






 本文围绕Linux内核中的自旋锁和rt_mutex展开。先介绍未合入RT补丁时spinlock_t的代码及调用流程,指出其实时性不强;接着说明RT实时补丁下spinlock_t由rt_mutex组成,分析rt_mutex实现及解决优先级翻转问题的方法;最后解释内核中spinlock_t和raw_spinlock_t的使用区别。
本文围绕Linux内核中的自旋锁和rt_mutex展开。先介绍未合入RT补丁时spinlock_t的代码及调用流程,指出其实时性不强;接着说明RT实时补丁下spinlock_t由rt_mutex组成,分析rt_mutex实现及解决优先级翻转问题的方法;最后解释内核中spinlock_t和raw_spinlock_t的使用区别。
一、代码
自旋锁:spinlock_t
1、未合入RT补丁
路径:include/linux/spinlock_types_nort.h
typedef struct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
# define LOCK_PADSIZE (offsetof(struct raw_spinlock, dep_map))
struct {
u8 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
};
#endif
};
} spinlock_t;
解析:
在 Linux 内核中,offsetof 是一个宏定义,用于计算结构体中成员的偏移量(offset)。它定义在 <stddef.h> 头文件中。
offsetof 宏的原型如下:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
参数说明:
TYPE:结构体类型的名称。MEMBER:结构体中的成员名称。
offsetof 宏的作用是计算结构体中某个成员相对于结构体起始位置的偏移量。它通过将一个空指针转换为结构体指针,然后获取成员的地址,最后计算地址的差值得到偏移量。
使用 offsetof 宏可以方便地获取结构体成员的偏移量,通常用于内核开发中的数据结构操作。例如,在内核中,可以使用 offsetof 宏来访问结构体中的成员,或者在结构体数组中进行偏移量计算和指针操作。
需要注意的是,offsetof 宏在编译时进行计算,因此它是一个静态的偏移量计算方法,不会在运行时产生额外的开销。
调用流程:
static __always_inline void spin_lock(spinlock_t *lock)
{
raw_spin_lock(&lock->rlock);
}
=>
#define raw_spin_lock(lock) _raw_spin_lock(lock)
=>
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
=>
如果do_raw_spin_trylock 获取不到锁,就执行do_raw_spin_trylock 函数
=> do_raw_spin_trylock => arch_spin_lock()
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 newval;
arch_spinlock_t lockval;
prefetchw(&lock->slock);
__asm__ __volatile__(
"1: ldrex %0, [%3]\n"
" add %1, %0, %4\n"
" strex %2, %1, [%3]\n"
" teq %2, #0\n"
" bne 1b"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
while (lockval.tickets.next != lockval.tickets.owner) {
wfe();
lockval.tickets.owner = READ_ONCE(lock->tickets.owner);
}
smp_mb();
}
结论:如果Linux 内核没有打实时补丁,spinlock_t 和raw_spinlock_t 一样,不允许抢占调度,不允许睡眠。此时的实时性不强,下面在看实时补丁如何让中断线程化后,中断函数中的 spinlock_t 具有可抢占调度.
2、RT实时补丁
有两个 struct mutex 头文件,一个是include/linux/mutex.h ,一个是 include/linux/mutex_rt.h
一个路径:include/linux/mutex.h
mutex:
struct mutex {
atomic_long_t owner;
spinlock_t wait_lock;
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
struct list_head wait_list;
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
从定义里可以看出来 (1)互斥锁的实现里使用了一个原子变量,1表示锁没有被占用,小于1的值表示锁被占用。 (2)wait_lock是防止在操作wait_list的时候出现并发引起的数据错误
void __sched mutex_lock(struct mutex *lock)
{
might_sleep();
if (!__mutex_trylock_fast(lock))
__mutex_lock_slowpath(lock);
}
EXPORT_SYMBOL(mutex_lock);
注意:mutex_lock分为快速路径和慢速路径两个;而且执行之前还会判断是否被调度出去;是无私奉献的锁;
