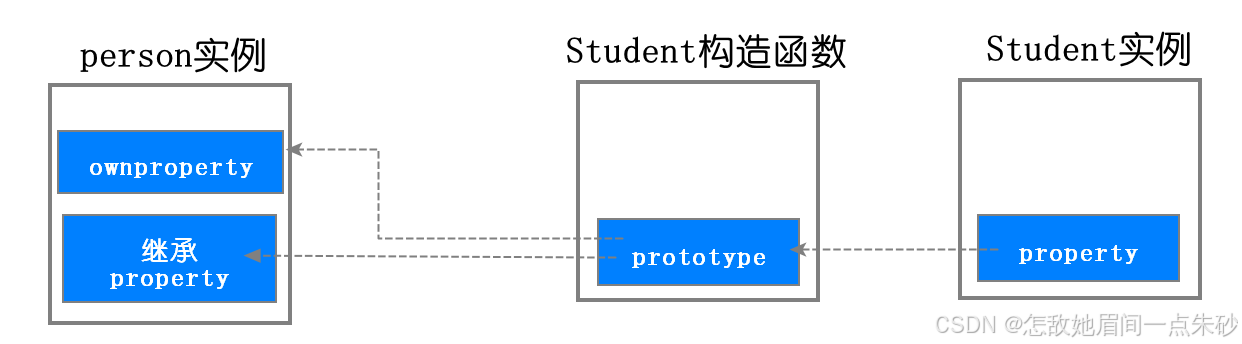
//父类型
function Person(name, age) {
this.name = name,
this.age = age,
this.play = [1, 2, 3]
this.setName = function () { }
}
Person.prototype.setAge = function () { }
//子类型
function Student(price) {
this.price = price
this.setScore = function () { }
}
Student.prototype = new Person('wang',23) // 子类型的原型为父类型的一个实例对象
var s1 = new Student(15000)
var s2 = new Student(14000)
console.log(s1,s2)3 借用构造函数实现继承
原理:在子类型构造函数中通用call()调用父类型构造函数
特点:
-
解决了原型链继承中子类实例共享父类引用属性的问题
-
创建子类实例时,可以向父类传递参数
-
可以实现多重继承(call多个父类对象)
缺点:
-
实例并不是父类的实例,只是子类的实例
-
只能继承父类的实例属性和方法,不能继承父类原型属性和方法
-
无法实现函数复用,每个子类都有父类实例函数的副本,影响性能
function Person(name, age) {
this.name = name,
this.age = age,
this.setName = function () {}
}
Person.prototype.setAge = function () {}
function Student(name, age, price) {
Person.call(this, name, age)
// 相当于:
/*
this.Person(name, age)
this.name = name
this.age = age*/
this.price = price
}
var s1 = new Student('Tom', 20, 15000)4 原型链+借用构造函数的组合继承
原理:通过调用父类构造,继承父类的属性并保留传参的优点,然后通过将父类实例作为子类原型,实现函数复用。
优点:
-
可以继承实例属性/方法,也可以继承原型属性/方法
-
不存在引用属性共享问题
-
可传参
-
父类原型上的函数可复用
缺点:
-
调用了两次父类构造函数,生成了两份实例
function Person(name, age) {
this.name = name,
this.age = age,
this.setAge = function () { }
}
Person.prototype.setAge = function () {
console.log("111")
}
function Student(name, age, price) {
Person.call(this,name,age)
this.price = price
this.setScore = function () { }
}
Student.prototype = new Person()
Student.prototype.constructor = Student//组合继承也是需要修复构造函数指向的
var s1 = new Student('Tom', 20, 15000)
var s2 = new Student('Jack', 22, 14000)
console.log(s1)
console.log(s1.constructor) //Student5 ES6 class继承
原理:ES6中引入了class关键字,class可以通过extends关键字实现继承,还可以通过static关键字定义类的静态方法,这比 ES5 的通过修改原型链实现继承,要清晰和方便很多。
优点:
-
语法简单易懂,操作更方便
缺点:
-
并不是所有的浏览器都支持class关键字
class Person {
//调用类的构造方法
constructor(name, age) {
this.name = name
this.age = age
}
//定义一般的方法
showName() {
console.log("调用父类的方法")
console.log(this.name, this.age);
}
}
let p1 = new Person('kobe', 39)
console.log(p1)
//定义一个子类
class Student extends Person {
constructor(name, age, salary) {
super(name, age)//通过super调用父类的构造方法
this.salary = salary
}
showName() {//在子类自身定义方法
console.log("调用子类的方法")
console.log(this.name, this.age, this.salary);
}
}
let s1 = new Student('wade', 38, 1000000000)
console.log(s1)
s1.showName()另一种思路:
-
原型链继承。
Student.prototype = new Person('wang',23)原理:将子类的原型指向了父类的实例
优点:父类新增原型方法/原型属性,子类都能访问到;简单容易实现
缺点:不能实现多重继承;来自原型对象的所有属性都能被所有实例共享;创建子类实例时,无法向父类构造函数传参
-
借用构造函数实现继承
function Son(name,age,price){ Person.call(this,name,age) this.price = price }原理:在子类构造函数中通过call()调用父类型构造函数
优点:解决了原型链继承中子类实现共享父类引用属性的问题;创建子类实例时,可以向父类传递参数;可以实现多重继承(call多个父类对象)
缺点:实例并不是父类的实例,只是子类的实例;只能继承父类的实例属性和方法,不能继承父类原型属性和方法;无法实现函数复用,每个子类都有父类实例函数的副本,影响性能。
-
原型链+借用构造函数的组合继承
原理:通过调用父类构造、继承父类的属性并保留传参的优点,然后通过将父类实例作为自类原型,实现函数复用。
优点:可以继承实例属性/方法,也可以继承原型属性方法;不存在引用属性共享问题;可传参;父类原型上的函数可复用
缺点:调用了两次父类构造函数,生成两份实例
-
ES6 class继承
原理:class可以通过extends关键字实现继承,还可以通过static关键字定义类的静态方法,这比ES5的通过修改原型链实现继承要清洗方便很多
优点:语法简单易懂,操作更方便
缺点:并不是所有的浏览器都支持class关键字
2.12 ES6高阶语法🌟
2.12.1 let、var、const
var:声明的全局变量挂载在window对象下函数作用域,存在变量提升,声明变量可重复声明和修改
let和const:声明的全局变量不挂载在window对象下,不存在变量提升,不允许重复声明。
const:声明一个只读的常量,一旦声明,常量的值就不能改变。
1. var 关键字
-
声明的全局变量挂载在window对象下
var a = 1; console.log(window.a) -
变量提升
console.log(a); var a = 1; -
声明的变量可以重复声明和修改
var a = 1; var a = '111'; console.log(a);
2. let 和 const 关键字
-
let和const声明的全局变量不挂载在window对象下
-
let 和 const 定义的变量不会出现变量提升现象,let/const 也存在变量声明提升,只是没有初始化分配内存。 一个变量有三个操作,声明(提到作用域顶部),初始化(赋默认值),赋值(继续赋值),其实就是创建提升,因为没有初始化分配内存,所以使用该变量就会报错,这是暂时性死区
-
let 和 const 是JS中的块级作用域
-
let 和 const 不允许重复声明(会抛出错误)
-
const 声明一个只读的常量。一旦声明,常量的值就不能改变(如果声明是一个对象,那么不能改变的是对象的引用地址)
2.12.2 解构赋值
ES6允许从数组中提取值,按照对应位置,对变量赋值。对象也可以实现解构。
1. 解构符号的作用
解构赋值是对赋值运算符的扩展,他是一种针对数组或者对象进行模式匹配,然后对其中的变量进行赋值
ES6 允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构
2. 使用方式
-
基本使用
let [a, b, c] = [1, 2, 3]; // let a = 1,b = 2,c=3 -
嵌套使用
// 数组 let [a, [[b], c]] = [1, [[2], 3]]; console.log(a); console.log(b); console.log(c); // 对象 let obj = {p: ['hello', {y: 'world'}] }; let {p: [x, { y }] } = obj; console.log(x); console.log(y); -
忽略
// 数组 let [a, , b] = [1, 2, 3]; console.log(a); console.log(b); // 对象 let obj = { p: ['hello', { y: 'world' }] }; let { p: [x, { }] } = obj; console.log(x); -
不完全解构
// 数组 let [a = 1, b] = []; console.log(a); console.log(b); // 对象 let obj = { p: [{ y: 'world' }] }; let { p: [{ y }, x] } = obj; console.log(x); console.log(y); -
剩余运算符
// 数组 // let [a, ...b] = [1, 2, 3]; // console.log(a); // console.log(b); // 对象 let {a, b, ...rest} = {a: 10, b: 20, c: 30, d: 40}; console.log(a); console.log(b); console.log(rest); -
字符串
let [a, b, c, d, e] = 'hello'; console.log(a); console.log(b); console.log(c); console.log(d); console.log(e); -
解构默认值
// 当解构模式有匹配结果,且匹配结果是 undefined 时,会触发默认值作为返回结果。 let [a = 2] = [undefined]; console.log(a); // 对象 let {a = 10, b = 5} = {a: 3}; // console.log(a); // console.log(b); -
交换变量的值.
let a = 1; let b = 2; [a,b] = [b,a]; console.log(a); console.log(b);
3. 解构赋值的应用
// 1. 浅克隆与合并
let name = { name: "aaa" }
let age = { age: 'bbb' }
let person = { ...name, ...age }
console.log(person) // { name: "aaa", age: 'bbb' }
let a = [1,2,3];
let b = [4,5];
let c = [...a,...b];
console.log(c);
// 2. 提取JSON数据
let JsonData = { id: 10, status: "OK", data: [111, 222] }
let { id, status, data: numbers } = JsonData;
console.log(id, status, numbers); //10 "OK" [111, 222]
// 3. 函数参数的定义
// 参数有序
function fun1([a, b, c]) { console.log(a, b, c) }
fun1([1, 2, 3]);
// 参数无序
function fun2({ x, y, z }) { console.log(x, y, z) }
fun2({ z: 3, x: 2, y: 1 });
// 参数有默认值
function fun3 ([a=1,b]) {
console.log(a,b);
}
fun3([,3])2.12.3 箭头函数
形参只有一个时候,可以省略括号。
特点:箭头函数没有this,this是从外部获取的;箭头函数不能对箭头函数进行new操作;箭头函数没有arguments;箭头函数没有原型和super
箭头函数和普通函数的区别:
-
写作方式不一样
-
箭头函数不能用于构造函数
-
箭头函数中this指向不同
-
箭头函数不具有arguments、prototype和super对象
1. 箭头函数没有this,this是从外部获取的
let group = {
title: "Our Group",
students: ["John", "Pete", "Alice"],
showList() {
this.students.forEach(
student => alert(this.title + ': ' + student)
);
}
};
group.showList();2. 箭头函数不能对箭头函数进行 new 操作
不具有 this 自然也就意味着另一个限制:箭头函数不能用作构造器(constructor)。不能用 new 调用它们。
var Foo = () => {};
var foo = new Foo(); // TypeError: Foo is not a constructor3. 箭头函数没有arguments
箭头函数没有自己的 arguments 对象,但是箭头函数可以访问外围函数的 arguments 对象:
function constant() {
return () => arguments[0]
}
var result = constant(1);
console.log(result()); // 14. 箭头函数没有原型和super
连原型都没有,自然也不能通过 super 来访问原型的属性,所以箭头函数也是没有 super 的,不过跟 this、arguments、new.target 一样,这些值由外围最近一层非箭头函数决定。
var Foo = () => {};
console.log(Foo.prototype); // undefined2.12.4 剩余参数
剩余参数语法允许我们讲一个不定数量的参数表示为一个数组。
此外,还有array扩展方法、string扩展方法和set数据结构
2.13 map和weakmap的区别
map的特点:map的键和值可以是任何数据类型;键值对按照插入顺序排列;map数据可迭代,object数据不可迭代。
map的常用属性:
map.set(key,value):添加键值对到映射中 map.get(key):获取映射中某一个键的对应值 map.delete(key):将某一键值对移除映射 map.clear():清空映射中的所有键值对 map.entries():返回一个二元数组作为元素的数组 map.has(key):检查映射中是否包含某一键值对 map.keys():返回一个当前映射中所有键作为元素的可迭代对象 map.values():返回一个当前映射中所有值作为元素的可迭代对象 map.size:映射中键值对的数量
weakmap的特点:weakmap结构与map结构类似,也是用于生成键值对的集合。
weakmap只接受对象作为键名(null除外),不接受其他类型作为键名。键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾回收,此时键名是无效的。
2.13.1 map
1.1 map特点
-
Map的键和值可以是任何数据类型
//1. map的键名可以是任意数据 var map = new Map(); var o = {num:1}; map.set(o,'111'); console.log(map); -
键值对按照插入顺序排列
// map有顺序 var map = new Map([[2,'111'],[1,'222']]); console.log(map); // obj自动排序 var obj = {'2':'111','1':'222'} console.log(obj); -
map数据可迭代,object数据不可迭代
var map = new Map([[2,'111'],[1,'222']]); console.log(map); for(var value of map){ console.log(value) }
1.2 map的常用属性
| 操作方法 | 内容描述 |
|---|---|
| map.set(key,value) | 添加键值对到映射中 |
| map.get(key) | 获取映射中某一个键的对应值 |
| map.delete(key) | 将某一键值对移除映射 |
| map.clear() | 清空映射中所有键值对 |
| map.entries() | 返回一个以二元数组(键值对)作为元素的数组 |
| map.has(key) | 检查映射中是否包含某一键值对 |
| map.keys() | 返回一个当前映射中所有键作为元素的可迭代对象 |
| map.values() | 返回一个当前映射中所有值作为元素的可迭代对象 |
| map.size | 映射中键值对的数量 |
let map = new Map();
let o = {n: 1};
// 给map添加o属性,值是’A‘
map.set(o, "A");
// 给map添加'2'属性,值是9
map.set("2", 9);
// 判断是否存在’2‘属性
console.log(map.has("2"));
// 获取o属性值
console.log(map.get(o));
console.log(...map);
// 查看map
console.log(map);
// 删除’2‘属性
map.delete("2");
// 清空所有属性
map.clear();
//create a map from iterable object
let map_1 = new Map([[1, 2], [4, 5]]);
console.log(map_1.size); //number of keys1.3 遍历map数据
-
keys():返回键名的遍历器 -
values():返回键值的遍历器 -
entries():返回键值对的遍历器 -
forEach():使用回调函数遍历每个成员
const map = new Map([
['a', 1],
['b', 2],
])
for (let key of map.keys()) {
console.log(key)
}
// "a"
// "b"
for (let value of map.values()) {
console.log(value)
}
// 1
// 2
for (let item of map.entries()) {
console.log(item)
}
// ["a", 1]
// ["b", 2]
// 或者
for (let [key, value] of map.entries()) {
console.log(key, value)
}
// "a" 1
// "b" 2
// for...of...遍历map等同于使用map.entries()
for (let [key, value] of map) {
console.log(key, value)
}
// "a" 1
// "b" 22.13.2 WeakMap
2.1 WeakMap特点
WeakMap 结构与 Map 结构类似,也是用于生成键值对的集合。
-
只接受对象作为键名(
null除外),不接受其他类型的值作为键名// 1. 只能使用对象作为键名 var weakmap = new WeakMap(); // weakmap.set('a',111); var o = {num:1}; weakmap.set(o,111); console.log(weakmap); -
键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾回收,此时键名是无效的
// 2. 键名是弱引用,如果键名销毁,该属性就销毁 (IE打开) var weakmap = new WeakMap(); var o = {num:1}; weakmap.set(o,111); o = null; console.log(weakmap); -
不可枚举,枚举影响其列表将会受垃圾回收机制的影响,方法有
get、set、has、delete
3 网络
3.1 OSI七层模型和TCP/IP四层模型🌟

