






可能会有人说使用整合包就行了,但按照我的经验来说,使用整合包会出现各种各样的小问题,所以我这里推荐想好好用的朋友还是一步步来安装。
概述
Stable Diffusion ComfyUI 是一款基于开源 Stable Diffusion
文本转图像模型的本地图形用户界面
(GUI) 工具,用于生成高分辨率图像。它提供了一个用户友好的界面,可让您轻松自定义和控制生成过程,并探索各种创意可能性。
准备工作
在开始之前,请确保您的电脑满足以下最低系统要求:
-
操作系统:Windows 10 或更高版本,macOS 10.14 或更高版本,或 Linux
-
显卡:NVIDIA Geforce GTX 1060 6GB 或更高版本,或 AMD Radeon RX 5600 XT 6GB 或更高版本
-
内存:16 GB 或更高
-
存储空间:50 GB 或更多
安装步骤
1. **下载安装python**
地址:https://www.python.org/downloads/
这里不推荐下载最新版本,下载自己系统对应的程序即可。

安装时候务必勾选“Add python.exe to PATH”选项。
2. **下载安装git**
地址:https://git-scm.com/
下载后按默认一步步安装完成即可。
3. 下载安装VisualStudio
**地址:https://visualstudio.microsoft.com/zh-hans/**
下载Professional即可。
* 1
* 2
* 3

勾选有关C++的选项和对应你电脑操作系统版本的SDK后安装即可。
* 1

4. 下载安装CUDA
**下载地址:https://developer.nvidia.com/cuda-downloads**
选择自己电脑操作系统对应的版本下载安装即可。
* 1
* 2
* 3

5. 下载ComfyUI主程序
下载地址:https://github.com/comfyanonymous/ComfyUI
直接下载压缩包后解压缩到你希望存放的电脑路径即可。

6. 创建并激活虚拟环境
以管理员的身份打开电脑上的powershell程序,通过cd命令进入到你ComfyUI的目录中。输入命令:python -m venv
venv创建虚拟环境。

然后你便可以在你ComfyUI目录中看到创建了存放虚拟环境的venv文件夹。
然后输入命令:.\venv\Scripts\Activate激活虚拟环境。

如果你在激活虚拟环境时候报错。

可以输入命令:Get-ExecutionPolicy来查看当前的执行策略,如果是Restricted的状态,可以再输入命令:Set-
ExecutionPolicy RemoteSigned来修改策略,修改完策略后你可以重新输入命令激活虚拟环境了。
7. 安装依赖
打开ComfyUI根目录内的requirements.txt文件查看需要安装的所有环境,torch之后单独安装,可以在txt文档内把它删除后保存。

回到PowerShell中分别输入以下两行命令:
pip install torch torchvision torchaudio --index-url
pip install -r requirements.txt
国内用户网速慢的话可以输入:
pip install torch2.1.0+cu118 torchvision0.16.0+cu118 torchaudio==2.1.0+cu118
-i --trusted-host mirrors.aliyun.com
–default-timeout=10000 -f pip install -r requirements.txt -i
等待下载安装完成。

8. 运行ComfyUI
输入命令:python main.py即可。你便可以根据提示打开链接访问使用。
9. 部署模型文件
如果你现在没有任何模型文件,是不能文生图的,所以你需要下载模型放置在models文件夹下的相应模型文件夹内。
重启ComfyUI后生效。
10. 安装ComfyUI Manager
**下载地址:https://github.com/ltdrdata/ComfyUI-Manager
**
通过命令cd custom_nodes进入该文件夹内。
然后通过命令在虚拟环境中克隆安装:
git clone https://github.com/ltdrdata/ComfyUI-Manager.git
或者国内:
git clone https://mirror.ghproxy.com/https://github.com/ltdrdata/ComfyUI-
Manager.git

然后输入命令cd…回到ComfyUI目录内后再次执行python main.py便会安装后进入系统,进去检查以下ComfyUI
Manager是否已经成功安装。

11. 手动安装插件
对于很多朋友来说需要手动安装插件,那就需要通过cd命令进入到custom_nodes文件夹内,然后在虚拟环境中执行。
然后通过命令在虚拟环境中克隆安装:git clone 插件的网址

12. 核对插件所需的依赖
我们下载完插件后需要核对一下插件所需的依赖在你虚拟环境中是否已经安装。
每个插件的文件夹内都有一个requirements.txt文档,里面列出了该插件所需的依赖,你可以到ComfyUI目录下的venv\Lib\site-
packages文件夹内查看是否存在相应的依赖。

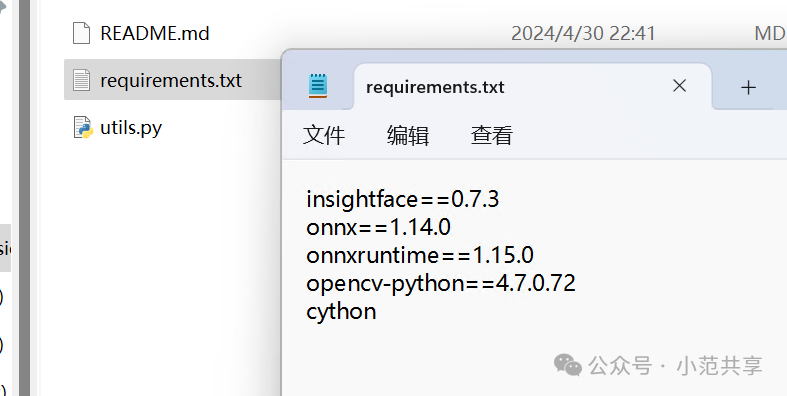
你也需要对比一下不同插件所需的依赖的区别,如果碰到两个插件都需要同一个依赖,需要统一一下两个依赖的名称,避免重复安装,因为有些依赖后面指定了版本号。

如果在启动后安装依赖报错的话也可以手动安装相关依赖。

13. 启动命令
最后我再提供一些启动命令供大家使用。(务必进入ComfyUI目录后执行)
CPU启动:
.\venv\Scripts\Activate
python main.py --cpu --windows-standalone-build --listen 0.0.0.0
pause
显存3G以下显卡启动:
.\venv\Scripts\Activate
python main.py --lowvram --windows-standalone-build --listen 0.0.0.0
pause
nvidia显卡启动:
.\venv\scripts\activate
python main.py --windows-standalone-build --listen 0.0.0.0
pause

问:我该如何选择合适的模型?
答:选择合适的模型取决于您要生成的图像类型和风格。建议您尝试不同的模型,找到最适合您需求的模型。
问:如何提高图像质量?
答:您可以通过以下方式提高图像质量:
-
使用更高分辨率的模型。
-
增加生成步骤数。
-
调整参数以获得更好的效果。
问:我遇到了一些问题,如何解决?
答:您可以参考 ComfyUI 官方文档或社区论坛寻求帮助。
总结
Stable Diffusion ComfyUI 是一款功能强大且易于使用的本地文本转图像工具。它可以让您轻松创作令人惊叹的图像,并探索各种创意可能性。
这里直接将该软件分享出来给大家吧~
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!

















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