__mutex_trylock_fast(lock),这个函数主要:如果锁的owner是zero,就替换成当前进程的struct task_struct 指针;
__mutex_lock_slowpath(lock),这个函数是重中之重。
__mutex_lock_slowpath(lock)=》__mutex_lock_common(...)
__mutex_lock_common是整个互斥锁加锁的重中之重,用preempt_disable关闭抢占,并且多次尝试再次拿锁,尽可能避免进入到操作唤醒队列以提升性能;重点看__mutex_lock_common 这个函数;
由此,可以总结出自旋锁和互斥体选用的3项原则。 1)当锁不能被获取到时,使用互斥体的开销是进程上下文切换时间,使用自旋锁的开销是等待获取自旋锁(由临界区执行时间决定)。若临界区比较小,宜使用自旋锁,若临界区很大,应使用互斥体。 2)互斥体所保护的临界区可包含可能引起阻塞的代码,而自旋锁则绝对要避免用来保护包含这样代码的临界区。因为阻塞意味着要进行进程的切换,如果进程被切换出去后,另一个进程企图获取本自旋锁,死锁就会发生。 3)互斥体存在于进程上下文,因此,如果被保护的共享资源需要在中断或软中断情况下使用,则在互斥体和自旋锁之间只能选择自旋锁。当然,如果一定要使用互斥体,则只能通过mutex_trylock()方式进行,不能获取就立即返回以避免阻塞。
一个路径:include/linux/mutex_rt.h
struct mutex {
struct rt_mutex lock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
注意:在编程时,根据#include 不同的头文件,实际分别使用的是 mutex 和rt_mutex.
spinlock_t :
头文件路径:include/linux/spinlock_types_rt.h
typedef struct spinlock {
struct rt_mutex lock; // spinlock_t 的底层还是使用 rt-mutex
unsigned int break_lock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
} spinlock_t;
#ifdef CONFIG_PREEMPT_RT
# include <linux/spinlock_rt.h>
extern void
__rt_spin_lock_init(spinlock_t *lock, const char *name, struct lock_class_key *key);
#define spin_lock_init(slock) \
do { \
static struct lock_class_key __key; \
\
rt_mutex_init(&(slock)->lock); \
__rt_spin_lock_init(slock, #slock, &__key); \
} while (0)
注意:打完实时补丁的spinlock_t 是由rt_mutex组成,struct rt_mutex 是由 struct raw_spinlock 组成,所以重点在于rt_mutex的实现;内核打上了PREEMPT_RT补丁之后支持完全可抢占,中断处理将线程化,线程化之后允许抢占和休眠,因此原本中断处理中使用的spinlock,实际上也将替换为使用rt_mutex;原本的spin_lock,是禁止抢占的,所以中断线程化,就需要适配所有中断里的spin_lock的功能,就需要封装一层,使用rt_mutex;
重点来了,看rt_mutex是如何实现的?rt_mutex是如何解决优先级翻转的问题。
struct rt_mutex {
raw_spinlock_t wait_lock;
struct rb_root_cached waiters;
struct task_struct *owner;
int save_state;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
rt_mutex通过优先级继承解决了优先级翻转的问题。
调度函数优先级继承算法:
rt_mutex的实现在内核的kernel/locking/rtmutex.c,主要涉及了下面三个数据类型:
struct rt_mutex {
raw_spinlock_t wait_lock;
struct rb_root_cached waiters;
struct task_struct *owner;
int save_state;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
struct rt_mutex_waiter {
struct rb_node tree_entry;
struct rb_node pi_tree_entry;
struct task_struct *task;
struct rt_mutex *lock;
int prio;
bool savestate;
u64 deadline;
};
struct task_struct{
...
spinlock_t alloc_lock;
/* Protection of the PI data structures: */
raw_spinlock_t pi_lock;
struct wake_q_node wake_q;
struct wake_q_node wake_q_sleeper;
#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task: */
struct rb_root_cached pi_waiters;
/* Updated under owner's pi_lock and rq lock */
struct task_struct *pi_top_task;
/* Deadlock detection and priority inheritance handling: */
struct rt_mutex_waiter *pi_blocked_on;
#endif
.....