物理层:通过网络、光缆等物理方式将电脑连接起来。传递的数据是比特流。
数据链路层:实现两个节点之间的数据传输。把比特流封装成数据帧的格式,对0、1进行分组。电脑连接起来之后,数据都经过网卡来传输,而网卡上定义了世界唯一的MAC地址。然后再通过广播的形式向局域网内所有电脑发送数据,再根据数据中MAC地质和自身对比判断是否发给自己。
网络层:提供了互联网多节点之间数据传输的逻辑链路。广播的形式太低效,为了区分哪些MAC地址属于同一个子网,网络层定义了IP和子网掩码,通过对IP和子网掩码进行与运算就知道是否是同一个子网,再通过路由器和交换机进行传输。IP协议属于网络层的协议。
传输层:有了网络层的MAC+IP地址之后,为了确定数据包是从哪个进程发送过来的,就需要端口号,通过端口来建立通信。TCP和UDP属于这一层的协议。
会话层:负责建立和断开连接。
表示层:为了使得数据能够被其他的计算机理解,再次将数据转换成另外一种形式,比如文字、视频、图片等。
应用层:最高层,面对用户,提供计算机网络与最终呈现给用户的界面。http协议属于应用层。
3.2 TCP三次握手和四次挥手🌟
-
客户端发送一个SYN给服务器端。
-
服务器端接收到之后,返回一个ACK响应,同时也会发送一个SYN给客户端
-
客户端收到服务器端的ACK后,返回一个ACK给服务器端。
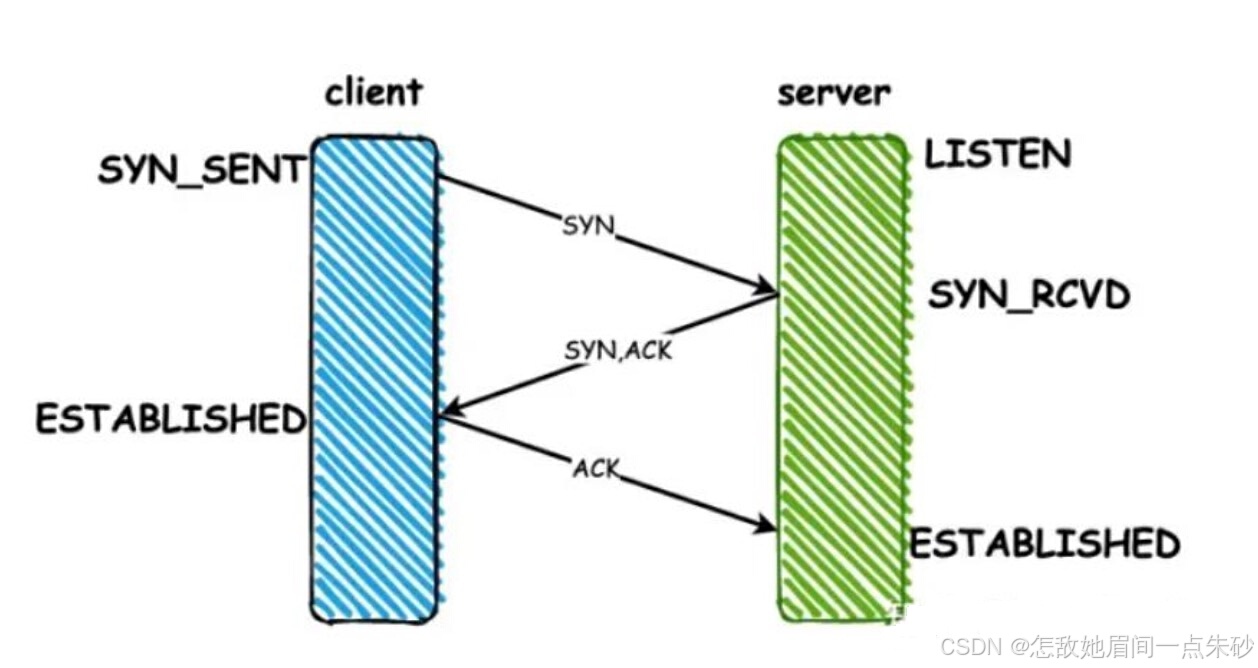
-
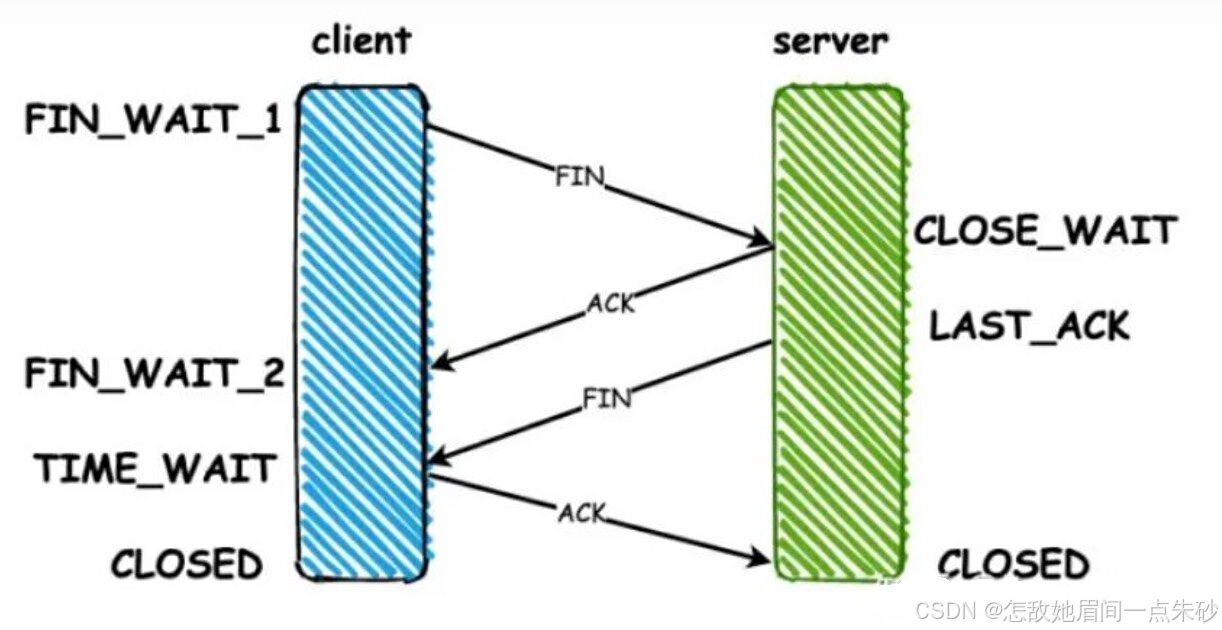
客户端在发送完数据后,给服务器端发送一个FIN包,代表客户端已经没有数据要发送了
-
服务器端收到之后,返回一个ACK,等待服务器端把剩余数据发送完成
-
等到服务器端把剩余数据都发送完毕之后,服务器端就向客户端发送一个FIN
-
客户端收到FIN之后,回复一个ACK,服务器收到ACK之后关闭连接,客户端等待2MSL(报文最大生成时间)之后,关闭连接。
3.3 TCP传输的可靠性🌟
-
校验和:发送方发送数据前计算校验和,接收方收到数据后同样计算,结果不一致,则传输有误
-
确认应答,序列号:TCP进行传输时数据都进行了编号,每次接收方返回ACK都有确认序列号
-
超时重传:如果发送方发送一段数据后没收到ACK,就重发数据
-
连接管理:三次握手和四次挥手
-
流量控制:TCP协议报头包含16位的窗口大小,接收方会在返回ACK的同时 把自己的即时窗口填入,发送方根据报文窗口的大小控制发送速度。
-
拥塞控制:刚开始发送数据的时候,拥塞窗口是1,以后每次收到ACK,则拥塞窗口+1,然后将拥塞窗口和收到的窗口取较小值作为实际发送的窗口,如果发生超时重传,拥塞窗口重置为1.这样做的目的就是为了保证传输过程的高效性和可靠性。
3.4 TCP和UDP区别🌟
TCP(Transmission Control Protocol,传输控制协议),是一种面向连接的、可靠的、基于字节流的传输层通信协议。
UDP是一种无连接的传输层协议,传输可靠性没有保证。
-
tcp是面向连接,通过三次握手建立连接,四次挥手接触连接;udp是无连接的;
-
tcp是可靠的通信方式,通过tcp连接传送的数据,tcp通过超时重传、数据校验等方式来确保数据无差错、不丢失、不重复,且按序到达;而udp由于无需连接的原因,会以最大速度进行传输,但是不保证可靠交付,也就是会出现丢失、重复等问题;
-
tcp面向字节流,而udp面向报文,udp没有拥塞控制,因而网络出现拥塞不会使源主机的发送效率降低;
-
每一条tcp连接只能是点到点的,而udp不建立连接,所以可以支持一对一、一对多、多对一、多对多;
-
tcp需要建立连接,首部开销20字节相比8个字节的udp显得比较大;
-
tcp的逻辑通信信道是全双工的可靠信道,udp则是不可靠信道。
3.5 TCP报文组成部分
-
端口号:用来标识同一台计算机的不同的应用进程。
(1)源端口:源端口和IP地址的作用是标识报文的返回地址。
(2)目标端口:端口指明接收方计算机上的应用程序接口。
TCP报文中的源端口号和目的端口号同IP数据报中的源IP与目的IP唯一确定一条TCP连接。
-
序列和确认号:序号是TCP可靠传输的关键部分,用于确保TCP传输的有序性;确认号指明下一个期待收到的字节序号,表明该序号之前的所有数据已经正确无误的收到。
-
数据偏移/首部长度:
-
保留:
-
控制位:
-
窗口:
-
校验和
-
紧急指针
-
选项和填充
-
数据部分
3.6 UDP报文组成部分
源端口号
目的端口号
3.7 http
3.8 http和https
-
http是明文传输,https传输的内容都是经过加密的,安全性更好
-
http和https使用的是完全不同的连接方式,用的端口也不一样。前者80,后者443
-
http连接很简单,是无状态的,https是可进行加密传输、身份认证的网络协议。https握手阶段比较费时。
3.9 get和post区别🌟
-
传递参数位置不同。get作为url的一部分,post作为请求体传输,所以post更加安全
-
请求参数长度限制。get请求传递的参数长度有限制(不超过2048个字符);post请求传递参数的长度无限制
-
请求参数安全性。get安全性较差。
-
post比get慢。post在真正接收数据之前会先将请求头发送给服务器确认,然后才真正发送数据。
-
功能差距。post用于修改和写入数据,get一般用于搜索排序和筛选之类的操作。
3.10 localStorage、sessionStorage、cookie和session
-
cookie数据大小不能超过4k;而localStorage和sessionStorage的存储会比cookie大的多,可以达到5M;
-
cookie设置的过期时间钱一直有效;localStorage永久存储,浏览器关闭后数据不丢失除非主动删除数据;sessionStorage数据在当前浏览器窗口关闭后自动删除;
-
cookie数据会自动传递到服务器,localStorage和sessionStorage数据保存在本地;
-
cookie是保存在客户端,session是保存在服务器的;
-
cookie有大小限制,session更加安全;
-
session会比较占用服务器性能,当访问增多时应用cookie。
3.11 ajax
3.12 websocket🌟
http协议是一种无状态、无连接、单向的应用层协议。而websocket是一种
-
即时通讯工具。webSocket是html5的一个持久化的协议,它实现了浏览器与服务器的全双工通信,同时也是跨域的一种解决方案。
-
webSocket和http都是应用层协议,都基于TCP协议,但是webSocket一种双向通信协议,在建立连接后,webSocket的服务器和客户端都能主动向对象发送和接收数据。
3.13 跨域🌟
跨域是浏览器为了保证页面的安全,出的同源协议策略。当页面中的某个接口请求的地址和当前页面地址的协议、域名和端口号其中有一项不同,就说明接口跨域了。
解决方式:
Cors:服务器通过设置相应头让浏览器关闭拦截设置。
Jsonp:
PostMessage:
Node中间代理:
1. 什么是跨域?
当前页面中的某个接口请求的地址和当前页面的地址如果协议、域名、端口其中有一项不同,就说该接口跨域了
2. 为什么有跨域?
浏览器为了保证网页的安全,出的同源协议策略
3. 跨域报错
4. 跨域解决办法
4.1 cors
目前最常用的一种解决办法,通过设置后端
res.setHeader('Access-Control-Allow-Origin', '*');
res.setHeader("Access-Control-Allow-Methods", "GET, PUT, OPTIONS, POST");
4.2 jsonp
利用的原理是script标签可以跨域请求资源,将回调函数作为参数拼接在url中
后端收到请求,调用该回调函数,并将数据作为参数返回去,注意设置响应头返回文档类型,应该设置成javascript
4.3 postmessage
场景:一个页面中嵌入另一个iframe页面,
使用postmessage发送数据
window.addEventListener("message", function (event) {
console.log('这里是接收到来自父页面的消息,消息内容在event.data属性中', event)
}, false)
4.4 其他方法:node中间件、nginx反向代理、websocket等
主要是因为同源策略是浏览器的限制,服务器和服务器之间没有限制
3.14 http1.0、http1.1、http2.0的区别
3.15 http的状态码🌟
1:服务器收到请求,需要请求者继续执行操作
2:成功,操作被成功接收并处理
200 OK:客户端请求成功
3:重定向,需要进一步的操作以完成请求
301:永久移动
302:临时移动
304:未修改
4:客户端错误,请求包含语法错误或无法完成请求
400客户端请求有语法错误,副
3.16 http响应头和请求头
3.17 http缓存
3.18 xss攻击和解决方法
3.19crsf攻击和解决方法
3.20 前后端怎么连接
3.21CDN
内容分发网络,解决如何快速可靠地从源站传递到用户的问题。
3.22 静态页面单独存储
3.23 内存泄露和内存溢出🌟
内存溢出:指应用的内存已经不能满足正常使用,堆栈已经达到系统设置的最大值,进而导致崩溃,是一种结果描述。
内存泄露:指应用使用资源之后没有及时释放,导致应用内存中持有了不需要的资源,这是一种状态描述。
3.24 局域网和广域网🌟
局域网:指某一区域内由多台计算机互联成的计算机组。局域网可以实现文件管理、应用软件共享、打印机共享、扫描仪共享、工作组内的日程安排、电子邮件和传真通信服务等功能。局域网是封闭型的,可以由办公室内的两台计算机组成,也可以由一个公司内的上千台计算机组成。
广域网:是一种跨越大的、地域性的计算机网络的集合。广域网包括大大小小不同的子网,子网可以是局域网,也可以是小型的广域网。
3.25 IP地址🌟
IP地址是指互联网协议地址。IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
3.26 TCP/IP四层协议族
1. 网络连接
| OSI七层模型 | TCP/IP四层协议族 | 对应网络协议 |
|---|---|---|
| 应用层(Application) | 应用层 | HTTP、TFTP, FTP, NFS, WAIS、SMTP |
| 表示层(Presentation) | Telnet, Rlogin, SNMP, Gopher | |
| 会话层(Session) | SMTP, DNS | |
| 传输层(Transport) | 传输层 | TCP, UDP |
| 网络层(Network) | 网络层 | IP, ICMP, ARP, RARP, AKP, UUCP |
| 数据链路层(Data Link) | 数据链路层 | FDDI, Ethernet, Arpanet, PDN, SLIP, PPP |
| 物理层(Physical) | IEEE 802.1A, IEEE 802.2到IEEE 802.11 |
-
OSI 模型,全称为 Open System Interconnection,即开放系统互联模型,这个是由 ISO(International Organization for Standardization) 国际标准化组织提出的。 它主要是用来解决当时各个网络技术供应商在协议上无法统一的问题,通过将整个网络体系结构抽象为 7层,从最底层的物理层、数据链路层一直到最上面的应用层都做了定义。
-
TCP/IP,即 TCP/IP Protocol Suite(协议套件)是一个以TCP协议和IP协议为核心的通信模型,该模型采用协议堆栈的方式来实现许多通信协议,并将通讯体系抽象为4层。 TCP/IP 模型最早发源于美国国防部(缩写为DoD)的ARPA网项目,此后就交由IETF组织来维护。
2. 网络层:简化的IP网络三层传输
2.1 IP头信息
IP 头是 IP 数据包开头的信息,包含 IP 版本、源 IP 地址、目标 IP 地址、生存时间等信息
2.2 IP层数据传输步骤
-
上层将含有“data”的数据包交给网络层;
-
网络层再将 IP 头附加到数据包上,组成新的 IP 数据包,并交给底层;
-
底层通过物理网络将数据包传输给主机 B;
-
数据包被传输到主机 B 的网络层,在这里主机 B 拆开数据包的 IP 头信息,并将拆开来的数据部分交给上层;最终,含有“data”信息的数据包就到达了主机 B 的上层了。
3. 传输层:简化的UDP四层网络连接
3.1 UDP作用
IP 通过 IP 地址信息把数据包发送给指定的电脑,而 UDP 通过端口号把数据包分发给正确的程序
3.2 UDP头信息
端口号会被装进 UDP 头里面,UDP 头再和原始数据包合并组成新的 UDP 数据包。UDP 头中除了目的端口,还有源端口号等信息
3.3 UDP层传输步骤
-
上层将含有“data”的数据包交给传输层;
-
传输层会在数据包前面附加上 UDP 头,组成新的 UDP 数据包,再将新的 UDP 数据包交给网络层;
-
网络层再将 IP 头附加到数据包上,组成新的 IP 数据包,并交给底层;
-
数据包被传输到主机 B 的网络层,在这里主机 B 拆开 IP 头信息,并将拆开来的数据部分交给传输层;
-
在传输层,数据包中的 UDP 头会被拆开,并根据 UDP 中所提供的端口号,把数据部分交给上层的应用程序;最终,含有“data”信息的数据包就旅行到了主机 B 上层应用程序这
3.4 UDP数据传输的特点
在使用 UDP 发送数据时,有各种因素会导致数据包出错,虽然 UDP 可以校验数据是否正确,但是对于错误的数据包,UDP 并不提供重发机制,只是丢弃当前的包,而且 UDP 在发送之后也无法知道是否能达到目的地
3.5 UDP的应用
UDP 不能保证数据可靠性,但是传输速度却非常快,所以 UDP 会应用在一些关注速度、但不那么严格要求数据完整性的领域,如在线视频、互动游戏等
4. 传输层:简化的TCP四层网络连接
4.1 TCP头信息
TCP 头除了包含了目标端口和本机端口号外,还提供了用于排序的序列号,以便接收端通过序号来重排数据包
4.2 TCP连接的生命周期
-
建立建立阶段(三次握手) 客户端向服务器端发送建立连接请求,服务器端做出应答,客户端告知服务器端收到应答 目的:对于客户端和服务器端发出的消息都能收到回复,才是可靠的
-
数据传输阶段 对于单个数据包:接收端需要对每个数据包进行确认操作。 也就是接收端在接收到数据包之后,需要发送确认数据包给发送端。 所以当发送端发送了一个数据包之后,在规定时间内没有接收到接收端反馈的确认消息, 则判断为数据包丢失,并触发发送端的重发机制 对于大文件:一个大的文件在传输过程中会被拆分成很多小的数据包,这些数据包到达接收端后, 接收端会按照 TCP 头中的序号为其排序,从而保证组成完整的数据
-
断开连接阶段(四次挥手) 可由客户端或者服务器端任何一端发起断开请求 客户端和服务器端都需要是断开就绪状态,才能真正断开。 如:客户端发起断开请求,服务器端确认,返回断开确认信息,客户端处于断开就绪状态。当服务器端处 理完毕,向客户端发送断开请求,客户端返回信息可以断开,服务器端就处于 断开就绪状态,此时客户端和服务器端都是断开就绪状态,则连接断开
-
代码解释
SYN表示建立连接
FIN表示关闭连接
ACK表示响应
PSH表示有 DATA数据传输
RST表示连接重置
wireshark 过滤语句:ip.addr == 127.0.0.1 && ip.dst == 127.0.0.1 && tcp.port == 53100
4.3 TCP数据传输的特点
TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议
-
对于数据包丢失的情况,TCP 提供重传机制;
-
TCP 引入了数据包排序机制,用来保证把乱序的数据包组合成一个完整的文件。
3.27 http
1. http 0.9
下面我们就来看看 HTTP/0.9 的一个完整的请求流程(可参考下图)。
因为 HTTP 都是基于 TCP 协议的,所以客户端先要根据 IP 地址、端口和服务器建立 TCP 连接,而建立连接的过程就是 TCP 协议三次握手的过程。
建立好连接之后,会发送一个 GET 请求行的信息,如GET /index.html用来获取 index.html。
服务器接收请求信息之后,读取对应的 HTML 文件,并将数据以 ASCII 字符流返回给客户端。
HTML 文档传输完成后,断开连接。
HTTP/0.9 请求流程总的来说,当时的需求很简单,就是用来传输体积很小的 HTML 文件,所以 HTTP/0.9 的实现有以下三个特点。
第一个是只有一个请求行,并没有 HTTP 请求头和请求体,因为只需要一个请求行就可以完整表达客户端的需求了。
第二个是服务器也没有返回头信息,这是因为服务器端并不需要告诉客户端太多信息,只需要返回数据就可以了。
第三个是返回的文件内容是以 ASCII 字符流来传输的,因为都是 HTML 格式的文件,所以使用 ASCII 字节码来传输是最合适的。
2. http 1.0
第一个:支持多种类型、格式、编码、语言的文件,添加请求头和响应头
请求头的信息告诉服务器浏览器期望返回的数据的类型、压缩格式、编码类型、语言类型,响应头告诉浏览器我当前返回的数据类型、压缩格式、编码类型、语言类型,因为可能浏览器需要的服务器做不到
accept: text/html; accept-encoding: gzip, deflate, br; accept-Charset: ISO-8859-1,utf-8; accept-language: zh-CN,zh;
content-encoding: brcontent-type: text/html; charset=UTF-8
第二个:有的请求服务器可能无法处理,或者处理出错,这时候就需要告诉浏览器服务器最终处理该请求的情况,这就引入了状态码。状态码是通过响应行的方式来通知浏览器的。
第三个:为了减轻服务器的压力,在 HTTP/1.0 中提供了 Cache 机制,用来缓存已经下载过的数据。
第四个:服务器需要统计客户端的基础信息,比如 Windows 和 macOS 的用户数量分别是多少,所以 HTTP/1.0 的请求头中还加入了用户代理的字段。
3. http 1.1
第一个:tcp持久连接,多个http请求可以在同一个tcp连接上进行。只要浏览器或者服务器没有明确断开连接,那么该 TCP 连接会一直保持。
持久连接在 HTTP/1.1 中是默认开启的Connection: keep-alive,所以你不需要专门为了持久连接去 HTTP 请求头设置信息,如果你不想要采用持久连接,可以在 HTTP 请求头中加上Connection: close。目前浏览器中对于同一个域名,默认允许同时建立 6 个 TCP 持久连接。
第二个:管线化,是指将多个 HTTP 请求整批提交给服务器的技术,虽然可以整批发送请求,不过服务器依然需要根据请求顺序来回复浏览器的请求。
目的是解决队头拥塞问题:持久连接虽然能减少 TCP 的建立和断开次数,但是它需要等待前面的请求返回之后,才能进行下一次请求。如果 TCP 通道中的某个请求因为某些原因没有及时返回,那么就会阻塞后面的所有请求
第三个:提供虚拟主机的支持,HTTP/1.1 的请求头中增加了 Host 字段,用来表示当前的域名地址,这样服务器就可以根据不同的 Host 值做不同的处理。
目的是在 HTTP/1.0 中,每个域名绑定了一个唯一的 IP 地址,因此一个服务器只能支持一个域名。但是随着虚拟主机技术的发展,需要实现在一台物理主机上绑定多个虚拟主机,每个虚拟主机都有自己的单独的域名,这些单独的域名都公用同一个 IP 地址。因此,就需要请求头中增加host字段,让服务器知道对应的是哪个虚拟机
第四个: 对动态生成的内容(文件大小未知)提供了支持,HTTP/1.1 引入 Chunk transfer 机制,服务器会将数据分割成若干个任意大小的数据块,每个数据块发送时会附上上个数据块的长度,最后使用一个零长度的块作为发送数据完成的标志。
目的是在设计 HTTP/1.0 时,需要在响应头中设置完整的数据大小,如Content-Length: 901,这样浏览器就可以根据设置的数据大小来接收数据。不过随着服务器端的技术发展,很多页面的内容都是动态生成的,因此在传输数据之前并不知道最终的数据大小,导致了浏览器不知道何时会接收完所有的文件数据。
第五个:HTTP/1.1 还引入了客户端 Cookie 机制
第六个:补充了缓存的请求头和响应头
4. http 2.0
1. 主要需要解决的问题
第一个:一个域名只使用一个 TCP 长连接
目的:
-
解决tcp有慢启动(刚连接上传输数据慢),减少tcp连接的次数
-
解决针对同一个域名最多可建立6个tcp连接,每个tcp连接都会占用部分带宽资源,且不会按照优先级分配带宽资源,导致需要先加载出来的数据慢返回
第二个:消除队头阻塞问题
http1.1 管线化还是存在对头阻塞问题
2.解决办法:多路复用
-
浏览器发送请求:将请求通过二进制分帧层,分成一帧一帧的数据去传输(一个请求可以分成多个帧,但是每帧具有相同的ID),比如stream1 请求头和请求体分成不同的帧
-
服务器响应请求:服务器接收到所有帧之后,会将所有相同 ID 的帧合并为一条完整的请求信息,并将处理的响应行、响应头和响应体分别发送至二进制分帧层,返回时可以按照请求优先级(如script标签优先级高于图片)或者响应的速度(如stream1响应头有缓存)返回帧数据
-
浏览器接受数据:浏览器接收到响应帧之后,会根据 ID 编号将帧的数据提交给对应的请求
3. http2.0 特性
-
多路复用
-
一个域名只使用一个 TCP 长连接
-
消除队头阻塞问题
-
-
可以设置请求的优先级
-
解决服务器接收到数据,先处理优先级高的数据
-
-
服务器推送
-
服务器知道该 HTML 页面会引用几个重要的 JavaScript 文件和 CSS 文件,那么在接收到 HTML 请求之后,附带将要使用的 CSS 文件和 JavaScript 文件一并发送给浏览器,这样当浏览器解析完 HTML 文件之后,就能直接拿到需要的 CSS 文件和 JavaScript 文件
-
-
头部压缩
-
HTTP/2 对请求头和响应头进行了压缩
-
5. http状态码
5.1 http状态码分类
1XX系列:指定客户端应相应的某些动作,代表请求已被接受,需要继续处理。
2XX系列:代表请求已成功被服务器接收、理解、并接受。如:200
3XX系列:代表需要客户端采取进一步的操作才能完成请求,这些状态码用来重定向 如:302
4XX系列:表示请求错误。如404
5xx系列:代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬 件资源无法完成对请求的处理。常见有500、503状态码。
5.2 http常用状态码
2开头 (请求成功)表示成功处理了请求的状态代码。
- 200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
3开头 (请求被重定向)表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。
- 301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时, 会自动将请求者转到新位置。
- 302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
- 304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
4开头 (请求错误)这些状态代码表示请求可能出错,妨碍了服务器的处理。
- 403 (禁止) 服务器拒绝请求。
- 404 (未找到) 服务器找不到请求的网页。
5开头(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身 的错误,而不是请求出错。
- 500 (服务器内部错误) 服务器遇到错误,无法完成请求。
- 504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
6. http请求头和响应头
6.1 常用的http请求头
1.Accept
Accept: text/html 浏览器可以接受服务器回发的类型为 text/html。
Accept: / 代表浏览器可以处理所有类型,(一般浏览器发给服务器都是发这个)。
2.Accept-Encoding
Accept-Encoding: gzip, deflate 浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate),(注意:这不是只字符编码)。
3.Accept-Language
Accept-Language:zh-CN,zh;q=0.9 浏览器申明自己接收的语言。
4.Connection
Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。
Connection: close 代表一个Request完成后,客户端和服务器之间用于传输HTTP数据的TCP连接会关闭, 当客户端再次发送Request,需要重新建立TCP连接。
5.Host(发送请求时,该报头域是必需的)
Host:www.baidu.com 请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的。
6.User-Agent
User-Agent:Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36 告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本。
服务端拿到该信息就可以统计用户访问时使用的设备
7.Cookie
Cookie是用来存储一些用户信息以便让服务器辨别用户身份的(大多数需要登录的网站上面会比较常见),比如cookie会存储一些用户的用户名和密码,当用户登录后就会在客户端产生一个cookie来存储相关信息,这样浏览器通过读取cookie的信息去服务器上验证并通过后会判定你是合法用户,从而允许查看相应网页。当然cookie里面的数据不仅仅是上述范围,还有很多信息可以存储是cookie里面,比如sessionid等。
8.content-type: 发送数据的格式,如:application/json get请求一般没有
6.2 常见响应头
1.Cache-Control(对应请求中的Cache-Control)
Cache-Control:private 默认为private 响应只能够作为私有的缓存,不能再用户间共享
Cache-Control:public 浏览器和缓存服务器都可以缓存页面信息。
Cache-Control:must-revalidate 对于客户机的每次请求,代理服务器必须想服务器验证缓存是否过时。
Cache-Control:no-cache 浏览器和缓存服务器都不应该缓存页面信息。
Cache-Control:max-age=10 是通知浏览器10秒之内不要烦我,自己从缓冲区中刷新。
Cache-Control:no-store 请求和响应的信息都不应该被存储在对方的磁盘系统中。
2.Last-Modified
Last-Modified: Dec, 26 Dec 2015 17:30:00 GMT 所请求的对象的最后修改日期(按照 RFC 7231 中定义的“超文本传输协议日期”格式来表示)
3.Etag
ETag: "737060cd8c284d8af7ad3082f209582d" 就是一个对象(比如URL)的标志值,就一个对象而言,比如一个html文件,如果被修改了,其Etag也会别修改,所以,ETag的作用跟Last-Modified的作用差不多,主要供WEB服务器判断一个对象是否改变了。比如前一次请求某个html文件时,获得了其 ETag,当这次又请求这个文件时,浏览器就会把先前获得ETag值发送给WEB服务器,然后WEB服务器会把这个ETag跟该文件的当前ETag进行对比,然后就知道这个文件有没有改变了。
4.Content-Type
Content-Type:text/html;charset=UTF-8 告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
5.Content-Encoding
Content-Encoding:gzip 告诉客户端,服务端发送的资源是采用gzip编码的,客户端看到这个信息后,应该采用gzip对资源进行解码。
6.Date
Date: Tue, 03 Apr 2018 03:52:28 GMT 这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
7.Server
Server:Tengine/1.4.6 这个是服务器和相对应的版本,只是告诉客户端服务器信息。
8.Expires
Expires:Sun, 1 Jan 2000 01:00:00 GMT 这个响应头也是跟缓存有关的,告诉客户端在这个时间前,可以直接访问缓存副本,很显然这个值会存在问题,因为客户端和服务器的时间不一定会都是相同的,如果时间不同就会导致问题。所以这个响应头是没有Cache-Control:max-age=*这个响应头准确的,因为max-age=date中的date是个相对时间,不仅更好理解,也更准确。
9.Connection
Connection:keep-alive 这个字段作为回应客户端的Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,客户端可以继续使用这个tcp连接发送http请求。
10.Access-Control-Allow-Origin
Access-Control-Allow-Origin: * 号代表所有网站可以跨域资源共享,如果当前字段为那么Access-Control-Allow-Credentials就不能为true
Access-Control-Allow-Origin: www.baidu.com 指定哪些网站可以跨域资源共享
11.Access-Control-Allow-Methods
Access-Control-Allow-Methods:GET,POST,PUT,DELETE 允许哪些方法来访问
12.Access-Control-Allow-Credentials
Access-Control-Allow-Credentials: true 是否允许发送cookie。默认情况下,Cookie不包括在CORS请求之中。设为true,即表示服务器明确许可,Cookie可以包含在请求中,一起发给服务器。这个值也只能设为true,如果服务器不要浏览器发送Cookie,删除该字段即可。如果access-control-allow-origin为*,当前字段就不能为true
7.http缓存
7.1 http缓存的作用
-
节省资源,节省流量,节省时间,也就是所谓的优化。
通常情况下通过网络获取内容速度慢成本高,有些响应需要在客户端和服务器之间进行多次往返通信,
这就拖延了浏览器可以使用和处理内容的时间,同时也增加了访问者的数据成本。
通过缓存,使用资源副本,大大减少获取资源时间,
能够减少网络带宽消耗、减少延迟与网络阻塞,同时降低服务器压力,提高服务器性能。
7.2 http缓存两种方式
-
强制缓存
-
协商缓存
7.3 http强制缓存
强制缓存相关响应头
Cache-Control(对应请求中的Cache-Control)
-
max-age=xxx:缓存的内容将在 xxx 秒后失效,这个选项只在 HTTP1.1 可用,并如果和 Last-Modified 一起使用时,优先级较高。
-
no-cache: 在浏览器使用缓存前,会往返对比 ETag,如果 ETag 没变,返回 304,则使用协商缓存。no-cache的目的就是为了防止从缓存中获取过期的资源
-
no-store: 彻底禁用缓存,所有内容都不会被缓存到缓存或临时文件中,禁用协商缓存。
-
public: 所有内容都将被缓存(客户端和代理服务器都可缓存)
-
private: 内容只缓存到私有缓存中(仅客户端可以缓存,代理服务器不可缓存)
-
Expires: Expires:Sun, 1 Jan 2000 01:00:00 GMT 这个响应头也是跟缓存有关的,
告诉客户端在这个时间前,可以直接访问缓存副本,很显然这个值会存在问题,
因为客户端和服务器的时间不一定会都是相同的,如果时间不同就会导致问题。
所以这个响应头是没有Cache-Control:max-age=*这个响应头准确的,
因为max-age=date中的date是个相对时间,不仅更好理解,也更准确。
7.4 http协商缓存
相关请求头和响应头
Etag/If-None-Match:
Etag:
Etag是属于HTTP 1.1属性,它是由服务器(Apache或者其他工具)生成返回给前端,用来帮助服务器控制Web端的缓存验证。 Apache中,ETag的值,默认是对文件的索引节(INode),大小(Size)和最后修改时间(MTime)进行Hash后得到的。
If-None-Match:
当资源过期时,浏览器发现响应头里有Etag,则再次像服务器请求时带上请求头if-none-match(值是Etag的值)。服务器收到请求进行比对,决定返回200或304
Last-Modifed/If-Modified-Since:
Last-Modified:
浏览器向服务器发送资源最后的修改时间
If-Modified-Since:
当资源过期时(浏览器判断Cache-Control标识的max-age过期),发现响应头具有Last-Modified声明,则再次向服务器请求时带上头if-modified-since,表示请求时间。服务器收到请求后发现有if-modified-since则与被请求资源的最后修改时间进行对比(Last-Modified),若最后修改时间较新(大),说明资源又被改过,则返回最新资源,HTTP 200 OK;若最后修改时间较旧(小),说明资源无新修改,响应HTTP 304 走缓存。
-
Last-Modifed/If-Modified-Since的时间精度是秒,而Etag可以更精确。
-
Etag优先级是高于Last-Modifed的,所以服务器会优先验证Etag
-
Last-Modifed/If-Modified-Since是http1.0的头字段
7.5 缓存总流程
3.28 接口请求的几种方式
1. 原生ajax
1.1 ajax是什么?
Ajax的核心是JavaScript对象XmlHttpRequest,XmlHttpRequest使您可以使用
JavaScript向服务器提出请求并处理响应,而不阻塞用户。
通过XMLHttpRequest对象,Web开发人员可以在页面加载以后进行页面的局部更新
1.2 ajax作用是什么?
(1)通过异步模式,提升了用户体验
(2)Ajax可以实现动态不刷新(局部刷新)就是能在不更新整个页面的前提下维护数据。
这使得Web应用程序更为迅捷地回应用户动作,并避免了在网络上发送那些没有改变过的信息
1.3 ajax创建请求步骤
get请求
1. 创建一个对象
2. 设置请求参数
3. 发送请求
4. 监听请求成功后的状态变化
post请求
1. 创建一个对象
2. 设置请求参数
3. 设置请求头
4. 发送请求
5. 监听请求成功后的状态变化
1.4 ajax get和post请求的区别
-
使用Get请求时,参数在URL中显示,而使用Post方式,则不会显示出来
get请求
post请求
-
使用Get请求发送数据量小,Post请求发送数据量大
-
GET请求能够被cache,POST不进行缓存。GET请求能够被保存在浏览器的浏览历史里面(密码等重要数据GET提交,别人查看历史记录,就可以直接看到这些私密数据)
-
GET产生一个TCP数据包;POST产生两个TCP数据包。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
2. axios 请求
2.1 axios 是什么?
Axios 是一个基于 promise 的 HTTP 库,可以用在浏览器和 node.js 中。前端最流行的 ajax 请求库,
react/vue 官方都推荐使用 axios 发 ajax 请求
在浏览器中利用的是XMLHttpRequest对象发送请求
在nodejs中用的是http对象
2.2 axios 特点
1. 基于 promise 的异步 ajax 请求库,支持promise所有的API
2. 浏览器端/node 端都可以使用,浏览器中创建XMLHttpRequests
3. 可以转换请求数据和响应数据,并对响应回来的内容自动转换成 JSON类型的数据
4. 批量发送多个请求
4 异步
4.1 promise
promise是ES6中的一门新技术,是JS中进行异步编程的新解决方案。promise的状态有resolved/rejected两种状态。
可以解决回掉地域问题。回调函数嵌套使用,外部回调函数异步执行结果是嵌套的回调条件。
4.2 事件循环
4.3 宏任务与微任务
4.4 异步解决回掉的方案
4.5 ajax、axios、fetch的区别
4.6 什么是同步和异步
同步:函数执行结束立刻有返回值,函数后面的代码需要等待函数有返回值之后才能执行
function sum (a,b) {
console.log(a+b)
return a+b;
}
sum(1,2);
console.log(1);

