






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
记录第一阶段(1月)
1. 深度学习方面
- 可以用两张卡跑,但是精度会严重下降,不知道是为什么
- 使用device比使用cuda更不容易报错
- 使用两张卡时要修改的:
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'#设置所有可以使用的显卡,共计四块
device_ids = [0,1]#选中其中两块
#model = nn.DataParallel(model, device_ids=device_ids)#并行使用两块
net = torch.nn.Dataparallel(model) # 默认使用所有的device_ids
#model = model.cuda()
net = HCTnet.HCTnet()
net = nn.DataParallel(net, device_ids=device_ids)
net = net.cuda()
- 并且将所有的 .to(device) 改成 .cuda()
2. 服务器使用全解
所需软件:MobaXterm + Pycharm专业版
- 使用MobaXterm连接服务器
- 输入IP地址和用户名,然后进去后打字输入密码
- 记得在data下创建个人目录,否则会将数据生成到C盘
- 修改.bashrc文件
- 在home/user下修改.bashrc
- 在文档的最后添加(记得要空两格),其中/data/Software/Anaconda/bin"是conda路径,如果使用miniconda那么就指向miniconda路径即可
export PATH="/data/Software/Anaconda/bin":$PATH
source activate base
- 激活.bashrc(在命令行中输入)
source ~/.bashrc
- pycharm设置
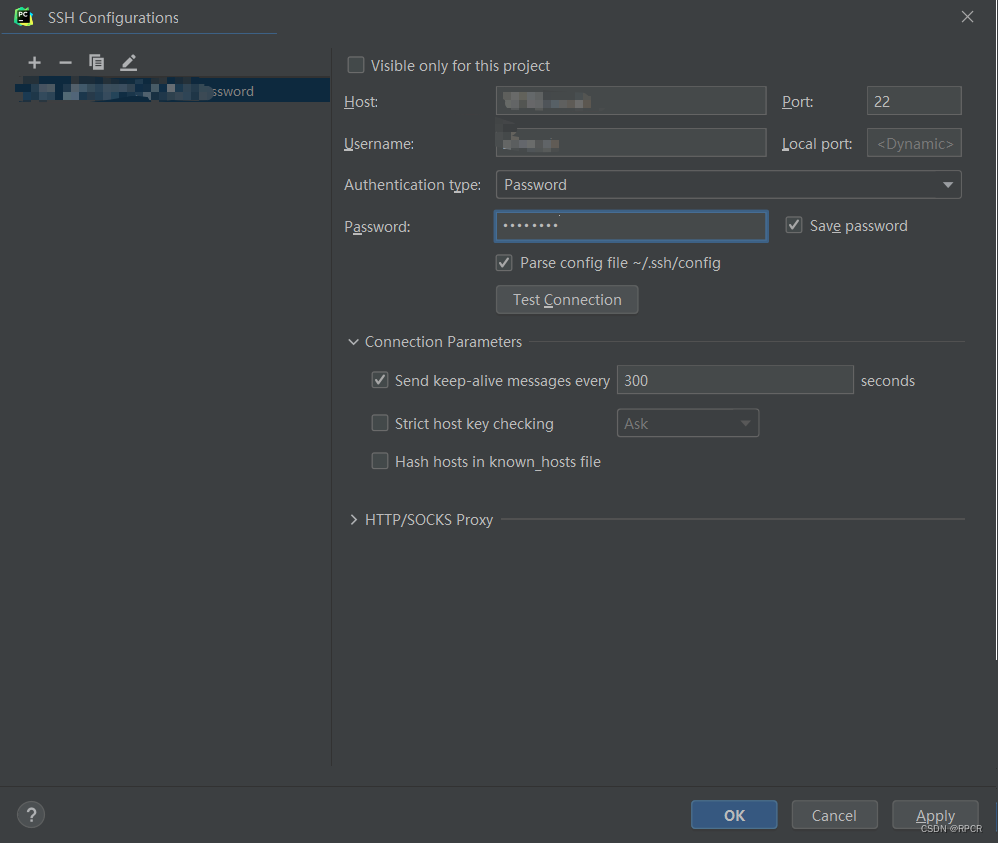
- 添加SSH服务(注意添加密码)
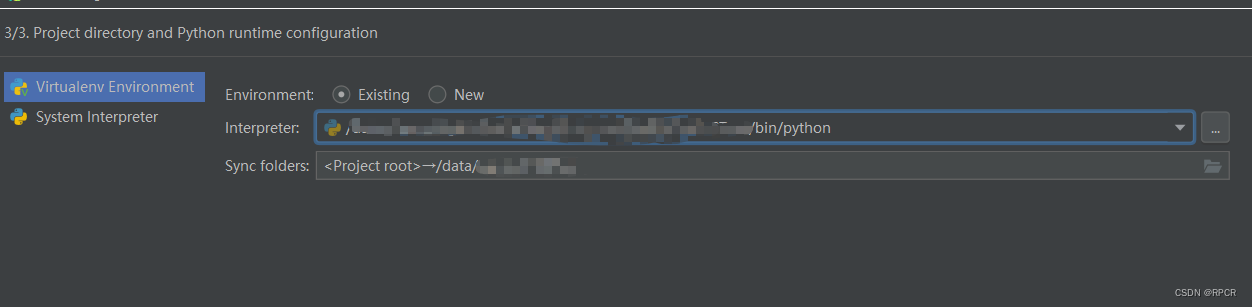
- 添加环境与同步目录
- 添加SSH服务(注意添加密码)
- 建立代码同步
参考
记录第二阶段(2月)
1.引入ssl库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
记录第三阶段(3月)
1. 将[64,64,11,11]变成[64,64,7,7]
self.conv1 = nn.Conv2d(dim, dim, kernel_size=3,padding=2,stride=2)
2. 将[64,64,11,11]变成[64,64,1,1]
self.conv1 = nn.Conv2d(dim, dim, kernel_size=11)
















 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