}
- 在struct rt_mutex中记录了owner和所有的waiters(进程),使用红黑树实现,称为Mutex Waiter List,优先级最高的那一个叫top waiter。
- struct rt_mutex_waiter是用来链接rt_mutex和task_struct的数据结构,保存了waiter是哪个进程(task_struct)在等待哪个lock(rt_mutex)
- 在大名鼎鼎的struct task_struct中同样有一个waiters列表,使用红黑树实现,称为Task PI List列表中包含此进程持有所有rt_mutex的top waiter,称作top pi waiter。
有了这三种数据类型,就能组成PI chain,也就是优先级继承链,例如:
- E -> L4 -> D -> L3 -> C ->L2 -> B -> L1 -> A
这个Pi chain表示进程E在等L4(rt_mutex)的持有者D释放锁,而D又在等L3的持有者释放锁,以此类推,到A为终点,A是owner,不是waiter。这个Pi chain用刚提到的三个数据类型表示就变成下面这个样子。
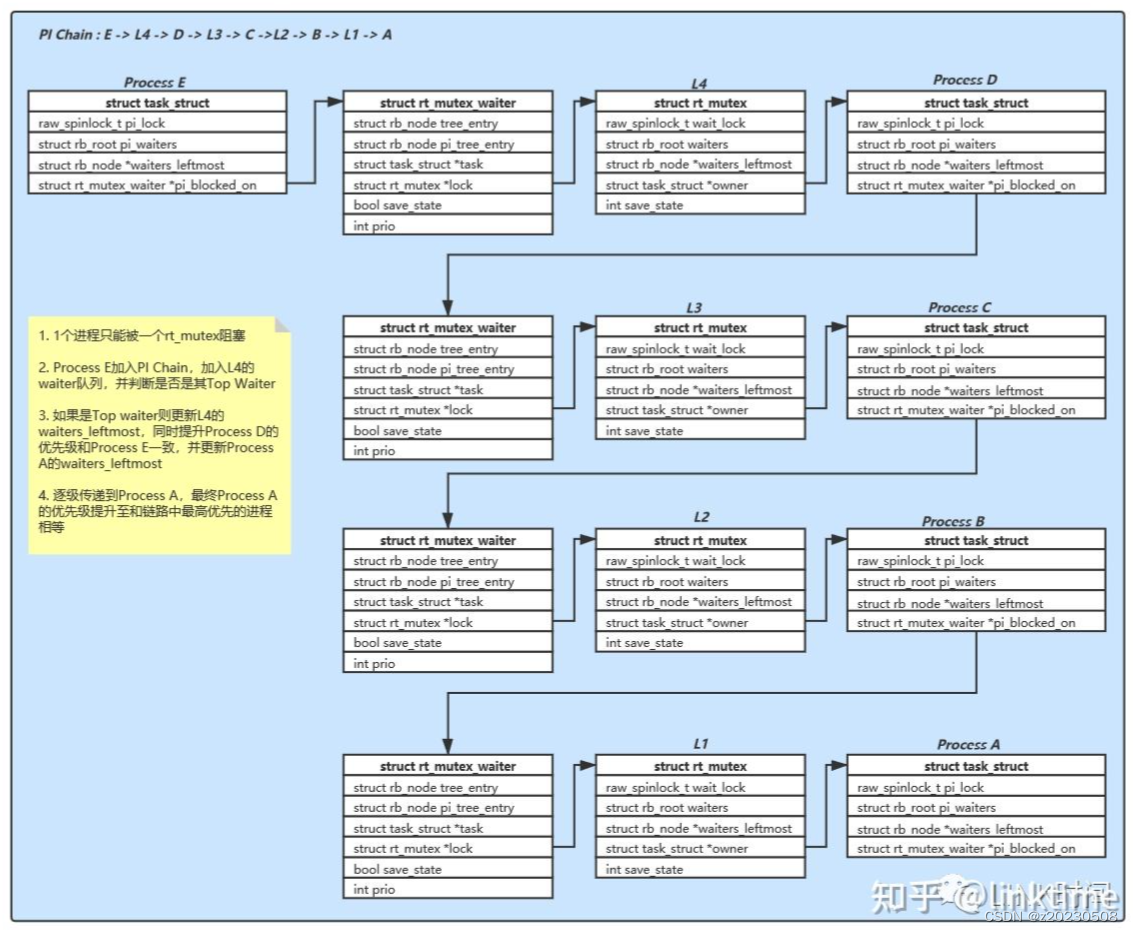
假如进程E有最高优先级,当E加入到这个继承链时,将加入到L4的waiters中,并成为top waiter,由于L4的owner是D,D将更新waiters,E成为D进程的top pi waiter,为了避免发生优先级翻转,持有L4的D临时提升优先级与E相等。由于D的优先级提升,并且D是L3的waiter,这个优先级继承的动作将沿着继承链传播,直到最后一个进程A。这就是RT-mutex优先级继承的核心机制。
由于一个rt_mutex可以有多个waiter,同一个进程虽然只能是一个rt_mutex的waiter,但是可以持有多个rt_mutex,PI chain还有可以不少变化。