异步:函数执行结束需要等待某个条件满足之后才有返回值,函数后面的代码无需等待函数有返回就能执行
setTimeout(function(){
console.log(1)
},1000)
cosnole.log(2)
var btn = docment.querySelector('button');
btn.onclick = function(){
console.log(1)
}
console.log(2)
4.7 javaScript中常用的异步操作
-
定时器 setInterval、settimeout
-
事件
-
ajax请求
-
promise
4.8 V8引擎如何实现异步
4.8.1 事件循环
执行js代码的时候,遇见同步任务,直接推入调用栈中执行,遇到异步任务,将该任务挂起,等到异步任务有返回之后推入到任务队列中,当调用栈中的所有同步任务全部执行完成,将任务队列中的任务按顺序一个一个的推入并执行



4.8.2 定时器
setTimeout(function(){
console.log(1)
},1000)
cosnole.log(2)

4.8.3 Dom事件
var btn = docment.querySelector('button');
btn.onclick = function(){
console.log(1)
}
console.log(2)

浏览器进程。主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
渲染进程。核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中,默认情况下,Chrome 会为每个 Tab 标签创建一个渲染进程。出于安全考虑,渲染进程都是运行在沙箱模式下。
GPU 进程。其实,Chrome 刚开始发布的时候是没有 GPU 进程的。而 GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍的需求。最后,Chrome 在其多进程架构上也引入了 GPU 进程。
网络进程。主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立出来,成为一个单独的进程。
插件进程。主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。
4.8.4 ajax请求
var xhr = new XMLHttpRequest();
xhr.open('GET', 'demo-data', true);
xhr.send();
xhr.onreadystatechange = function (e) {
if (xhr.readyState == 4 && xhr.status == 200) {
console.log(xhr.responseText);
console.log(2);
}
};
console.log(1)

var a = 1;
function sum (a,b) {
console.log(1)
return a+b;
}
sum(1,2);
setTimeout(function(){
console.log(2)
},1000)
cosnole.log(3)
var btn = docment.querySelector('button');
btn.onclick = function(){
console.log(1)
}
console.log(2)
消息队列中的任务类型
-
内部消息类型:输入事件(鼠标滚动、点击、移动)、微任务、文件读写、WebSocket、定时器等。
-
与页面相关的事件:JavaScript执行、解析DOM、样式计算、布局、CSS动画等。
消息队列中的任务分成:
-
宏任务:消息队列中的任务称为宏任务,每个宏任务中都包含了一个微任务队列。
-
微任务:等宏任务中的主要功能都完成后,渲染引擎不急着去执行下一个宏任务,而是执行当前宏任务中的微任务

| 宏任务(macrotask) | 微任务(microtask) | |
|---|---|---|
| 谁发起的 | 宿主(Node、浏览器) | JS引擎 |
| 具体事件 | 1. 执行script标签内部代码 2.setTimeout/setInterval 3. ajax请求 4.postMessageMessageChannel 5. setImmediate,I/O(Node.js) | 1. Promise 2. MutaionObserver 3. Object.observe 4.process.nextTick(Node.js) |
4.8.5 Promise
setTimeout(()=>{console.log(3)},0)
new Promise(function(resolve,reject){
console.log(1);
resolve('fullied')
}).then(function(data){
console.log(data)
})
console.log(2)