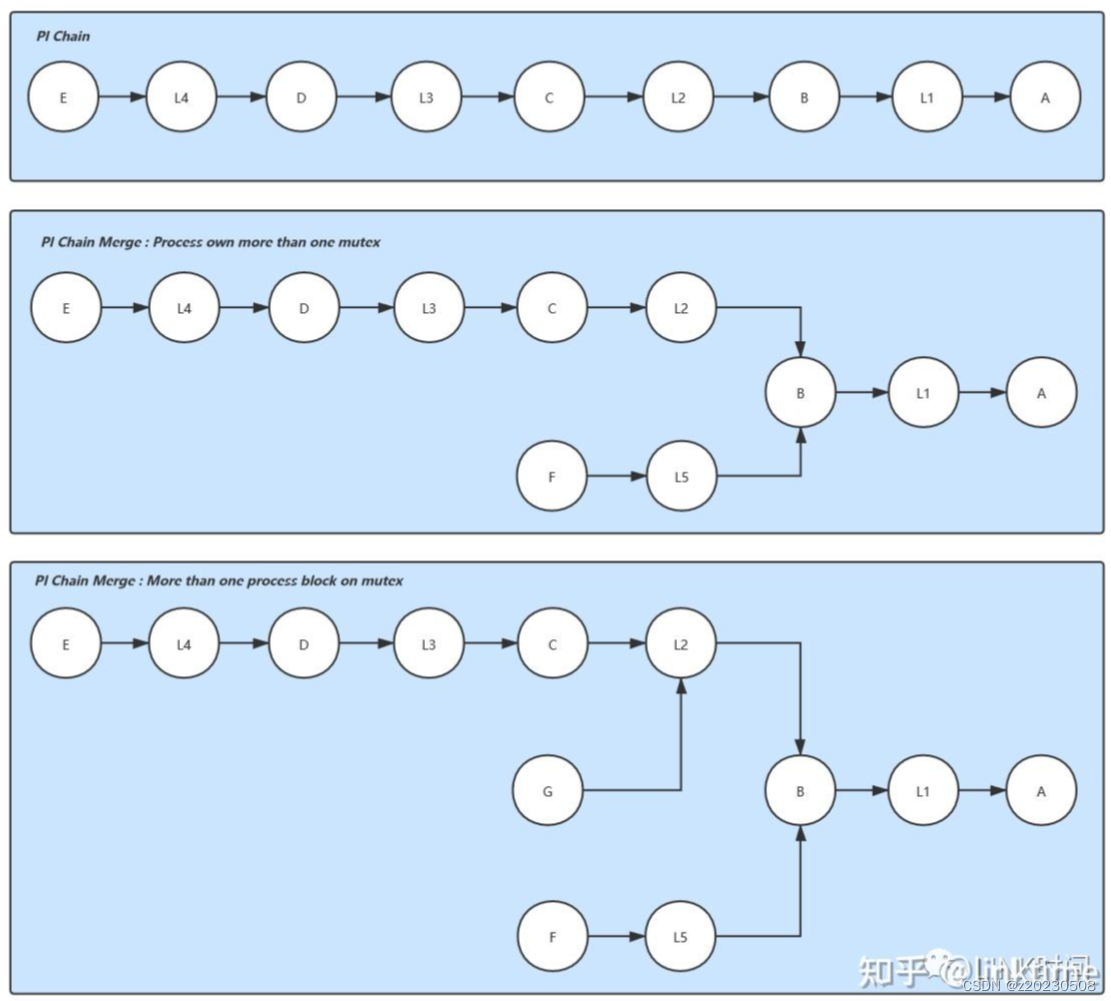
除了在完全可抢占时代替spinlock,rt_mutex还用在PI-futex,当用户态线程使用pthread_cond_broadcast时所有被唤醒的task也使用了rt_mutex保证所有线程按照优先级顺序依次唤醒。
下面来看内核源码中分析:
1、函数接口:rt_mutex_lock()
void __sched rt_mutex_lock(struct rt_mutex *lock)
{
__rt_mutex_lock(lock, 0);
}
EXPORT_SYMBOL_GPL(rt_mutex_lock);
接着
static inline void __rt_mutex_lock(struct rt_mutex *lock, unsigned int subclass)
{
rt_mutex_lock_state(lock, subclass, TASK_UNINTERRUPTIBLE);
}
接着
static inline int __sched rt_mutex_lock_state(struct rt_mutex *lock,
unsigned int subclass, int state)
{
int ret;mutex_acquire(&lock->dep_map, subclass, 0, _RET_IP_);
ret = __rt_mutex_lock_state(lock, state);
if (ret)
mutex_release(&lock->dep_map, _RET_IP_);
return ret;
}
int __sched __rt_mutex_lock_state(struct rt_mutex *lock, int state)
{
might_sleep();
return rt_mutex_fastlock(lock, state, NULL, rt_mutex_slowlock);
}
这个函数中,rt_mutex_fastlock() 快速获取到锁,不会导致优先级翻转,也就是高优先级的进程拿到锁了,可喜可贺。
否则,进入慢速路径函数:rt_mutex_slowlock()
static int __sched
rt_mutex_slowlock(struct rt_mutex *lock, int state,
struct hrtimer_sleeper *timeout,
enum rtmutex_chainwalk chwalk,
struct ww_acquire_ctx *ww_ctx)
{
struct rt_mutex_waiter waiter;
unsigned long flags;
int ret = 0;rt_mutex_init_waiter(&waiter, false);
/*
* Technically we could use raw_spin_[un]lock_irq() here, but this can
* be called in early boot if the cmpxchg() fast path is disabled
* (debug, no architecture support). In this case we will acquire the
* rtmutex with lock->wait_lock held. But we cannot unconditionally
* enable interrupts in that early boot case. So we need to use the
* irqsave/restore variants.