4.9 详解回调地狱解决方案
4.9.1 异步回调问题
第一是嵌套调用,下面的任务依赖上个任务的请求结果,并在上个任务的回调函数内部执行新的业务逻辑,这样当嵌套层次多了之后,代码的可读性就变得非常差了。
第二是任务的不确定性,执行每个任务都有两种可能的结果(成功或者失败),所以体现在代码中就需要对每个任务的执行结果做两次判断,这种对每个任务都要进行一次额外的错误处理的方式,明显增加了代码的混乱程度
function ajax(request, resolve, reject) {
var xhr = new XMLHttpRequest();
xhr.open(request.method, request.url, request.sync);
xhr.send();
xhr.onreadystatechange = function (e) {
if (xhr.readyState == 4) {
if (xhr.status == 200) {
resolve(xhr.response)
} else {
reject('error')
}
}
};
}
ajax({ method: 'GET', url: '/1', sync: true }, function (success) {
console.log('success1:' + success)
ajax({ method: 'GET', url: '/2', sync: true }, function (success) {
console.log('success2:' + success)
ajax({ method: 'GET', url: '/3', sync: true }, function (success) {
console.log('success3:' + success)
}, function (error) {
console.log('error:' + error)
})
}, function (error) {
console.log('error:' + error)
})
}, function (error) {
console.log('error:' + error)
})
4.9.2 promise解决问题
第一是消灭嵌套调用;
第二是合并多个任务的错误处理。
function xFetch(request) {
function ajax(resolve, reject) {
var xhr = new XMLHttpRequest();
xhr.open(request.method, request.url, request.sync);
xhr.send();
xhr.onreadystatechange = function (e) {
if (xhr.readyState == 4) {
if (xhr.status == 200) {
resolve(xhr.response)
} else {
reject('error')
}
}
};
}
return new Promise(ajax)
}
var p1 = xFetch({ method: 'GET', url: '/1', sync: true });
var p2 = p1.then(function(success){
console.log(success);
return xFetch({ method: 'GET', url: '/2', sync: true });
})
var p3 = p2.then(function(success){
console.log(success);
return xFetch({ method: 'GET', url: '/3', sync: true });
})
p3.then(function(success){
console.log(success);
})
p3.catch(function(error){
console.log(error)
})
-
首先我们引入了 Promise,在调用 XFetch 时,会返回一个 Promise 对象。
-
构建 Promise 对象时,需要传入一个 ajax 函数,XFetch 的主要业务流程都在 ajax 函数中执行。
-
如果运行在 excutor 函数中的业务执行成功了,会调用 resolve 函数;如果执行失败了,则调用 reject 函数
-
在 excutor 函数中调用 resolve 函数时,会触发 promise.then 设置的回调函数;而调用 reject 函数时,会触发 promise.catch 设置的回调函数。
4.9.3 相关练习题
4.9.4 async await
async await实现是通过Generator(生成器)和promise两种技术
1.生成器函数
Generator 的底层实现机制——协程(Coroutine)
协程是一种比线程更加轻量级的存在。你可以把协程看成是跑在线程上的任务,一个线程上可以存在多个协程,但是在线程上同时只能执行一个协程,比如当前执行的是 A 协程,要启动 B 协程,那么 A 协程就需要将主线程的控制权交给 B 协程,这就体现在 A 协程暂停执行,B 协程恢复执行;同样,也可以从 B 协程中启动 A 协程。通常,如果从 A 协程启动 B 协程,我们就把 A 协程称为 B 协程的父协程。
function* genDemo() {
console.log("开始执行第一段");
yield 'generator 2';
console.log("开始执行第二段");
yield 'generator 2';
console.log("开始执行第三段");
yield 'generator 2';
console.log("执行结束");
return 'generator 2'
}
console.log('main 0');
let gen = genDemo();
console.log(gen.next().value);
console.log('main 1');
console.log(gen.next().value);
console.log('main 2');
console.log(gen.next().value);
console.log('main 3');
console.log(gen.next().value);
console.log('main 4')

2.async
async函数返回一个promise
async function foo(){
return 1
}
console.log(foo())
3.await
async function foo() {
console.log(1);
let a = await 100;
console.log(a);
console.log(2)
}
console.log(0);
foo();
console.log(3)
当执行到await 100时,会默认创建一个 Promise 对象,代码相当于
let promise_ = new Promise((resolve,reject){
resolve(100)
})

4.10 promise

-
promise语法
const p1 = new Promise((reslove,reject)=>{ console.log(2); reslove(1) }).then((data)=>{ console.log(3); }).catch((data)=>{ console.log(3); })
2. 三种状态
pending: 在过程中还没有结果
fulfilled: 已经解决了
rejected:被拒绝了,失败了
3. 状态的变化和表现
(1)状态一旦生成,不会因为后面再调用的resolve或者reject而改变
(2)不执行resolve或者reject就一直是pending状态,pending不会触发then和catch
(3) resolve 方法的参数是then中回调函数的参数
reject 方法中的参数是catch中的参数
(4) Promise.resolve()返回fulfilled状态的promise
Promise.rejetc()返回rejected状态的promise
(5) then 和 catch 只要不报错,返回的都是一个fullfilled状态的promise
4.11 promise.all
4.11.1 promise.all基本使用
-
promise.all 基本语法
Promise.all([p1, p2]).then((result) => { console.log(result) }).catch((error) => { console.log(error) }) -
promise特点
-
Promise.all可以将多个Promise实例包装成一个新的Promise实例
-
当参数中的所有promise全部成功时返回成功结果,且结果是所有promise返回成功结果的数组
-
只要数组中有一个promise失败,则返回失败,结果是第一个失败的promise的值
-
-
使用场景: 如果有一个接口需要等待,页面上两个接口都返回数据才调用,有一个失败就不调用的情况
4.11.2 手写promise.all
思路:
1、接收一个 Promise 实例的数组或具有 Iterator 接口的对象,
2、遍历每一个数组元素,如果元素不是 Promise 对象,则使用 Promise.resolve 转成 Promise 对象
3、如果全部成功,状态变为 resolved,返回值将组成一个数组传给回调
4、只要有一个失败,状态就变为 rejected,返回值将直接传递给回调all()
的返回值也是新的 Promise 对象
function promiseAll(promises) {
return new Promise(function (resolve, reject) {
if (!Array.isArray(promises)) {
return reject(new TypeError('arguments must be an array'));
}
var resolvedCounter = 0;
var promiseNum = promises.length;
var resolvedValues = new Array(promiseNum);
for (let i = 0; i < promiseNum; i++) {
Promise.resolve(promises[i]).then(function (value) {
resolvedCounter++
resolvedValues[i] = value
if (resolvedCounter == promiseNum) {
return resolve(resolvedValues)
}
}, function (reason) {
return reject(reason)
})
}
})
}
4.12 promise.race
4.12.1 基本使用
-
基本语法
Promise.race([p1, p2]).then((result) => { console.log(result) }).catch((error) => { console.log(error) // 打开的是 'failed' }) -
特点:Promise.race([p1, p2, p3])里面哪个结果获得的快,就返回那个结果,不管结果本身是成功状态还是失败状态
4.12.2 手写promise.race
思路:
返回一个创建的promise,在该promise的then中遍历每一个数组元素,并且当
某个元素有返回,直接执行创建的promise的resolve/reject
function promiseRace(promises) {
if (!Array.isArray(promises)) {
throw new Error("promises must be an array")
}
return new Promise(function (resolve, reject) {
promises.forEach(p =>
Promise.resolve(p).then(data => {
resolve(data)
}, err => {
reject(err)
})
)
})
}
4.13 async await
4.13.1 基本语法
async function async1(){
console.log('async1 start');
await async2();
console.log('async1 end');
}
4.13.2 特点
-
await关键字只能在async函数中使用
-
await 后面跟着的应该是一个promise对象
-
await 表示在这里等待promise返回结果了,再继续执行。
-
await 相当于promise的then情况,所以promise返回catch没办法处理,所以捕获问题需要配合trycatch使用
5 浏览器的运行机制
5.1浏览器运行原理
1. 浏览器内部构造
-
用户界面 - 包括地址栏、前进/后退按钮、书签菜单等。除了浏览器主窗口显示的您请求的页面外,其他显示的各个部分都属于用户界面。
-
浏览器引擎 - 在用户界面和呈现引擎之间传送指令。
-
渲染引擎 - 负责显示请求的内容。如果请求的内容是 HTML,它就负责解析 HTML 和 CSS 内容,并将解析后的内容显示在屏幕上。
-
网络 - 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
-
用户界面后端 - 用于绘制基本的窗口小部件,比如组合框和窗口。其公开了与平台无关的通用接口,而在底层使用操作系统的用户界面方法。
-
JavaScript 解释器。用于解析和执行 JavaScript 代码。
-
数据存储。这是持久层。浏览器需要在硬盘上保存各种数据,例如 Cookie。新的 HTML 规范 (HTML5) 定义了“网络数据库”,这是一个完整(但是轻便)的浏览器内数据库。

2. 浏览器的进程
进程和线程
-
进程:一个进程就是一个程序的运行实例。详细解释就是,启动一个程序的时候,操作系统会为该程序创建一块内存,用来存放代码、运行中的数据和一个执行任务的主线程,我们把这样的一个运行环境叫进程。
-
线程:程序执行的最小单位

-
进程和线程的关系:线程是依附于进程的,而进程中使用多线程并行处理能提升运算效率
-
进程和线程特点:
-
关联性:
-
线程中某个任务报错,阻止后面任务执行
-
进程中的任意一线程执行出错,都会导致整个进程的崩溃。
-
一个程序有多个进程,其中一个崩溃不影响其他进程。
-
-
当一个进程关闭之后,操作系统会回收进程所占用的内存。
-
数据共享:线程之间共享进程中的数据 进程之间的内容相互隔离。
-
浏览器进程
现代浏览器是多进程,每个标签页都是一个独立的渲染进程,比如写一个死循环,只有当前页面崩溃

-
浏览器进程:主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
-
渲染进程:核心任务是将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,排版引擎 Blink 和 JavaScript 引擎 V8 都是运行在该进程中,默认情况下,Chrome 会为每个 Tab 标签创建一个渲染进程。
-
GPU 进程:其实,Chrome 刚开始发布的时候是没有 GPU 进程的。而 GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍的需求。最后,Chrome 在其多进程架构上也引入了 GPU 进程。
-
网络进程:主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,直至最近才独立出来,成为一个单独的进程。
-
插件进程。主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响
3. 渲染进程
渲染进程的核心工作是将HTML,CSS和JavaScript转换为用户可以与之交互的网页。主要包括以下线程:
3.1 浏览器 GUI 渲染线程
渲染流程

-
分层的目的:避免整个页面渲染,把页面分成多个图层,尤其是动画的时候,把动画独立出一个图层,渲染时只渲染该图层就ok,transform,z-index等,浏览器会自动优化生成图层
-
光栅化:页面如果很长但是可视区很小,避免渲染非可视区的样式造成资源浪费,所以将每个图层又划分成多个小个子,当前只渲染可视区附近区域
重排
-
重排 :当DOM的变化影响了元素的几何信息(元素的的位置和尺寸大小),浏览器需要重新计算元素的几何属性,将其安放在界面中的正确位置,这个过程叫做重排
-
重排特点:style后面所有流程都更新

-
触发重排的方法
-
页面初始渲染,这是开销最大的一次重排
-
添加/删除可见的DOM元素
-
改变元素位置
-
改变元素尺寸,比如边距、填充、边框、宽度和高度等
-
改变元素内容,比如文字数量,图片大小等
-
改变元素字体大小
-
改变浏览器窗口尺寸,比如resize事件发生时
-
激活CSS伪类(例如:
:hover) -
设置 style 属性的值,因为通过设置style属性改变结点样式的话,每一次设置都会触发一次reflow
查询某些属性或调用某些计算方法:offsetWidth、offsetHeight等
-
重绘
-
重绘:当一个元素的外观发生改变,但没有改变布局,重新把元素外观绘制出来的过程
-
重绘特点:跳过布局和分层阶段

-
重排必重绘
避免重排的方法
-
样式集中改变
// bad var left = 10; var top = 10; el.style.left = left + "px"; el.style.top = top + "px"; // 当top和left的值是动态计算而成时... // better el.style.cssText += "; left: " + left + "px; top: " + top + "px;"; // better el.className += " className";
-
使用 absolute 或 fixed 脱离文档流
使用绝对定位会使的该元素单独成为渲染树中
body的一个子元素,重排开销比较小,不会对其它节点造成太多影响。当你在这些节点上放置这个元素时,一些其它在这个区域内的节点可能需要重绘,但是不需要重排 -
GPU加速:transform
/* * 根据上面的结论 * 将 2d transform 换成 3d * 就可以强制开启 GPU 加速 * 提高动画性能 */ div { transform: translate3d(10px, 10px, 0); }
3.2 JavaScript 引擎线程
JS引擎线程负责解析Javascript脚本,运行代码 JS引擎一直等待着任务队列中任务的到来,然后加以处理,一个Tab页(renderer进程)中无论什么时候都只有一个JS线程在运行JS程序
GUI渲染线程与JS引擎线程是互斥的,所以如果JS执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞
3.3 浏览器定时触发器线程
浏览器定时计数器并不是由 JavaScript 引擎计数的, 因为 JavaScript 引擎是单线程的, 如果处于阻塞线程状态就会影响记计时的准确, 因此通过单独线程来计时并触发定时是更为合理的方案
3.4 浏览器事件触发线程
当一个事件被触发时该线程会把事件添加到待处理队列的队尾,等待 JavaScript 引擎的处理。这些事件可以是当前执行的代码块如定时任务、也可来自浏览器内核的其他线程如鼠标点击、AJAX 异步请求等,但由于 JavaScript 的单线程关系所有这些事件都得排队等待 JavaScript 引擎处理。
3.5 浏览器 http 异步请求线程
在 XMLHttpRequest 在连接后是通过浏览器新开一个线程请求, 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件放到 JavaScript 引擎的处理队列中等待处理。
5.2 浏览器调试工具
5.2.1 打开方式
-
如果要使用DOM或CSS,请右键单击页面上的元素,然后选择“检查”以跳到“元素”面板。或按Command + Option + C(Mac)或Control + Shift + C(Windows,Linux,Chrome操作系统)。
-
当您想查看记录的消息或运行JavaScript时,请按Command + Option + J(Mac)或Control + Shift + J(Windows,Linux,Chrome OS)直接跳至“控制台”面板。
5.2.2 调试样式
1. 选择元素

2. 样式来源

3. 查看当前作用在元素上的样式且按照字母顺序进行排序

4. 查看伪类样式

5. 查看重绘和回流

6. 查看css样式利用率

7. 给元素添加类

8. 动画调试

5.2.3 js调试
1. 打印
-
console.log('log'); -
console.dir(document.head);
-
console.table([ { first: 'René', last: 'Magritte', }, { first: 'Chaim', last: 'Soutine', birthday: '18930113', }, { first: 'Henri', last: 'Matisse', } ]); -
console.clear();
-
console.dirxml(document);
-
console.error("I'm sorry, Dave. I'm afraid I can't do that."); -
const label = 'Adolescent Irradiated Espionage Tortoises'; console.group(label); console.info('Leo'); console.info('Mike'); console.info('Don'); console.info('Raph'); console.groupEnd(label); -
console.time(); for (var i = 0; i < 100000; i++) { let square = i ** 2; } console.timeEnd(); -
console.warn('warn');
2. 实用API
-
$_返回最近求值的表达式的值。1+2 $_ // 3 ['lucy','yellow','green'] ["lucy", "yellow", "green"] $_.length 3
-
在“元素”面板中选择了一个元素。在控制台中,
$0并显示相同的元素

-
$(selector)使用指定的CSS选择器返回对第一个DOM元素的引用。当使用一个参数调用时,此函数是document.querySelector()函数的别名

-
$$()相当于document.querySelectorAll()

-
getEventListeners(document); 返回已注册在document元素上的所有事件

-
keys(object)返回一个数组,其中包含属于指定对象的属性的名称
-
监听函数的执行

-
监听指定事件的执行 monitorEvents(window, "resize");
-
停止监听unmonitorEvents(window);

-
queryObjects(Promise)。返回所有promise。 -
queryObjects(HTMLElement)。返回所有HTML元素。 -
queryObjects(foo),其中foo是函数名称。返回通过实例化的所有对象new foo()。
5.2.4 网络请求
-
查看请求
-
跨页之后不清空请求
-
禁止http缓存
-
模拟网络状态
-
查看请求个数,请求的大小,用时

-
显示资源压缩前的大小

-
针对请求相关设置

-
查看每个时间段页面的状态

5.3 v8引擎如何运行代码

1.第一步 生成AST语法树
第一阶段是分词(tokenize),又称为词法分析,其作用是将一行行的源码拆解成一个个 token。所谓 token,指的是语法上不可能再分的、最小的单个字符或字符串。你可以参考下图来更好地理解什么 token。

第二阶段是解析(parse),又称为语法分析,其作用是将上一步生成的 token 数据,根据语法规则转为 AST。如果源码符合语法规则,这一步就会顺利完成。但如果源码存在语法错误,这一步就会终止,并抛出一个“语法错误”。这就是 AST 的生成过程,先分词,再解析。

2.第二步 生成字节码
有了 AST 和执行上下文后,那接下来的第二步,解释器 Ignition 就登场了,它会根据 AST 生成字节码,并解释执行字节码。
字节码就是介于 AST 和机器码之间的一种代码。但是与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行。
在 V8 中,字节码有三个作用:
第一个是解释器可以直接解释执行字节码 ;
第二个是优化编译器可以将字节码编译为二进制代码,然后再执行二进制机器代码。
第三个是字节码是平台无关的,机器码针对不同的平台都是不一样的

3.第三步 执行代码
生成字节码之后,接下来就要进入执行阶段,如果有一段第一次执行的字节码,解释器 Ignition 会逐条解释执行
解释器 Ignition(点火)作用
-
负责生成字节码之外
-
解释执行字节码
注意:
在 Ignition 执行字节码的过程中,如果发现有热点代码(HotSpot),比如一段代码被重复执行多次,这种就称为热点代码,那么后台的编译器 TurboFan(涡轮发动机) 就会把该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就大大提升了代码的执行效率
5.4 输入一个url到页面展示出来经历了什么
-
输入网址,发送到DNS服务器,并获取域名对应的Web服务器对应的ip地址;
-
与web服务器建立起TCP链接;
-
浏览器向服务器发送http请求
-
web服务器响应请求,并返回指定URL的数据(或错误信息,或重定向的新的url地址)
-
浏览器下载web服务器返回的数据及解析html源文件
-
生成dom树,解析css和js,渲染页面,指导显示完成