*/
raw_spin_lock_irqsave(&lock->wait_lock, flags);ret = rt_mutex_slowlock_locked(lock, state, timeout, chwalk, ww_ctx,
&waiter);raw_spin_unlock_irqrestore(&lock->wait_lock, flags);
/* Remove pending timer: */
if (unlikely(timeout))
hrtimer_cancel(&timeout->timer);debug_rt_mutex_free_waiter(&waiter);
return ret;
}
接着 rt_mutex_slowlock_locked
int __sched rt_mutex_slowlock_locked(struct rt_mutex *lock, int state,
struct hrtimer_sleeper *timeout,
enum rtmutex_chainwalk chwalk,
struct ww_acquire_ctx *ww_ctx,
struct rt_mutex_waiter *waiter)
{
int ret;#ifdef CONFIG_PREEMPT_RT
if (ww_ctx) {
struct ww_mutex *ww;ww = container_of(lock, struct ww_mutex, base.lock);
if (unlikely(ww_ctx == READ_ONCE(ww->ctx)))
return -EALREADY;
}
#endif/* Try to acquire the lock again: */
if (try_to_take_rt_mutex(lock, current, NULL)) { //进入优先级继承之前,再次尝试获取锁
if (ww_ctx)
ww_mutex_account_lock(lock, ww_ctx);
return 0;
}set_current_state(state);
/* Setup the timer, when timeout != NULL */
if (unlikely(timeout))
hrtimer_start_expires(&timeout->timer, HRTIMER_MODE_ABS);ret = task_blocks_on_rt_mutex(lock, waiter, current, chwalk);
if (likely(!ret)) {
/* sleep on the mutex */
ret = __rt_mutex_slowlock(lock, state, timeout, waiter,
ww_ctx);
} else if (ww_ctx) {
/* ww_mutex received EDEADLK, let it become EALREADY */
ret = __mutex_lock_check_stamp(lock, ww_ctx);
BUG_ON(!ret);
}if (unlikely(ret)) {
__set_current_state(TASK_RUNNING);
remove_waiter(lock, waiter);
/* ww_mutex wants to report EDEADLK/EALREADY, let it */
if (!ww_ctx)
rt_mutex_handle_deadlock(ret, chwalk, waiter);
} else if (ww_ctx) {
ww_mutex_account_lock(lock, ww_ctx);
}/*
* try_to_take_rt_mutex() sets the waiter bit
* unconditionally. We might have to fix that up.
*/
fixup_rt_mutex_waiters(lock);
return ret;
}
接着 task_blocks_on_rt_mutex
/*
* Task blocks on lock.
*
* Prepare waiter and propagate pi chain
*
* This must be called with lock->wait_lock held and interrupts disabled
*/
static int task_blocks_on_rt_mutex(struct rt_mutex *lock,
struct rt_mutex_waiter *waiter,
struct task_struct *task,
enum rtmutex_chainwalk chwalk)
{
struct task_struct *owner = rt_mutex_owner(lock);
struct rt_mutex_waiter *top_waiter = waiter;
struct rt_mutex *next_lock;
int chain_walk = 0, res;lockdep_assert_held(&lock->wait_lock);
/*
* Early deadlock detection. We really don't want the task to
* enqueue on itself just to untangle the mess later. It's not
* only an optimization. We drop the locks, so another waiter
* can come in before the chain walk detects the deadlock. So
* the other will detect the deadlock and return -EDEADLOCK,
* which is wrong, as the other waiter is not in a deadlock
* situation.
*/
if (owner == task)
return -EDEADLK;raw_spin_lock(&task->pi_lock);
/*
* In the case of futex requeue PI, this will be a proxy
* lock. The task will wake unaware that it is enqueueed on
* this lock. Avoid blocking on two locks and corrupting
* pi_blocked_on via the PI_WAKEUP_INPROGRESS
* flag. futex_wait_requeue_pi() sets this when it wakes up
* before requeue (due to a signal or timeout). Do not enqueue
* the task if PI_WAKEUP_INPROGRESS is set.
*/
if (task != current && task->pi_blocked_on == PI_WAKEUP_INPROGRESS) {
raw_spin_unlock(&task->pi_lock);
return -EAGAIN;
}BUG_ON(rt_mutex_real_waiter(task->pi_blocked_on));
waiter->task = task;
waiter->lock = lock;
waiter->prio = task->prio;
waiter->deadline = task->dl.deadline;/* Get the top priority waiter on the lock */
if (rt_mutex_has_waiters(lock))
top_waiter = rt_mutex_top_waiter(lock);
rt_mutex_enqueue(lock, waiter);task->pi_blocked_on = waiter;
raw_spin_unlock(&task->pi_lock);
if (!owner)
return 0;raw_spin_lock(&owner->pi_lock);
if (waiter == rt_mutex_top_waiter(lock)) {
rt_mutex_dequeue_pi(owner, top_waiter);
rt_mutex_enqueue_pi(owner, waiter);rt_mutex_adjust_prio(owner); //调整锁的拥有者继承优先级,这是
if (rt_mutex_real_waiter(owner->pi_blocked_on))
chain_walk = 1;
} else if (rt_mutex_cond_detect_deadlock(waiter, chwalk)) {
chain_walk = 1;
}/* Store the lock on which owner is blocked or NULL */
next_lock = task_blocked_on_lock(owner);//递归的获取低优先级的进程阻塞的锁raw_spin_unlock(&owner->pi_lock);
/*
* Even if full deadlock detection is on, if the owner is not
* blocked itself, we can avoid finding this out in the chain
* walk.