6 vue
6.1 vue2和vue3区别
-
双向数据绑定原理发生了改变。
vue2的双向数据绑定是利用ES5的一个API,Object.definePropert()对数据进行劫持,结合发布订阅模式来实现的。
vue3使用了ES6的ProxyAPI对数据代理。
-
vue3支持碎片化
vue3组件可以拥有多个根节点。
-
composition API
vue2分割了不同的属性:data、computed、methods等;vue3相比于旧的API使用属性来分组,这样代码更加简便和整洁。
-
建立data
vue2把数据放入data属性中
vue3使用使用一个setup()方法,此方法在组件初始化构造的时候触发
-
生命周期函数
6.父子传参不同,setup()函数特性
6.2 vue响应式——双向数据绑定原理
-
vue响应式指的是:组件的data发生变化,立刻触发试图的更新
-
原理:
-
Vue 采用数据劫持结合发布者-订阅者模式的方式来实现数据的响应式,通过Object.defineProperty来劫持数据的setter,getter,在数据变动时发布消息给订阅者,订阅者收到消息后进行相应的处理。
-
通过原生js提供的监听数据的API,当数据发生变化的时候,在回调函数中修改dom
-
核心API:Object.defineProperty
-
-
简单API:Object.defineProperty的使用
-
作用: 用来定义对象属性
-
特点:
-
默认情况下定义的数据的属性不能修改
-
描述属性和存取属性不能同时使用,使用会报错
-
-
响应式原理:
-
获取属性值会触发getter方法
-
设置属性值会触发setter方法
-
在setter方法中调用修改dom的方法
-
-
-
如何实现的监听数组
-
嵌套对象,如何实现深度监听
-
Object.defineProperty的几个缺点
6.3 keep-alive
-
默认情况下加在keepalive标签中的组件都会进行缓存
-
为了区别缓存哪些组件的方法
给keepalive 添加属性,组件名称指的是具体组件添加的name,不是路由里面的name
include 包含的组件(可以为字符串,数组,以及正则表达式,只有匹配的组件会被缓存)
exclude 排除的组件(以为字符串,数组,以及正则表达式,任何匹配的组件都不会被缓存)
最常用的方式:和路由配合使用:在路由中添加meta属性,美团项目App.vue
-
keepalive作用:提升性能,避免重复加载一些不需要经常变动且内容较多的组件
-
使用keepalive导致组件不重新加载,也就不会重新执行生命周期的函数,如果要解决这个问题,就需要两个属性进入时触发:activated 退出时触发:deactivated
6.4 vue生命周期

6.5路由
6.5.1 router的使用方式
-
在router/index.js的文件中引入vue-router,Vue.use(VueRouter)
-
new VueRouter 导出
-
创建vue实例的地方,引入router
-
在具体的页面中使用router-link标签 :to属性配置path或者name query或者 params
-
使用router-view标签展示link的链接的组件
6.5.2 router跳转+传参
1 路由跳转的四种方式
<router-link to="/home"> </router-link>
<router-link :to="{name:'home'}"> </router-link>
<router-link :to="{path:'/home'}"></router-link>
this.$router.push('/home')
this.$router.push({name:'home'})
this.$router.push({path:'/home'})
this.$router.replace() // (用法同上,push)
this.$router.go(n) // n是n可为正整数或负整数
2 路由传参的三种方式
-
路径带?key=value
<router-link to="/about?id=1">About</router-link>
-
query 相当于get
<router-link :to="{path:'/query',query:{id:12}}">带参数query</router-link> -
params 相当于post
<router-link :to="{name:'Params',params:{id:11}}">带参数params</router-link>
3 获取路由参数的方法
// 路径传参和query属性传参,都用该方式获取参数 this.$route.query.val // params属性传参,用该方式获取 this.$route.params.val
6.5.3 动态路由
作用:多个路由对应同一个组件,根据路由配置id不同,获取不同参数,进行相应处理
6.5.4 路由嵌套
作用:一个页面某个位置根据链接不同,展示不同的组件,例如项目中的店家
展示默认子路由方法:在嵌套路由父路由中添加redirect属性,值为子路由的值
redirect: '/childrouter',
6.5.5 路由懒加载/ 按需加载
作用:性能优化:不用到该路由,不加载该组件
ES6的impot方式:
component: () => import(/* webpackChunkName: "about" */ '../views/About.vue'),
VUE中的异步组件进行懒加载方式:
component: resolve=>(require(['../views/About'],resolve))
6.6 v-show和v-if的区别
-
作用: 都是控制元素隐藏和显示的
-
区别:
-
v-show: 控制的元素无论是true还是false,都被渲染出来了,通过display:none控制元素隐藏
-
v-if: 控制的元素是true,进行渲染,如果是false不渲染,根本在dom树结构中不显示
-
-
应用:
-
v-show: 适合使用在切换频繁显示/隐藏的元素上
-
v-if: 适合使用在切换不频繁,且元素内容很多,渲染一次性能消耗很大的元素上
-
6.7 v-for为什么要加key
v-for 为什么一定要加key,且key要不同
-
加key是为了给元素添加唯一标识,因为vue是虚拟dom,用diff算法对节点进行一一比对,要修改哪个元素,这个元素一定要有一个唯一标识,为了性能优化,比如修改了原数组,没有给li上加key,那么在进行运算的时候,就重新将整体渲染一遍,但是如果有key,那么它就会按照key找到修改内容的那个li元素,改掉它自己,不需要对其他元素进行修改

-
key为什么不能是index,因为假设我们给数组前插入一个新元素,它的下标是0,那么和原来的第一个元素重复了,整个数组的key都发生了改变,这样就跟没有key的情况一样了

6.8 data为什么是函数
vue组件中data值不能为对象,因为对象是引用类型,组件可能会被多个实例同时引用。如果data值为对象,将导致多个实例共享一个对象,其中一个组件改变data属性值,其它实例也会受到影响
data是一个函数的话,这样每复用一次组件,就会返回一份新的data,类似于给每个组件实例创建一个私有的数据空间,让各个组件实例维护各自的数据。而单纯的写成对象形式,就使得所有组件实例共用了一份data,就会造成一个变了全都会变的结果。
所以说vue组件的data必须是函数。这都是因为js的特性带来的,跟vue本身设计无关。
6.9 为什么style标签中加scoped属性
区分样式的作用域,原理是加上scoped就会给当前组件添加上自定义属性,同时选择器上会添加自定义属性进行样式设置

6.10 computed和watch的区别
computed中的方法只有依赖的数据发生改变的时候才会执行,且计算结果会缓存起来。
watch主要用来监听某些特定数据的变化,从而进行某些具体的业务逻辑操作,可以看作是computed和methods的结合体。
6.10.1 computed
-
初始化显示或者相关的 data、props 等属性数据发生变化的时候调用;
-
将复杂的计算逻辑从模板中抽离出来,使模板变得更加简洁
-
计算属性不在 data 中,它是基于data 或 props 中的数据通过计算得到的一个新值,这个新值根据已知值的变化而变化;
-
在 computed 属性对象中定义计算属性的方法,和取data对象里的数据属性一样,以属性访问的形式调用;
-
computed中的方法只有依赖的数据发生改变的时候才会执行,且计算的结果会缓存起来,更像是input的keyup事件,获取到value值进行比对之后再触发
-
在computed中的,属性都有一个 get 和一个 set 方法,当数据变化时,调用 set 方法
6.10.2 watch
-
主要用来监听某些特定数据的变化,从而进行某些具体的业务逻辑操作,可以看作是 computed 和 methods 的结合体;
-
可以监听的数据来源:data,props,computed内的数据;
-
watch支持异步;
-
不支持缓存,监听的数据改变,直接会触发相应的操作;更像是input的change事件,输入就触发,不比对
-
监听函数有两个参数,第一个参数是最新的值,第二个参数是输入之前的值,顺序一定是新值,旧值。
总结:
computed: 是计算属性,依赖其它属性值,并且 computed 的值有缓存,只有它依赖的属性值发生改变,下一次获取 computed 的值时才会重新计算 computed 的值;
watch: 更多的是「观察」的作用,类似于某些数据的监听回调 ,每当监听的数据变化时都会执行回调进行后续操作;
运用场景:
-
当我们需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时,都要重新计算;
-
当我们需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许我们执行异步操作 ( 访问一个 API ),限制我们执行该操作的频率,并在我们得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
6.11 组件传值
6.11.1 父子组件
1. 父子组件使用
-
import引入
-
components中注入
-
在template中上写子组件标签
-
2 父子组件传值方式
-
父亲给子组件传递数据或者方法: 在组件上<List :list="list" @delete="deleteHandler"/>
-
子组件使用父亲传递的数据:props属性,调用父组件传递的方法this.$emit('方法名',参数)
props是只读,不可以被修改,所有被修改都会失效和被警告
6.11.2 不相关两个组件或者兄弟组件通信:emit发布 ,on接受
event.$emit('名称',参数)
event.$on('名称',方法)
event
6.12 请求放在哪个生命周期
为什么不在 created 里去发ajax?created 可是比 mounted 更早调用啊,更早调用意味着更早返回结果,那样性能不是更高?
1. 一个组件的 created 比 mounted 也早调用不了几微秒,性能没啥提高;
2. 等到异步渲染开启的时候,created 就可能被中途打断,中断之后渲染又要重做一遍,
在 created 中做ajax调用,代码里看到只有调用一次,但是实际上可能调用 N 多次,这明显不合适。
3. 若把发ajax 放在 mounted,因为 mounted 在第二阶段,所以绝对不会多次重复调用,这才是ajax合适的位置.
4. 在created的时候,视图中的dom并没有被渲染出来,所以此时如果直接去操作dom节点,无法找到相关元素。
在mounted中,由于此时的dom元素已经渲染出来了,所以可以直接使用dom节点。
一般情况下,都放在mounted中,保证逻辑的统一性。因为生命周期是同步执行的,ajax是异步执行的。
服务端渲染不支持mounted方法,所以在服务端渲染的情况下统一放在created中。
6.13 $nexttick的作用
在钩子函数created()里面想要获取dom的内容或者操作dom,但是这个时候只是虚拟dom,实际dom操作不了,所以在这里可以用this.$nextTick(),这样等dom更新完了再执行this.$nextTick()里面的回调,这样就可以操作或者获取dom的内容了
6.14 vuex基本使用方法
1 vuex的作用
集中管理项目公共数据
2 本来就是单页面应用,为什么不创建一个全局变量来代替vuex
-
Vuex 的状态存储是响应式的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
-
不能直接改变 store 中的状态。改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样使得我们可以方便地跟踪每一个状态的变化,从而让我们能够实现一些工具帮助我们更好地了解我们的应用
3 使用方法
-
和vue-router使用方式一样,先引入,再use,然后new vuex.store实例,然后将该实例注入到Vue实例中
-
创建数据 state
state: {
count: 0
},
-
获取state中数据的方式
a.直接在虚拟dom上使用{{$store.state.count}}
b.在computed中定义方法,返回this.$store.state.count
在页面{{函数名称}}
c.批量获取state中的数据
-
修改state数据 mutations 和 commit
在mutations中定义方法没使用this.$store.commit('方法名称',参数)修改state中的数据
...mapMutation获取多个方法
注意:不要在mutation中的方法中写异步方法:ajax,那样数据就不可跟踪了
-
getters : 如果state中的数据需要有被处理过的,我们需要一个固定处理数据的方法,同时这个方法保证,state中的数据发生改变,他就跟着改变,类似与computed方法
-
Action : 定义调用mutations中方法的方法,为了能在改变state中值之前使用一些异步方法
6.15 虚拟dom和diff算法
6.15.1 虚拟dom和diff算法
-
虚拟dom(Virtual dom)是实现vue和React的核心
-
diff算法是vdom中最核心最关键的部分
6.15.2 虚拟dom解决的问题
-
真实的dom操作相当耗性能:操作一次dom触发一次渲染,渲染耗时
-
以前面试题将常考使用jquery或者原生js操作dom时,如何做性能优化:将多条dom操作合并成一条
-
vue和react都是数据驱动视图,如何控制dom操作? 使用vdom
6.15.3 虚拟dom如何解决的问题
-
js计算要比dom渲染速度快
-
vdom使用js模拟dom结构,计算出最小的变更,操作dom
6.15.4 虚拟dom如何模拟dom结构 (手写虚拟dom树)
<div class='vdom' id='first'>
<p>内容</p>
<ul>
<li>1</li>
<li>2</li>
</ul>
</div>
{
tag: 'div',
data: {
className: 'vdom',
id: 'first'
},
children: [
{
tag: 'p',
children: '内容'
},
{
tag: 'ul',
children: [
{
tag: 'li',
children: '1'
},
{
tag: 'li',
children: '2'
}
]
}
]
}
6.15.5 从源码角度分析虚拟dom视图更新过程
-
调用init方法,返回一个patch函数,init方法的参数是一个数组,数组中是各种模块,根据传入的模块定制化patch函数
-
使用h函数返回生成vnode的方法
-
调用render生成真实的虚拟dom
-
调用
init方法会返回一个patch函数,这个函数接受两个参数,第一个是旧的vnode节点或是dom节点,第二个参数是新的vnode节点,调用patch函数会对 dom 进行更新。
6.15.6 vue中虚拟dom比较流程(diff算法)
1 vue中虚拟dom比较流程
-
第一步:patch函数中对新老节点进行比较
-
如果新节点不存在就销毁老节点
-
如果老节点不存在,直接创建新的节点
-
当两个节点是相同节点的时候,进入 patctVnode 的过程,比较两个节点的内部
// 用于 比较 新老节点的不同,然后更新的 函数 function patch (oldVnode, vnode, hydrating, removeOnly) { // 1. 当新节点不存在的时候,销毁旧节点 if (isUndef(vnode)) { if (isDef(oldVnode)) invokeDestroyHook(oldVnode) return } let isInitialPatch = false // 用来存储 insert 钩子函数,在 插入节点之后调用 const insertedVnodeQueue = [] // 2. 如果旧节点 是未定义的,直接创建新节点 if (isUndef(oldVnode)) { isInitialPatch = true createElm(vnode, insertedVnodeQueue) } else { const isRealElement = isDef(oldVnode.nodeType) // 当老节点不是真实的 dom 节点, 当两个节点是相同节点的时候,进入 patctVnode 的过程 // 而 patchVnode 也是 传说中 diff updateChildren 的调用者 if (!isRealElement && sameVnode(oldVnode, vnode)) { // patch existing root node patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly) } else { // 当老节点是真实存在的 dom 节点的时候 if (isRealElement) { // 当 老节点是 真实节点,而是在 ssr 环境的时候,修改 SSR_ATTR 属性 if (oldVnode.nodeType === 1 && oldVnode.hasAttribute(SSR_ATTR)) { oldVnode.removeAttribute(SSR_ATTR) hydrating = true } .... // 设置 oldVnode 为一个包含 oldVnode 的无属性节点 oldVnode = emptyNodeAt(oldVnode) } // replacing existing element const oldElm = oldVnode.elm // 获取父亲节点,这样方便 删除或者增加节点 const parentElm = nodeOps.parentNode(oldElm) // 在 dom 中插入新节点 createElm( vnode, insertedVnodeQueue, oldElm._leaveCb ? null : parentElm, nodeOps.nextSibling(oldElm) ) // 递归 更新父占位符元素 // 就是执行一遍 父节点的 destory 和 create 、insert 的 钩子函数 // 类似于 style 组件,事件组件,这些 钩子函数 if (isDef(vnode.parent)) { let ancestor = vnode.parent const patchable = isPatchable(vnode) while (ancestor) { for (let i = 0; i < cbs.destroy.length; ++i) { cbs.destroy[i](ancestor) } ancestor.elm = vnode.elm if (patchable) { for (let i = 0; i < cbs.create.length; ++i) { cbs.create[i](emptyNode, ancestor) } const insert = ancestor.data.hook.insert if (insert.merged) { for (let i = 1; i < insert.fns.length; i++) { insert.fns[i]() } } } else { registerRef(ancestor) } ancestor = ancestor.parent } } // 销毁老节点 if (isDef(parentElm)) { removeVnodes([oldVnode], 0, 0) } else if (isDef(oldVnode.tag)) { // 触发老节点 的 destory 钩子 invokeDestroyHook(oldVnode) } } } // 执行 虚拟 dom 的 insert 钩子函数 invokeInsertHook(vnode, insertedVnodeQueue, isInitialPatch) // 返回最新 vnode 的 elm ,也就是真实的 dom节点 return vnode.elm }如何判断两个节点是否相同?key、tagName、标签属性、input标签还要比较type类型
function sameVnode (a, b) { return ( a.key === b.key && // key值 a.tag === b.tag && // 标签名 a.isComment === b.isComment && // 是否为注释节点 // 是否都定义了data,data包含一些具体信息,例如onclick , style isDef(a.data) === isDef(b.data) && sameInputType(a, b) // 当标签是<input>的时候,type必须相同 ) }function sameInputType (a, b) { if (a.tag !== 'input') { return true } var i; var typeA = isDef(i = a.data) && isDef(i = i.attrs) && i.type; var typeB = isDef(i = b.data) && isDef(i = i.attrs) && i.type; return typeA === typeB || isTextInputType(typeA) && isTextInputType(typeB) } -
-
第二步:patchVnode函数比较两个虚拟节点内部
-
如果两个虚拟节点完全相同,返回
-
当前vnode 的children 不是textNode,再分成三种情况
-
有新children,没有旧children,创建新的
-
没有新children,有旧children,删除旧的
-
新children、旧children都有,执行
updateChildren比较children的差异,这里就是diff算法的核心
-
-
当前vnode 的children 是textNode,直接更新text
function patchVnode ( oldVnode, // 旧节点 vnode, // 新节点 insertedVnodeQueue, // 插入节点的队列 ownerArray, // 节点 数组 index, // 当前 节点的 removeOnly // 只有在 patch 函数中被传入,当老节点不是真实的 dom 节点,当新老节点是相同节点的时候 ) { // 如果新节点和旧节点 相等(使用了 同一个地址,直接返回不进行修改) // 这里就是 当 props 没有改变的时候,子组件不会做渲染,而是直接复用 if (oldVnode === vnode) { return } if (isDef(vnode.elm) && isDef(ownerArray)) { // clone reused vnode vnode = ownerArray[index] = cloneVNode(vnode) } const elm = vnode.elm = oldVnode.elm // 当 当前节点 是 注释节点(被 v-if )了,或者是一个 异步函数节点,那不执行 if (isTrue(oldVnode.isAsyncPlaceholder)) { if (isDef(vnode.asyncFactory.resolved)) { hydrate(oldVnode.elm, vnode, insertedVnodeQueue) } else { vnode.isAsyncPlaceholder = true } return } // 当前节点 是一个静态节点的时候,或者 标记了 once 的时候,那不执行 if (isTrue(vnode.isStatic) && isTrue(oldVnode.isStatic) && vnode.key === oldVnode.key && (isTrue(vnode.isCloned) || isTrue(vnode.isOnce)) ) { vnode.componentInstance = oldVnode.componentInstance return } let i const data = vnode.data // 调用 prepatch 的钩子函数 if (isDef(data) && isDef(i = data.hook) && isDef(i = i.prepatch)) { i(oldVnode, vnode) } const oldCh = oldVnode.children const ch = vnode.children // 调用 update 钩子函数 if (isDef(data) && isPatchable(vnode)) { // 这里 的 update 钩子函数式 vnode 本身的钩子函数 for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode) // 这里的 update 钩子函数 是 用户传过来的 钩子函数 if (isDef(i = data.hook) && isDef(i = i.update)) i(oldVnode, vnode) } // 新节点 没有 text 属性 if (isUndef(vnode.text)) { // 如果都有子节点,对比更新子节点 if (isDef(oldCh) && isDef(ch)) { if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly) } else if (isDef(ch)) { // 新节点存在,但是老节点不存在 // 如果老节点是 text, 清空 if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '') // 增加子节点 addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue) } else if (isDef(oldCh)) { // 老节点存在,但是新节点不存在,执行删除 removeVnodes(oldCh, 0, oldCh.length - 1) } else if (isDef(oldVnode.text)) { // 如果老节点是 text, 清空 nodeOps.setTextContent(elm, '') } // 新旧节点 text 属性不一样 } else if (oldVnode.text !== vnode.text) { // 将 text 设置为 新节点的 text nodeOps.setTextContent(elm, vnode.text) } if (isDef(data)) { // 执行 postpatch 钩子函数 if (isDef(i = data.hook) && isDef(i = i.postpatch)) i(oldVnode, vnode) } } -
-
第三步:updateChildren函数子节点进行比较diff算法
-
第一步 头头比较。若相似,旧头新头指针后移(即
oldStartIdx++&&newStartIdx++),真实dom不变,进入下一次循环;不相似,进入第二步。 -
第二步 尾尾比较。若相似,旧尾新尾指针前移(即
oldEndIdx--&&newEndIdx--),真实dom不变,进入下一次循环;不相似,进入第三步。 -
第三步 头尾比较。若相似,旧头指针后移,新尾指针前移(即
oldStartIdx++&&newEndIdx--),未确认dom序列中的头移到尾,进入下一次循环;不相似,进入第四步。 -
第四步 尾头比较。若相似,旧尾指针前移,新头指针后移(即
oldEndIdx--&&newStartIdx++),未确认dom序列中的尾移到头,进入下一次循环;不相似,进入第五步。 -
第五步 若节点有key且在旧子节点数组中找到sameVnode(tag和key都一致),则将其dom移动到当前真实dom序列的头部,新头指针后移(即
newStartIdx++);否则,vnode对应的dom(vnode[newStartIdx].elm)插入当前真实dom序列的头部,新头指针后移(即newStartIdx++)。
-
-
但结束循环后,有两种情况需要考虑:
-
新的字节点数组(newCh)被遍历完(
newStartIdx > newEndIdx)。那就需要把多余的旧dom(oldStartIdx -> oldEndIdx)都删除,上述例子中就是c,d; -
新的字节点数组(oldCh)被遍历完(
oldStartIdx > oldEndIdx)。那就需要把多余的新dom(newStartIdx -> newEndIdx)都添加。
function updateChildren (parentElm, oldCh, newCh) { let oldStartIdx = 0 let newStartIdx = 0 let oldEndIdx = oldCh.length - 1 let oldStartVnode = oldCh[0] let oldEndVnode = oldCh[oldEndIdx] let newEndIdx = newCh.length - 1 let newStartVnode = newCh[0] let newEndVnode = newCh[newEndIdx] let oldKeyToIdx, idxInOld, elmToMove, before while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) { if (isUndef(oldStartVnode)) { oldStartVnode = oldCh[++oldStartIdx] // 未定义表示被移动过 } else if (isUndef(oldEndVnode)) { oldEndVnode = oldCh[--oldEndIdx] } else if (sameVnode(oldStartVnode, newStartVnode)) { // 头头相似 patchVnode(oldStartVnode, newStartVnode) oldStartVnode = oldCh[++oldStartIdx] newStartVnode = newCh[++newStartIdx] } else if (sameVnode(oldEndVnode, newEndVnode)) { // 尾尾相似 patchVnode(oldEndVnode, newEndVnode) oldEndVnode = oldCh[--oldEndIdx] newEndVnode = newCh[--newEndIdx] } else if (sameVnode(oldStartVnode, newEndVnode)) { // 头尾相似 patchVnode(oldStartVnode, newEndVnode) api.insertBefore(parentElm, oldStartVnode.elm, api.nextSibling(oldEndVnode.elm)) oldStartVnode = oldCh[++oldStartIdx] newEndVnode = newCh[--newEndIdx] } else if (sameVnode(oldEndVnode, newStartVnode)) { // 尾头相似 patchVnode(oldEndVnode, newStartVnode) api.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm) oldEndVnode = oldCh[--oldEndIdx] newStartVnode = newCh[++newStartIdx] } else { // 根据旧子节点的key,生成map映射 if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) // 在旧子节点数组中,找到和newStartVnode相似节点的下标 idxInOld = oldKeyToIdx[newStartVnode.key] if (isUndef(idxInOld)) { // 没有key,创建并插入dom api.insertBefore(parentElm, createElm(newStartVnode), oldStartVnode.elm) newStartVnode = newCh[++newStartIdx] } else { // 有key,找到对应dom ,移动该dom并在oldCh中置为undefined elmToMove = oldCh[idxInOld] patchVnode(elmToMove, newStartVnode) oldCh[idxInOld] = undefined api.insertBefore(parentElm, elmToMove.elm, oldStartVnode.elm) newStartVnode = newCh[++newStartIdx] } } } // 循环结束时,删除/添加多余dom if (oldStartIdx > oldEndIdx) { before = isUndef(newCh[newEndIdx+1]) ? null : newCh[newEndIdx + 1].elm addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx, insertedVnodeQueue) } else if (newStartIdx > newEndIdx) { removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx) } } -
2 树diff算法的时间复杂度是O(n^3)
-
第一,遍历原来的树
-
第二,遍历新生成的树
-
第三,排序
所以时间复杂度就是O(n^3),复杂度太高,算法不推荐使用
3 vue优化时间复杂度为O(n)
-
只比较同一层级

-
tag不同,直接删掉,不再继续深度比较

-
tag和key都相同不再深度比较,认为是相同节点
4 key可以优化v-for的性能,到底是怎么回事呢?
因为v-for大部分情况下生成的都是相同tag的标签,如果没有key标识,那么相当于每次头头比较都能成功。你想想如果你往v-for绑定的数组头部push数据,那么整个dom将全部刷新一遍(如果数组每项内容都不一样)

6.16 v-model实现原理
6.16.1 v-model作用
<body>
<div id="app">
<input type="text" v-model="inputValue">
<p>{{inputValue}}</p>
</div>
<script>
var app = new Vue({
el: '#app',
data: {
inputValue : ''
}
})
</script>
</body>
6.16.2 原理
-
在input中输入完内容的时候,调用了change事件,改变了inputValue的值:
v-model 会忽略所有表单元素的 value、checked、selected 特性的初始值而总是将 Vue 实例的数据作为数据来源。你应该通过 JavaScript 在组件的 data 选项中声明初始值。
v-model 在不同的 HTML 标签上使用会监控不同的属性和抛出不同的事件:
-
text 和 textarea 元素使用
value属性和input事件; -
checkbox 和 radio 使用
checked属性和change事件; -
select 字段将
value作为 prop 并将change作为事件。
-
-
在通过响应式原理,通过监听inputValue的改变出发视图的变化
<input v-model="val"> <!-- 基本等价于,因为内部还有一些其他的处理 --> <input :value="val" @input="val = $event.target.value">
6.17 vue渲染过程
6.17.1 模板编译
-
编译成render函数,render函数返回虚拟dom
-
基于Vnode再执行patch和diff
-
使用webpack vue-loader 会在开发环境下编译模板(生产环境中代码直接就是render函数),自己写的demo,通过script引入的vue.js会在浏览器执行的时候进行编译
6.17.2 一个组件渲染到页面,修改data触发视图更新(数据驱动视图)
-
响应式:通过Object.defineProperty方法的setter和getter方法实现响应监听
-
模板编译: 将模板编译成render函数,执行render函数生成虚拟dom
-
patch(diff算法在其中):通过patch方法比较虚拟dom,更新视图
1 初次渲染
-
解析模板为render函数
-
触发响应式,监听data的getter和setter,初次渲染并不会触发setter,但是如果模板中使用data中的数据
就会触发getter
<div id="app"> <p>{{Value1}}</p> </div> <script> var app = new Vue({ el: '#app', data: { Value1 : '你好' ,// 触发getter value2 : '哈哈哈' // 不触发getter } }) </script> -
执行render函数,生成虚拟dom,patch(elem,vnode)
2 修改data,触发setter
-
修改data,触发setter
-
执行render函数,生成newVnode
-
patch(vnode,newVnode)

3 异步渲染
-
汇总dom修改,一次性更新视图
-
减少dom操作次数,提高性能
-
所以想要获取dom元素,需要在$nextTick中完成
6.18 路由原理
6.18.1 hash路由
hash 路由的特点
-
hash变化触发网页的跳转,即浏览器的前进和后退
-
hash变化不会刷新页面,spa必须的特点
-
hash永远不会提交到server端
6.18.2 history路由
-
用url规范的路由,但跳转时不刷新页面
-
history.pushState 使用它做页面跳转不会触发页面刷新
-
window.onpopstate 监听浏览器的前进和后退
8 操作系统
8.1 进程和线程
进程是程序在某个数据集合上的一次运行活动,也是操作系统进行资源分配和保护的基本单位
一个进程中可以有多个线程,它们共享这个进程的资源。
9 数据库
9.1 数据库三大范式🌟
第一范式:每个列都不可以再拆分。
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
在设计数据库结构的时候,要尽量遵守三范式。如果不遵守,必须有足够的理由,比如性能。
9.2 MySQL数据类型
整数类型:
tinyint:很小的整数,8位二进制
smallint:小的整数,16位二进制
mediumint:中等大小的整数,24位二进制
int(integer):普通大小的整数,32位二进制
小数类型:
float:单精度浮点数
double:双精度浮点数
decimal(m,d):压缩严格的定点数
日期类型:year、time、date、datetime、timestamp
文本、二进制类型:
char:0~255之间的整数
varchar:0~65535之间的整数
tinybolb:0~255字节
blob:长度为0~65535字节
mediumblob:0~167772150字节
longblob:0~4294967295字节
tinytext:长度为0~255字节
text:长度为0~65535字节
mediumtext:0~167772150字节
longtext:0~4294967295字节
字符串:
varbinary:变长字节字符串
binary:定长字节字符串
9.3 索引🌟
9.3.1 索引的定义
索引是MySQL存储引擎用于快速查找记录的一种数据结构。
可以简单理解为:索引就是排好序的帮助快速查找的数据结构。索引是一种特殊的数据文件。
-
MyISAM存储引擎中,索引文件和数据文件是分离的,索引文件仅仅保存数据记录的地址。
-
InnoDB存储引擎中,表数据文件本身就是按照B+Tree组织的一个结构,这颗树的叶子结点中保存的就是完整的数据记录,非叶子结点保存的就是索引,在InnoDB引擎中索引和数据都在.ibd文件中。
索引是一种数据结构。
-
索引是一个单独的、物理的数据结构,他是表中一个根据一个字段或多个字段创建的一个集合。
-
数据库的索引,是数据库管理系统中一个排好序的数据结构。
9.3.2 索引的实现
MySQL中默认使用B+Tree结构管理索引。
为什么不用二叉查找树
9.3.3 索引的优缺点
优点:
可以大大加快数据的检索速度,创建索引的最主要原因。
通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点:
时间方面:创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,会降低增/改/删的执行效率。
空间方面:索引需要占物理空间
9.3.4 索引的分类
主键索引:数据列不允许重复,不允许为null,一个表只能有一个主键。
唯一索引:数据列不允许重复,允许为null,一个表允许多个列创建唯一索引。
ALTER TABLE table_name ADD UNIQUE(column);创建唯一组合索引 ALTER TABLE table_name ADD UNIQUE(column1,column2);创建唯一组合索引
普通索引:普通的索引类型,没有唯一性的限制,允许为null值。
ALTER TABLE table_name ADD INDEX index_name(column);创建普通索引 ALTER TABLE table_name ADD INDEX index_name(column1,column2,column3);创建组合索引
全文索引:是目前搜索引擎使用的一种关键技术。
ALTER TABLE table_name ADD FULLTEXT(column);创建全文索引
9.4 事务🌟
9.4.1 事务的定义
事务是一个不可分割的数据库操作序列,也是数据库并发控制的基本单位,其执行的结果必须使数据库从一种一致性状态变到另一种一致性状态。事务是逻辑上的一组操作,要么都执行,要么都不执行。
9.4.2事务的四大特性
原子性:事务的原子性确保事务中的全部操作要么全部完成,要么完全不起作用。
一致性:多个并行执行的事务,其执行结果必须按某一顺序串行执行的结果相一致。
隔离性:事务的执行不受其他事务的干扰。
持久性:对于已经提交的事务,它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
9.4.3 事务隔离级别
READ-UNCOMMITTED(读未提交):最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读;
READ-COMMITTED(读已提交):允许读取并发事务已经提交的数据,可以阻止脏读,但幻读或不可重复读仍有可能发生;
REPRATABLE_READ(可重复读):对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生;
SERIALIZABLE(可串行化):最高的隔离级别,所有的事务依次逐个只熊,这样事物之间就完全不可能产生干扰,也就是说该级别可以防止脏读、不可重复读和幻读。
9.4.4.脏读、幻读、不可重复读
脏读:某个事务已经更新了一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就是不正确的。
不可重复读:在一个事务的两次查询之间数据不一致,这可能是两次查询过程中见插入了一个事务更新的原有的数据。
幻读:在一个事务的两次查询中,数据笔数不一致。
9.5 视图🌟
9.5.1 视图的定义
为了提高复杂SQL语句的复用性和表操作的安全性,MySQL数据库管理系统提供了视图特性。所谓视图,本质上是一种虚拟表,在物理上是不存在的,其内容与真实的表相似,包含一系列带有名称的行和列数据。
9.5.2 视图的特点
-
视图的列可以来自不同的表,是表的抽象和在逻辑意义上建立的新关系;
-
视图是由基本表(实表)产生的表(虚表);
-
视图的建立和删除不影响基本表;
-
对视图的更新(添加、删除和修改)直接影响基本表;
-
当视图来自多个基本表时,不允许添加和删除数据;
-
视图的操作包括创建视图、查看视图、删除视图和修改视图。
9.5.3 视图的使用场景
视图的根本用途:简化sql查询,提高开发效率。如果还有另外一个用途就是兼容老的表结构。常见场景有:
-
重用SQL语句;
-
简化复杂的SQL操作。在编写查询后,可以方便的重用而不必知道它的基本查询细节;
-
使用表的组成部分而不是整个表;
-
保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限;
-
更改数据格式和表示。视图可返回与底层表的表示与格式不同的数据。
5.4 视图的优缺点
优点:
查询简单化;数据安全性;逻辑数据独立性。
缺点:
性能:数据库必须把视图的查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所定义,那么,即使是视图的一个简单查询,数据库也把它变成一个复杂的结合体,需要花费一定的时间。
修改限制:当用户试图修改视图的某些行时,数据库必须把它转换为对基本表的某些行的修改。事实上,当从视图中插入或者删除时,情况也是这样。对于简单视图来说,这是很方便的,但是对比较复杂的视图,可能是不可修改的。
9.6 表的连接查询方式
左连接:以左边的表为主,显示左边表列的全部数据,如果右边表没有对应的数据,则为NULL
右连接:以右边的表为主,显示右边表列的全部数据,如果左边表没有对应的数据,则为NULL
交叉连接
内连接
外连接
联合查询
全连接
9.7 锁
60
9.7.1 死锁
59
9.7.2 乐观锁和悲观锁
9.8 having作用及其与where区别
是一个条件查询,一般是跟着分组以后的,如
select title,count(title) as t from titles group by title having t>=2;
having是在分组后对数据进行过滤;where是在分组前对数据进行过滤;
having后面可以使用聚合函数;where后面不可以使用聚合。
9.9 查询前100行
select * from user limit 0,100
9.10 MySQL中in和exists区别
58
9.11 SQL语句分类
55
9.12 SQL约束分类
NOT NULL:用于控制字段的内容一定不能为空;
UNIQUE:空间字段内容不能重复,一个表允许有多个unique约束;
PRIMERY KEY:用于控件字段内容不能重复,但它在表中只允许出现一个
FOREIGN KEY:用于预防破坏表之间的连接的动作,也能防止非法数据插入外键列,因为他必须是指向的那个表中的值之一。
CHECK:用于控制字段的值范围。
9.13 常见的关系型数据库
MySQL、SQL Server、Oracle、Sybase、DB2等
-
MySQL是开源免费的;
-
SQL Server是由微软公司开发的关系型数据库管理系统,一般用于Web上存储数据;
-
Oracle数据的大量性数据的保存的持久性。
9.14 游标
游标是系统为用户开设的一个数据缓冲区,存放SQL语句的执行结果,每个游标区都有一个名字。用户可以通过游标逐一获取记录并赋给主变量,交由主语言进一步处理。
9.15 触发器以及使用场景
54
9.16 数据库优化查询效率
40、61
-
存储引擎选择:如果数据表需要事务处理,则应考虑使用InnoDB,因为它完全符合ACID特性。如果不需要事务处理,使用默认存储引擎MyISAM是比较明智的。
-
分表分库,主从。
-
对查询进行优化,要尽量避免全表扫描,首先应考虑在where及order by涉及的列上建立索引。
-
应尽量避免where子句中对字段进行null值判断,否则导致引擎放弃使用索引而进行全表扫描
-
应尽量避免where子句中使用!=或<>或or操作
-
update语句,如果只更改1、2个字段,不要update全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志。
-
对于多张大数据量的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差。
9.17 MySQL各引擎之间的区别
39
9.18 数据库的优化
41
9.19 存储过程和函数的区别
62
9.20 SQL注入如何产生和防止
42
9.21 MySQL和MongoDB的差别
44
9.22 MySQL锁的分类
46
9.23 SELECT语句执行顺序
-
from子句组装来自不同数据源的数据;
-
where子句基于指定的条件对记录进行筛选;
-
group by子句将数据划分为多个分组;
-
使用聚集函数进行计算;
-
使用having子句筛选分组;
-
计算所有的表达式;
-
select的字段;
-
使用order by对结果集进行排序。
9.24 百万级别或以上的数据删除
1.先删除索引;2.再删除其中无用数据;3.删除完成后重新创建索引。
与之前的直接删除相比,绝对是要快速很多,更别说万一删除中断,一切删除会回滚。
10 测试
10.1 软件生命周期、开发模型🌟
软件生命周期指一个计算机软件从功能确定、设计,到开发成功投入使用,并在使用中不断地修改、增补和完善,直到停止该软件的使用的全过程。
软件生命周期包括问题定义、需求分析、概念设计、详细设计、系统实现和系统测试等。
常见的生命周期模型:瀑布模型、快速原型模型、迭代式模型、螺旋模型.
10.1.1 瀑布模型
瀑布模型将软件开发过程分为6个阶段: 计划——>需求分析——>软件设计——>编码——>测试——>运行维护,其开发过程如图
在瀑布模型中,软件开发的各项活动严格按照这条线进行,只有当一个阶段任务完成之后才能开始下一个阶段。软件开发的每一个阶段都要有结果产出,结果经过审核验证之后作为下一个阶段的输入,下一个阶段才可以顺利进行。如果结果审核验证不通过,则需要返回修改。
优点:有利于大型软件开发人员的组织管理及工具的使用与研究,可以提高开发的效率。
缺点:无法适应用户需求变更,用户只能等到最后才能看到开发成果,增加了开发风险。
10.1.2 快速原型模型
快速原型模型与瀑布模型正好相反,在最初确定用户需求时快速构造出一个可以运行的软件原型,这个软件原型向用户展示待开发软件的全部或部分功能和性能,客户对该原型进行审核评价,然后给出更佳具体的需求意见,这样逐步丰富细化需求,最后开发人员与客户达成最终共识,确定客户的真正需求。
优点:克服了需求不明确带来的风险,适用于不能预先确定需求的软件项目。
缺点:关键在于快速构建软件模型,准确地设计出软件原型存在一定的难度。此外,这种开发模型也不利于开发人员对产品进行扩展。
10.1.3 迭代式模型
迭代模型又称为增量模型或演化模型。它将一个完整的软件拆分成不同的组件,然后逐个组件地开发测试,每完成一个组件就展现给客户,让客户确认这一部件功能和性能是否达到客户需求,最终确定无误,将组件集成到软件体系结构中。
优点:可以很好地适应客户需求变更,它逐个组件地交付产品,客户可以经常看到产品,如果某个组件没有满足客户需求,则只需要更改这一个组件,降低了软件开发的成本和风险。
缺点:迭代模型需要将开发完成的组件集成到软件体系结构中,这样会有集成失败的风险,因此要求软件必须有开放式的体系结构。此外,迭代模型逐个组件地开发修改,很容易退化为“边做边改”的开放形式,从而失去对软件开发过程的整体控制。
10.1.4 螺旋模型
螺旋模型将整个项目开发过程划分为几个不同的阶段,每个阶段按部就班执行,这种划分方式采用了瀑布模型。每个阶段在开始之前都要进行风险评估,如果能消除重大风险则可以开始该阶段任务。
优点:强调了风险分析,意味着对可选方案和限制条件都进行了评估,更有助于将软件质量作为特殊目标融入产品开发之中。以小分段构建大型软件,使成本计算变的简单容易,而且客户始终参与每个阶段的开发,保证了项目不偏离正确方向,也保证了项目的可控制性。
10.1.5 敏捷模型
无法在软件开发之前收集到完整而详尽的软件需求。
在敏捷模型中,软件项目在构建初期被拆分为多个相互联系又独立运行的子项目,然后迭代完成各个子项目,开发过程中,各个子项目都要经过开发测试。当客户需求变更时,敏捷模型能够迅速地对某个子项目作出修改以满足客户的需求。
除了响应需求,敏捷模型还有一个重要的概念——迭代,就是不断对产品进行细微、渐进式的改进,每次改进一小部分,如果可行再逐步扩大改进范围。在敏捷模型中,软件开发不再是线性的,开发的同时也会进行测试工作,甚至可以提前写好测试代码,因此在敏捷模型中,有“开发未动,测试先行”的说法。
10.2 版本控制、版本控制系统
版本控制是一种软件工程技巧,在开发的过程中,确保由不同人所编辑的同一文件都得到更新及历史记录的保存。
版本控制系统:Git、SVN
10.3 常见的测试模型有哪些?🌟
在实际测试工作中,测试人员更多的是结合W模型和H模型进行工作。软件各个方面的测试内容是以W模型为主,而测试周期、测试计划和进度是以H模型为指导。X模型更多是作为最终测试、熟练性测试的模版。例如,对一个业务测试已经有2年时间,则可以使用X模型进行模块化的、探索性的方向测试。
10.3.1 V模型
V模型的左边是自上而下、逐步细化的开发过程,右边是自下而上、逐步集成的过程,这也符合软件开发和软件测试的关系。
优点:将复杂的测试工作分成了目标明确的小阶段来完成,具有阶段性、顺序性和依赖性。
缺点:只有在编码之后才能进行测试,早起的需求分析等前期工作没有涵盖其中,因此它不能发现需求分析等早起的错误,为后期的系统测试、验收测试埋下了隐患。
10.3.2 W模型
W模型是由V模型演变而来的,它强调测试应伴随整个软件生命周期。其实W模型是一个双V模型,软件开发是一个V模型,而软件测试是与开发同步进行的另一个V模型。
优点:测试范围不仅包括程序,还包括需求分析、软件设计等前期工作,有利于尽早发现问题
缺点:将软件发开过程分成需求、设计、编码、集成等一系列的串行活动,无法支持迭代、自发性等需要变更调整的项目。
10.3.3 H模型
测试流程和其他工作流程是并发执行的,只要某一个工作流程的条件成熟就可以开始进行测试。
在H模型中,测试级别不存在严格的次序关系,软件生命周期的各阶段的测试工作可以反复触发、迭代,即不同的测试可以反复迭代地进行。
10.3.4 X模型
X模型的设计原理是将程序分成多个片段反复迭代测试,然后将多个片段集成在进行迭代测试。
10.4 测试的主要方面🌟
-
功能测试:
-
性能测试:
-
接口测试:
-
可用性测试:
-
兼容性测试:
-
安全测试:
-
代码合法性测试:
-
文档测试:
10.5 软件测试的方法🌟
黑盒测试和白盒测试
10.5.1 黑盒测试
黑盒测试:这种方法是将测试对象看作一个黑盒子,测试人员完全不考虑程序内部的逻辑结构和内部特性,只依据程序的需求规格说明书,检查程序的功能是否符合她的功能说明。黑盒测试又叫做功能测试或数据驱动测试。
常见的黑盒测试方法:等价类划分法、边界值分析法、因果图与决策表法、正交试验设计法
10.5.2白盒测试
白盒测试:此方法把测试对象看作一个透明盒子,它允许测试人员利用程序内部的逻辑结构及有关信息,设计或选择测试用例,对程序所有逻辑路径进行测试。通过在不同点检查程序的状态,确定实际的状态是否与预期的状态一致。因此白盒测试又称结构测试或逻辑驱动测试。
常见的白盒测试方法:逻辑覆盖法(包括语句覆盖、判定覆盖、条件覆盖)、程序插桩法
10.6 软件测试分类🌟
按照软件测试的过程划分,可以分为三个步骤:单元测试、集成测试、系统测试。
单元测试:又称模块测试,是针对软件设计的最小单位——程序模块,进行正确性验证的测试工作。其目的在于发现各模块内部可能存在的各种差错。单元测试需要从程序的内部结构出发设计测试用例。多个模块可以平行地独立进行单元测试。
集成测试:在运行的应用中保证软件单元被结合后能正常操作的测试执行的阶段
系统测试:当应用作为整体运行时的测试执行阶段。
验收测试:第三方进行的确认软件满足需求的测试。
10.7 测试结束的标准
-
测试超过了预定时间,则停止测试
-
执行了所有的测试用例,但并没有发现故障,则停止测试。
-
覆盖率达到标准;
-
缺陷率达到标准;
-
其他指标达到质量标准。
10.8 测试计划
10.8.1测试计划的目的
-
是测试计划顺利进行;
-
使项目参与人员沟通更舒畅;
-
使测试工作更加系统化。
10.8.2测试计划六要素
why——为什么要进行这些测试
what——测试哪些方面,不同阶段的工作内容
when——测试不同阶段的起止时间
where——相应文档,缺陷的存放位置,测试环境等
who——项目有关人员组成,安排哪些测试人员进行测试
how——如何去做,使用哪些测试工具以及测试方法进行测试
10.9 软件缺陷的生命周期🌟
测试人员提交新的bug后,错误状态为New。高级测试人员验证错误,如果确定是错误,分配给相应的开发人员,设置状态为Open;如果不是错误,则拒绝,设置为Declined。开发人员查询状态为Open的bug,如果不是错误,则设置为Declined;如果是bug,则修复并设置状态为Fixed。不能解决的bug,要留下文字说明及保持bug为Open状态。对于不能解决和延期解决的bug,不能由开发人员自己决定,一般要通过某种会议通过才能认可。测试人员查询状态为Fixed的bug,然后验证bug是否已解决,如解决置bug的状态为Closed,如没有解决设置状态为Closed,没有解决设置状态为Reopen。
10.10 bug级别🌟
致命:对业务由至关重要的影响,业务系统完全丧失业务功能,无法再继续进行;
严重:对业务有严重的影响,业务系统已经丧失一部分的业务功能;
一般:对业务有较小的影响,业务系统丧失较少的业务功能;
提示:对业务没有影响,不影响业务过程正常进行。
10.11 前后端bug区分🌟
通常可以利用抓包工具来进行分析。可以从三个方面进行分析:请求借口、传参数、响应。
-
请求接口是否正确。如果请求的接口url错误,则为前端的bug。
-
传参是否正确。如果传参不正确,则为前端的bug。
-
请求接口和传参都正确,检查响应是否正确,如果相应内容不正确,则为后端bug。
-
也可以在浏览器控制台输入js代码调试进行分析。
10.12 冒烟测试🌟
冒烟测试一般是我们在系统测试之前,对所有主体的业务功能,测试看是否存在严重bug。
如果存在严重bug,表示冒烟测试不通过。
10.13 回归测试🌟
功能的回归:优先测试用例级别比较高的功能,可以进行自动化测试;如果时间够,进行全量测试。
bug回归:复测这个bug,并且相关联的模块与功能也会测试一遍,以免由于修改bug导致其他问题产生。
10.14 产品上线评判的标准🌟
-
测试用例执行率100%,通过率95%
-
1~2级bug修复率达到100%,3~4级bug修复率达到95%
10.15 安全测试🌟
-
sql注入
-
xss脚本攻击
-
数据加密
-
权限控制
10.16 网站如何开展测试🌟
-
分析测试需求。查找需求说明、网站设计等相关文档,分析测试需求;
-
制定测试计划。确定测试范围和测试策略,一般包括以下几个部分:功能性能、界面测试、性能测试、数据库测试、安全性测试、兼容性测试。
-
设计测试用例。
-
开展测试。
-
定期评审,对测试进行评估和总结,调整测试的内容。
11 安全
11.1 CSRF攻击
11.1.1 什么是CSRF攻击?
CSRF全称为跨站请求伪造(Cross-site request forgery)
攻击者盗用了你的身份信息,以你的名义发送恶意请求,
对服务器来说这个请求是你发起的,却完成了攻击者所期望的一个操作