*/
if (!chain_walk || !next_lock)
return 0;/*
* The owner can't disappear while holding a lock,
* so the owner struct is protected by wait_lock.
* Gets dropped in rt_mutex_adjust_prio_chain()!
*/
get_task_struct(owner);raw_spin_unlock_irq(&lock->wait_lock);
res = rt_mutex_adjust_prio_chain(owner, chwalk, lock,
next_lock, waiter, task); //递归的继承优先级raw_spin_lock_irq(&lock->wait_lock);
return res;
}
接着 rt_mutex_adjust_prio(owner);
static void rt_mutex_adjust_prio(struct task_struct *p)
{
struct task_struct *pi_task = NULL;lockdep_assert_held(&p->pi_lock);
if (task_has_pi_waiters(p))
pi_task = task_top_pi_waiter(p)->task;rt_mutex_setprio(p, pi_task);
}
接着rt_mutex_setprio(); 属于kernel/sched/core.c ,这是优先级继承的核心函数
到此结束,rt_mutex_lock 的慢速路径获取锁,可以调用的 kernel/sched/core.c 优先级继承算法,解决了优先级翻转的问题。
3、在内核中,结构体里包含spinlock_t 和raw_spinlock_t 两个锁
可能很多人在看到内核代码时会感到有些奇怪,为啥有些地方用的是spinlock_t,有些地方用的却是raw_spinlock_t?raw_spinlock_t不是spinlock_t的实现细节吗,我们不是应该只使用接口性的东西,而不要使用实现性的东西吗?再仔细看spinlock_t和raw_spinlock_t的实质逻辑,好像也没啥区别啊?要回答这个问题,我们就要先从一件事情谈起,RTLinux。什么是RTLinux,什么是实时性?实时性是指一个系统对外部事件响应的及时性。很多嵌入式系统的OS都是实时OS,它们可以快速地对外部事件进行响应。这倒不是因为它们有多厉害,而是因为嵌入式系统都比较简单,它们面临的环境比较简单,要做的事情也比较简单,所以能做到及时性。而Linux是一个通用操作系统内核,通用这个词就代表Linux要面临很多情况,处理很多问题,所以就很难做到及时性。做到及时性最根本的一点就是要及时处理中断,因为中断代表的就是外部事件。但是在Linux内核里,有很多需要同步的地方都会禁用中断,这就导致中断不能及时响应。Linux在处理中断的时候也会禁用中断,Linux在这方面已经想了很多办法来解决,比如尽可能地缩小中断处理程序,把事情尽量都放到软中断或者线程里面去做。当很多中断处理的事情都被放到线程中去执行了,我们又面临着另外一个问题,如何尽快地让这些线程去抢占CPU立马获得执行。当一个非常不紧急的线程正好执行到自旋锁的临界区时,我们的非常着急的中断处理线程想获得CPU却没有办法,因为自旋锁的临界区不能休眠也就是说不可抢占,我们只能干等着。因此把自旋锁变得可休眠就成为了提高Linux的实时性的重要方法。为此Ingo Molnar等人开发了一个项目RTLinux,专门来提高Linux的实时性。其中一个很重要的方法就是把自旋锁替换为可休眠锁。但是有些临界区是确实不能休眠的,那怎么办呢?这些临界区就用raw_spinlock_t,raw_spinlock_t还保持原来的自旋语义,不会休眠。到目前为止(内核版本5.15.28),RTLinux还没有合入标准内核,所以目前的标准内核里raw_spinlock_t和spinlock_t效果是一样的。但是大家在内核编程的时候还是要尽量使用spinlock_t,除非你的临界区真的不能休眠,才去使用raw_spinlock_t。

















 98
98

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