11.1.2 危害
修改用户信息,修改密码,以你的名义发送邮件、发消息、盗取你的账号等
11.1.3 攻击条件
用户已登录存在CSRF漏洞的网站
用户需要被诱导打开攻击者构造的恶意网站
11.1.4 防范
1.4.1 验证HTTP Referer字段
referer字段表明了请求来源,通过在服务器端添加对请求头字段的验证拒绝一切跨站请求,
但是请求头可以绕过,XHR对象通过setRequestHeader方法可以伪造请求头
1.4.2 添加token验证
客户端令牌token通常作为一种身份标识,由服务器端生成的一串字符串,当第一次登录后,
服务器生成一个token返回给客户端,以后客户端只需带上token来请求数据即可,无需再次带上用户名和密码。
如果来自浏览器请求中的token值与服务器发送给用户的token不匹配,或者请求中token不存在,
则拒绝该请求,使用token验证可以有效防止CSRF攻击,但增加了后端数据处理的工作量
1.4.3 验证码
发送请求前需要输入基于服务端判断的验证码,机制与token类似,
验证码强制用户与web完成交互后才能实现正常请求,最简洁而有效的方法,但影响用户体验
11.2 XSS攻击
11.2.1 什么是xss攻击
XSS又叫CSS(Cross Site Script),跨站脚本攻击:攻击者在目标网站植入恶意脚本(js / html),用户在浏览器上运行时可以获取用户敏感信息(cookie / session)、修改web页面以欺骗用户、与其他漏洞相结合形成蠕虫等。

对特殊字符进行转译就好了(vue/react等主流框架已经避免类似问题,vue举例:不能在template中写script标签,无法在js中通过ref或append等方式动态改变或添加script标签)
11.2.2 危害
-
使网页无法正常运行
-
获取cookie信息
-
劫持流量恶意跳转
11.2.3 攻击条件
-
网页内部有输入框,内容可存储在服务器上
11.2.4 防御措施
对用户输入内容和服务端返回内容进行过滤和转译
-
现代大部分浏览器都自带 XSS 筛选器,vue / react 等成熟框架也对 XSS 进行一些防护
-
过滤,对诸如<script>、<img>、<a>等标签进行过滤。
-
编码。像一些常见的符号,如<>在输入的时候要对其进行转换编码,这样做浏览器是不会对该标签进行解释执行的,同时也不影响显示效果。
11.3 iframe
11.3.1 如何让自己的网站不被其他网站的 iframe 引用?
// 检测当前网站是否被第三方iframe引用
// 若相等证明没有被第三方引用,若不等证明被第三方引用。当发现被引用时强制跳转百度。
if(top.location != self.location){
top.location.href = 'http://www.baidu.com'
}
11.3.2 如何禁用,被使用的 iframe 对当前网站某些操作?
sandbox是html5的新属性,主要是提高iframe安全系数。iframe因安全问题而臭名昭著,这主要是因为iframe常被用于嵌入到第三方中,然后执行某些恶意操作。 现在有一场景:我的网站需要 iframe 引用某网站,但是不想被该网站操作DOM、不想加载某些js(广告、弹框等)、当前窗口被强行跳转链接等,我们可以设置 sandbox 属性。如使用多项用空格分隔。
-
allow-same-origin:允许被视为同源,即可操作父级DOM或cookie等
-
allow-top-navigation:允许当前iframe的引用网页通过url跳转链接或加载
-
allow-forms:允许表单提交
-
allow-scripts:允许执行脚本文件
-
allow-popups:允许浏览器打开新窗口进行跳转
-
“”:设置为空时上面所有允许全部禁止
11.4 opener
11.4.1 原理
在项目中需要 打开新标签 进行跳转一般会有两种方式,通过这两种方式打开的页面可以使用 window.opener 来访问源页面的 window 对象
HTML -> <a target='_blank' href='http://www.baidu.com'>
JS -> window.open('百度一下,你就知道')
场景:A 页面通过 <a> 或 window.open 方式,打开 B 页面。但是 B 页面存在恶意代码如下:
-
window.opener.location.replace('百度一下,你就知道') 【此代码仅针对打开新标签有效】,此时,用户正在浏览新标签页,但是原来网站的标签页已经被导航到了百度页面。
11.4.2 风险
-
新打开的地址无限模仿用户要打开的网站,用户输入用户名密码或者交易等都在恶意网站上进行,风险极高,即使在跨域状态下 opener 仍可以调用 location.replace 方法。
11.4.3 避免方案
<a target="_blank" href="" rel="noopener noreferrer nofollow">a标签跳转url</a>
通过 rel 属性进行控制: noopener:会将 window.opener 置空,从而源标签页不会进行跳转(存在浏览器兼容问题) noreferrer:兼容老浏览器/火狐。禁用HTTP头部Referer属性(后端方式)。 nofollow:指示搜索引擎不要追踪(即抓取)网页上的任何出站链接
<button οnclick='openurl("http://www.baidu.com")'>click跳转</button>
function openurl(url) {
var newTab = window.open();
newTab.opener = null;
newTab.location = url;
}
11.5 ClickJacking(点击劫持)
11.5.1 原理
-
访问者被恶意页面吸引。怎样吸引的不重要。
-
页面上有一个看起来无害的链接(例如:“变得富有”或者“点我,超好玩!”)。
-
恶意页面在该链接上方放置了一个透明的
<iframe>,其src来自于 facebook.com,这使得“点赞”按钮恰好位于该链接上面。这通常是通过z-index实现的。 -
用户尝试点击该链接时,实际上点击的是“点赞”按钮。
11.5.2 风险
-
在用户不知情的情况下就对某个网站进行了操作
11.5.3 避免方案
X-Frame-Options:X-Frame-Options可以说是为了解决ClickJacking而生的,它有三个可选的值:
DENY 拒绝当前页面加载任何frame页面 SAMEORIGIN frame页面的地址只能为同源域名下的页面 ALLOW-FROM origin 定义允许frame加载的页面地址
11.6 本地存储数据问题
很多开发者为了方便,把一些个人信息不经加密直接存到本地或者cookie,这样是非常不安全的,黑客们可以很容易就拿到用户的信息,所有在放到cookie中的信息或者localStorage里的信息要进行加密,加密可以自己定义一些加密方法或者网上寻找一些加密的插件,或者用base64进行多次加密然后再多次解码,这样就比较安全了。
11.7 第三方依赖安全隐患
项目开发,很多都喜欢用别人写好的包,为了方便快捷,很快的就搭建起项目,自己写的代码不到20%,过多的用第三方依赖或者插件,一方面会影响性能问题,另一方面第三方的依赖或者插件存在很多安全性问题,也会存在这样那样的漏洞,所以使用起来得谨慎。
解决办法:手动去检查那些依赖的安全性问题基本是不可能的,最好是利用一些自动化的工具进行扫描过后再用,比如NSP(Node Security Platform),Snyk等等。
11.8 HTTPS加密传输数据
在浏览器对服务器访问或者请求的过程中,会经过很多的协议或者步骤,当其中的某一步被黑客拦截的时候,如果信息没有加密,就会很容易被盗取。所以接口请求以及网站部署等最好进行HTTPS加密,这样防止被人盗取数据。
12 前端优化
12.1 性能优化
12.1.1 加载更快
-
让传输的数据包更小(压缩文件/图片)
-
减少网络请求的次数
-
减少渲染的次数
-
提前渲染
1 图片压缩和文件压缩
-
减小文件的大小
2 雪碧图/精灵图
-
雪碧图/精灵图:多张图标合并在一张大图中
-
使用方法
1. 引入图片
2. 通过背景定位具体图标
-
优化的方式
-
减少加载网页图片时服务器的请求次数
可以合并多数背景图片和小图标,方便在任何位置使用,这样不同位置的请求只需要调用一个图片,从而减少对服务器的请求次数, 降低服务器压力,同时提高了页面的加载速度,节约服务器的流量。
-
3 ssr服务器端渲染
-
CSR是Client Side Render简称;页面上的内容是我们加载的js文件渲染出来的,
js文件运行在浏览器上面,服务端只返回一个html模板。
2. SSR是Server Side Render简称;页面上的内容是通过服务端渲染生成的,
浏览器直接显示服务端返回的html就可以了。
-
优化方式
减少网络传输:响应快,用户体验好,首屏渲染快
对搜索引擎友好,搜索引擎爬虫可以看到完整的程序源码,有利于SEO.
4 缓存
-
http缓存:不需要通过服务器传输数据,直接从http缓存中获取
-
协商缓存
-
强制缓存
-
-
本地缓存:
-
localstorage:把一般不需要变动的大型数据存储在localstorage中,打开页面判断localstorage中是否有该数据,有就直接从浏览器中获取
-
-
优化方式:
-
减少网络传输的次数
-
12.1.2 渲染更快
1 css和js文件的位置
-
css写head:
css放在body标签尾部时, DOMTree构建完成之后便开始构建RenderTree, 并计算布局渲染网页,
等加载解析完css之后, 开始构建CSSOMTree, 并和DOMTree重新构建RenderTree,
重新计算布局渲染网页
css放在head标签中时, 先加载css, 之后解析css构建CSSOMTree, 于此同时构建DOMTree,
CSSOMTree和DOMTree都构建完毕之后开始构建RenderTree, 计算布局渲染网页

2. js写底部
1. JavaScript时会阻止其他内容的下载,要等到JS文件下载解析完之后才会显示网页内容。若JS文件很大放在前面就会导致加载时间较长,网页会一直白屏
2. 因为JS一般会涉及到一些DOM操作,所以要等全部的dom元素都加载完再加载JS。
js文件放在头部如图:

js文件放在body底部如图:

2 懒加载
-
方法:默认进入页面只展示首屏能够展示的内容,当滚动条拉动到页面底部继续拉动再进行数据加载和渲染
-
优化方法:
-
减少不必要的数据传输和渲染
-
使页面渲染更快
-

3 对dom查询进行缓存
-
每次查询dom元素都需要遍历,将查询结果缓存起来
// 不缓存DOM查询结果 for (let i = 0; i < document.getElementsByTagName('p').length; i++) { // 每次循环,都会计算length,频繁进行DOM查询 }// 缓存DOM查询结果 const pList = document.getElementsByTagName('p') const length = pList.length for (let i = 0; i < length; i++) { // 缓存length,只进行一次DOM查询 } -
优化方式:减少相同运算的运算次数
4 将dom操作合并
-
多次dom操作合并成一次
-
优化方式:减少dom渲染的次数
// 未合并 const listNode = document.getElementById('list') // 执行插入 for (let i = 0; i < 10; i++) { const li = document.createElement('li') li.innerHTML = 'list item ' + i // 创建一个插入一个 listNode.appendChild(frag) }// 合并 const listNode = document.getElementById('list') // 创建一个文档片段,此时还没有插入到DOM树中 const frag = document.createDocumentFragment() // 执行插入 for (let i = 0; i < 10; i++) { const li = document.createElement('li') li.innerHTML = 'list item ' + i frag.appendChild(li) } // 都完成之后,再插入到DOM树中 listNode.appendChild(frag)
5 节流和防抖
-
节流(Throttle)函数: 对于持续的事件触发,每达到固定时间间隔,执行事件处理函数

-
防抖(Debounce)函数: 事件触发停止后开始计时,在固定时间内不再有事件触发,执行事件处理函数

12.2 html语义化
-
HTML 语义化的核心是反对大篇幅的使用无语义化的 div + css + span,而鼓励使用 HTML 定义好的语义化标签。那么我们应该关心的就是标签的语义以及应该是用的场景。
-
使用语义化标签的优势:让页面具有良好的语义和结构,从而方便人类和机器都能快速理解网页内容,在无css样式的情况下也展示出页面良好的结构,有利于seo
header
header 代表网页或 section 的页眉,通常需要包含 h1~h6 或者 hgroup。
(tip:虽然 w3c 规范中认为 header 在一个页面中可以存在一个或者多个,但是通常要头部结构信息较为复杂,包含多个导航和菜单的内容,才适合使用 header 进行包裹。)
footer 代表网页或 section 的页脚。通常包含一些基本信息,如:作者、相关文档链接、版权资料等。
代表页面的导航链接区域。
(tip:规范中认为 nav 只适用于页面主要导航部分。)
article
代表一个在网页中自成一体的内容,其目的是为了方便开发者独立开发或重。通常需要包含一个 header/h1~h6 和一个 footer。
(tip:如果在 article 内部再嵌套 article,那就代表内嵌的 article 是与它外部的内容有关联的,比如文章下面的评论。)
section
代表文档中的“节”或“段”。通常需要包含 h1~h6。
(tip:虽然 html5 中会对 section 的标题自动降级,但建议手动对其进行降级。)
aside
代表一块独立的内容区域。通常使用分为两种情况:
-
在 article 中:作为主要内容的附属内容
-
在 article 外:最典型的应用是侧边栏
到这里,相信已经将 HTML 语义化大致讲清楚了。我们接下来聊聊 CSS 语义化
12.3 seo优化
-
搜索引擎工作原理
在搜索引擎网站的后台会有一个非常庞大的数据库,里面存储了海量的关键词,而每个关键词又对应着很多网址,这些网址是被称之为“搜索引擎蜘蛛”或“网络爬虫”程序从茫茫的互联网上一点一点下载收集而来的。随着各种各样网站的出现,这些勤劳的“蜘蛛”每天在互联网上爬行,从一个链接到另一个链接,下载其中的内容,进行分析提炼,找到其中的关键词,如果“蜘蛛”认为关键词在数据库中没有而对用户是有用的便存入后台的数据库中。反之,如果“蜘蛛”认为是垃圾信息或重复信息,就舍弃不要,继续爬行,寻找最新的、有用的信息保存起来提供用户搜索。当用户搜索时,就能检索出与关键字相关的网址显示给访客。
-
seo搜索引擎优化
SEO(Search Engine Optimization),即搜索引擎优化。SEO是随着搜索引擎的出现而来的,两者是相互促进,互利共生的关系。SEO的存在就是为了提升网页在搜索引擎自然搜索结果中的收录数量以及排序位置而做的优化行为。而优化的目的就是为了提升网站在搜索引擎中的权重,增加对搜索引擎的友好度,使得用户在访问网站时能排在前面。
-
seo优化前端的方法:
-
创建唯一且准确的网页标题
<title><title>标记可告诉用户和搜索引擎特定网页的主题是什么。它应放置在 HTML 文档的<head>元素中。我们应该为网站上的每个网页创建一个唯一标题,并且尽量避免与网页内容无关或使用默认或模糊的标题。如:<!-- 正确示范 --> <title>前端搜索引擎优化的技巧</title> <!-- 错误示范 --> <title>我的文档</title>
-
使用
<meta>元标签我们可以使用
<meta>的keywords元数据来提炼网页重要关键字,以及description元数据准确总结网页内容,而避免在description元数据的内容中出现关键词的堆砌,描述过长,或“这是一个网页”这种没有实际性意义的描述等现象。正确示范如下:<meta name='keywords' content='SEO,title,meta,语义化,alt'> <meta name='description' content='介绍搜索引擎优化的技巧,如使用创建title标题、meta关键词和描述、语义化标签、img的alt属性等。'>
-
使用语义化元素
在合适的位置使用合适的元素表达合适的内容,让用户和“蜘蛛”能一目了然文档结构。例如使用
<h1>可以让“蜘蛛”知道这是很重要的内容。然而,值得注意的是,例如在想要表达强调时,我们不应该滥用标题元素或者<b>、<i>这种没有实际意义的标签,换而可以使用<em>或<strong>来表示强调。此外,<h1>的权重比<h2>的大,我们不应该为了增大权重而去滥用<h1>,一般来说<h1>用于正文的标题。 -
利用
<img>中的alt属性alt属性可以在图片未成功显示时候,使用文本来代替图片的呈现,使“蜘蛛”可以抓取到这个信息。此外它还可以解决浏览器禁用图像或屏幕阅读器解析等问题。 -
设置
rel='nofollow'忽略跟踪如果某个
<a>的链接不需要跟踪,那么添加rel='nofollow'即可通知“蜘蛛”忽略跟踪。因为“蜘蛛”分配到每个页面的权重是一定的,为了集中网页权重并将权重分给其他必要的链接,为不必跟踪的链接添加这个属性就显得很必要了。 -
尽量保证 HTML 的纯粹和高质量
应尽量让结构(HTML)、表现(CSS)及行为(JavaScript)三者分离。如果在一个 HTML 页面中,编写大量的 CSS 样式或脚本,会拖慢其加载速度,此外,如果不为
<img>定义宽高,那么会引起页面重新渲染,同样也会影响加载速度。一旦加载超时,“蜘蛛”就会放弃爬取。如果这个 HTML 文档内容比较独特丰富(合理插入图片说明)等,会被认为质量较高符合用户需求,从而提高 SEO 的排名。 -
扁平化网站结构
一般来说,一个网站的结构层次越少,越有利于“蜘蛛”的爬取。所以目录结构一般不多于 3 级,否则“蜘蛛”很容易不愿意继续往下爬。就像用户在操作一个网页一样,层级大于 3 就很影响用户体验了,“蜘蛛”就是模仿用户的心理。
-
合理安排重要内容的位置
应该将重要内容的 HTML 代码放在最前面,最前面的内容被认为是最重要的,优先让“蜘蛛”读取,进行内容关键词抓取。并且,重要内容不应该由 JavaScript 或 iframe 输出,“蜘蛛”没有办法读取 JavaScript ,一般不会去读取 iframe 中的内容。
-
-
为什么要做SEO
提高网站的权重,增强搜索引擎友好度,以达到提高排名,增加流量,改善(潜在)用户体验,促进销售的作用。
13 设计模式
13.1 观察者与发布订阅者模式
1. 观察者模式
官方给出的观察者模式的解释是这样的:
定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
观察者模式实现的,其实就是当目标对象的某个属性发生了改变,所有依赖着目标对象的观察者都将接到通知,做出相应动作。 所以在目标对象的抽象类里,会保存一个观察者序列。当目标对象的属性发生改变生,会从观察者队列里取观察者调用各自的方法。
class Subject {
constructor() {
this.observers = [];
}
add(observer) {
this.observers.push(observer);
}
notify(...args) {
this.observers.forEach(observer => observer.update(...args));
}
}
class Observer {
update(...args) {
console.log(...args);
}
}
// 创建观察者ob1
let ob1 =new Observer();
// 创建观察者ob2
let ob2 =new Observer();
// 创建目标sub
let sub =new Subject();
// 目标sub添加观察者ob1 (目标和观察者建立了依赖关系)
sub.add(ob1);
// 目标sub添加观察者ob2
sub.add(ob2);
// 目标sub触发SMS事件(目标主动通知观察者)
sub.notify('I fired `SMS` event');
2. 发布/订阅模式
在发布订阅模式里,发布者,并不会直接通知订阅者,换句话说,发布者和订阅者,彼此互不相识。
发布/订阅模式相比于观察者模式多了一个中间媒介,因为这个中间媒介,发布者和订阅者的关联更为松耦合
发布-订阅是一种消息范式,消息的发送者(称为发布者)不会将消息直接发送给特定的接收者(称为订阅者)。而是将发布的消息分为不同的类别,无需了解哪些订阅者(如果有的话)可能存在。同样的,订阅者可以表达对一个或多个类别的兴趣,只接收感兴趣的消息,无需了解哪些发布者(如果有的话)存在。
也就是说,发布/订阅模式和观察者最大的差别就在于消息是否通过一个中间类进行转发。
classPubSub {
constructor() {
this.subscribers = [];
}
subscribe(topic, callback) {
letcallbacks =this.subscribers[topic];
if(!callbacks) {
this.subscribers[topic] = [callback];
}else{
callbacks.push(callback);
}
}
publish(topic, ...args) {
letcallbacks =this.subscribers[topic] || [];
callbacks.forEach(callback => callback(...args));
}
}
// 创建事件调度中心,为订阅者和发布者提供调度服务
letpubSub =newPubSub();
// A订阅了SMS事件(A只关注SMS本身,而不关心谁发布这个事件)
pubSub.subscribe('SMS', console.log);
// B订阅了SMS事件
pubSub.subscribe('SMS', console.log);
// C发布了SMS事件(C只关注SMS本身,不关心谁订阅了这个事件)
pubSub.publish('SMS','I published `SMS` event');
3. 两种模式的区别
由上,我们就可以得出这两者的区别了:
-
在观察者模式中,观察者是知道Subject的,Subject一直保持对观察者进行记录。然而,在发布订阅模式中,发布者和订阅者不知道对方的存在。它们只有通过消息代理进行通信。
-
在发布订阅模式中,组件是松散耦合的,正好和观察者模式相反。
-
观察者模式大多数时候是同步的,比如当事件触发,Subject就会去调用观察者的方法。而发布-订阅模式大多数时候是异步的(使用消息队列)。
4. 两种模式举例
观察者:事件处理(一旦触发事件,立即执行)
document.body.addEventListener('click',function(){
alert('我也是一个观察者,你一点击,我就知道了');
});
其中,body是发布者,即目标对象,当被点击的时候,向观察者反馈这一事件;JavaScript中函数也是一个对象,click这个事件的处理函数(alert('...'))就是观察者,当接收到目标对象反馈来的信息时进行一定处理。
发布订阅者:事件循环 (例如 发布者:ajax请求,发出去返回之后存在消息队列中,订阅者主线程并不会立即处理回调,而是等着事件循环机制在中间层将回调函数推送导致主线程中执行)
14 数据结构
14.1 递归
斐波那契数列
阶乘
时间复杂度:O(2的n次方)
14.2 贪心
找钱
时间复杂度:O(nlogn)
14.3 B树和B+树的区别
B树
在B树中,可以将键和值存放在内部节点和叶子节点;
B树可以在内部节点同时存储键和值。因此,把频繁访问的数据放在靠近根节点的地方将会大大提高热点数据的查询效率。这种特性使得B树在特定数据重复多次查询的场景中更加高效。
B+树
在B+树,B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
由于B+树的内部节点只存放键,不存放值。因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围。B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。而B树则需要对树的每一层进行遍历,这会需要更多的内存置换次数,因此也就需要花费更多的时间。
15 项目
15.1 跨域
当一个请求url的协议、域名、端口三者之间任意一个与当前页面url不同即为跨域。
解决方式:
-
Jsonp
-
nginx
-
CORS
CORS是一个W3C标准,全称是"跨域资源共享"(Cross-origin resource sharing)。
它允许浏览器向跨源服务器,发出XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制。
-
GetWay网关中实现跨域步骤
16 其他
16.1 C++和Java语言的区别
Java是纯面向对象的语言,能够直接反应现实生活中的对象,容易解释,编程更容易
-
跨平台。Java是解释性语言,编译器会把java代码变成中间代码,然后在JVM上解释执行,由于中间代码和平台无关。java语言可以跨平台执行,具有很好的移植性。
-
Java提供了很多内置的类库,简化了开发人员的程序设计工作,缩短了项目的开发时间。例如,Java语言提供了对多线程的支持,提供了网络通信的支持,最重要的是提供了垃圾回收器,这使得开发人员从对内存的管理中解脱出来。
-
去除了C++语言中难以理解、容易混淆的特性,例如头文件、指针、结构、单元、运算符重载、虚拟继承类、多重继承类,使得程序更加严谨、简洁。
16.2 Vector
vector是向量类型,它可以容纳许多类型的数据,如若干个整数,所以称其为容器。vector是C++ STL的一个重要成员,使用它时需要包含文件:
#include<vector>
vector的初始化,可以有五种方式:
vector<int> a(10); //定义了10个整型元素的向量(尖括号中为元素类型名,它可以是任何合法的数据类型),但没有给出初值,其值是不确定的。
vector<int> a(10,1); //定义了10个整型元素的向量,且给出每个元素的初值为1
vector<int> a(b); //用b向量来创建a向量,整体复制性赋值
vector<int> a(b.begin(),b.begin+3); //定义了a值为b中第0个到第2个(共3个)元素
int b[7]={1,2,3,4,5,9,8};
vector<int> a(b,b+7); //从数组中获得初值
vector对象的几个重要操作:
a.pop_back(); //删除a向量的最后一个元素 a.push_back(5); //在a的最后一个向量后插入一个元素,其值为5 a.size(); //返回a中元素的个数; a.clear(); //清空a中的元素 a.empty(); //判断a是否为空,空则返回ture,不空则返回false a.assign(b.begin(), b.begin()+3); //b为向量,将b的0~2个元素构成的向量赋给a a.assign(4,2); //是a只含4个元素,且每个元素为2 a.back(); //返回a的最后一个元素 a.front(); //返回a的第一个元素 a[i]; //返回a的第i个元素,当且仅当a[i]存在2013-12-07 a.erase(a.begin()+1,a.begin()+3); //删除a中第1个(从第0个算起)到第2个元素,也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+ 3(不包括它) a.insert(a.begin()+1,5); //在a的第1个元素(从第0个算起)的位置插入数值5,如a为1,2,3,4,插入元素后为1,5,2,3,4 a.insert(a.begin()+1,3,5); //在a的第1个元素(从第0个算起)的位置插入3个数,其值都为5 a.insert(a.begin()+1,b+3,b+6); //b为数组,在a的第1个元素(从第0个算起)的位置插入b的第3个元素到第5个元素(不包括b+6),如b为1,2,3,4,5,9,8 ,插入元素后为1,4,5,9,2,3,4,5,9,8 a.capacity(); //返回a在内存中总共可以容纳的元素个数 a.resize(10); //将a的现有元素个数调至10个,多则删,少则补,其值随机 a.resize(10,2); //将a的现有元素个数调至10个,多则删,少则补,其值为2 a.reserve(100); //将a的容量(capacity)扩充至100,也就是说现在测试a.capacity();的时候返回值是100.这种操作只有在需要给a添加大量数据的时候才 显得有意义,因为这将避免内存多次容量扩充操作(当a的容量不足时电脑会自动扩容,当然这必然降低性能) a.swap(b); //b为向量,将a中的元素和b中的元素进行整体性交换 a==b; //b为向量,向量的比较操作还有!=,>=,<=,>,<
16.3 map
map是STL。
第一个可以称为关键字(key),每个关键字只能在map中出现一次。
第二个可能成为该关键字的值。
// 定义一个map对象
map<int, string> mapStudent;
//insert
// 第一种 用insert函數插入pair
mapStudent.insert(pair<int, string>(000, "student_zero"));
// 第二种 用insert函数插入value_type数据
mapStudent.insert(map<int, string>::value_type(001, "student_one"));
// 第三种 用"array"方式插入
mapStudent[123] = "student_first";
mapStudent[456] = "student_second";
//find
// find 返回迭代器指向当前查找元素的位置否则返回map::end()位置
iter = mapStudent.find("123");
if(iter != mapStudent.end())
cout<<"Find, the value is"<<iter->second<<endl;
else
cout<<"Do not Find"<<endl;
//迭代器刪除
iter = mapStudent.find("123");
mapStudent.erase(iter);
//用关键字刪除
int n = mapStudent.erase("123"); //如果刪除了會返回1,否則返回0
//用迭代器范围刪除 : 把整个map清空
mapStudent.erase(mapStudent.begin(), mapStudent.end());
//等同于mapStudent.clear()
// find 返回迭代器指向当前查找元素的位置否则返回map::end()位置
iter = mapStudent.find("123");
if(iter != mapStudent.end())
cout<<"Find, the value is"<<iter->second<<endl;
else
cout<<"Do not Find"<<endl;
//迭代器刪除
iter = mapStudent.find("123");
mapStudent.erase(iter);
//用关键字刪除
int n = mapStudent.erase("123"); //如果刪除了會返回1,否則返回0
//用迭代器范围刪除 : 把整个map清空
mapStudent.erase(mapStudent.begin(), mapStudent.end());
//等同于mapStudent.clear()
//size函数
int nSize = mapStudent.size();
常见操作:
begin() //返回指向map头部的迭代器 clear() //删除所有元素 count() //返回指定元素出现的次数, (帮助评论区理解: 因为key值不会重复,所以只能是1 or 0) empty() //如果map为空则返回true end() //返回指向map末尾的迭代器 equal_range() //返回特殊条目的迭代器对 erase() //删除一个元素 find() //查找一个元素 get_allocator() //返回map的配置器 insert() //插入元素 key_comp() //返回比较元素key的函数 lower_bound() //返回键值>=给定元素的第一个位置 max_size() //返回可以容纳的最大元素个数 rbegin() //返回一个指向map尾部的逆向迭代器 rend() //返回一个指向map头部的逆向迭代器 size() //返回map中元素的个数 swap() //交换两个map upper_bound() //返回键值>给定元素的第一个位置 value_comp() //返回比较元素value的函数


















 1926
1926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











