






从这一篇开始,记一些北理工嵩天老师的python爬虫专题课程要点的笔记截图,目的是方便复习~并不完整涵盖所有内容
课程链接
本篇是第一周的内容
文章目录
第一单元 requests库入门
http协议




requests库的主要方法

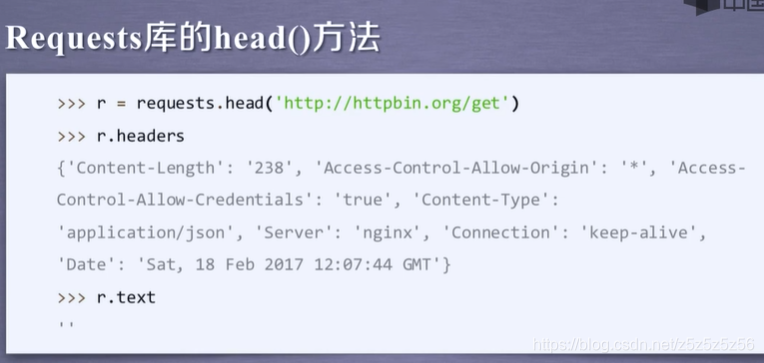
head获得简要信息节约带宽

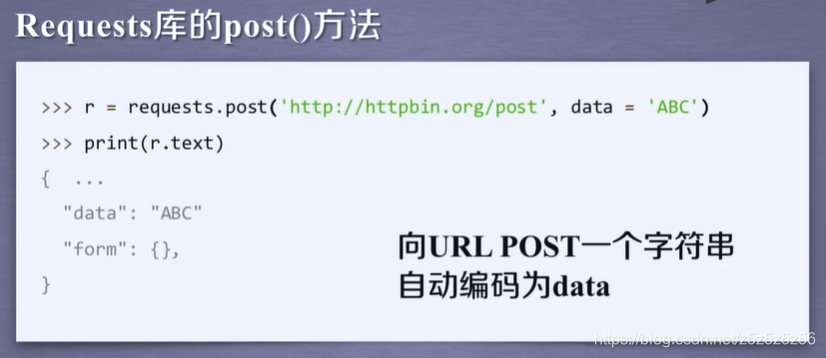
post一个字符串对默认存储到data下
post一个字典(键值对)对默认存储到表单字段下

put与post类似只不过post是附加,而put会覆盖掉原有数据
get方法


不是200都是失败的
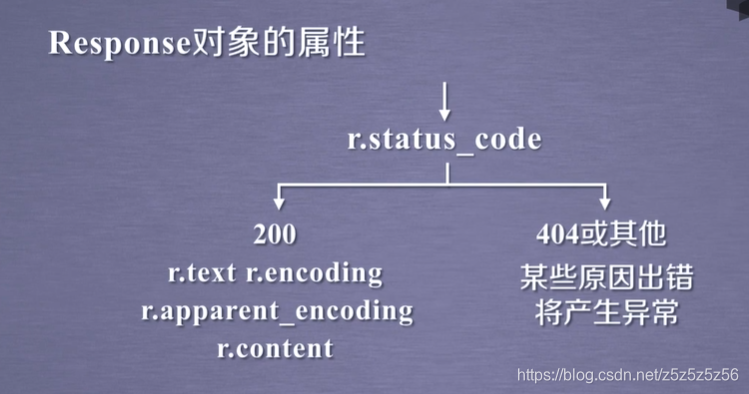

encoding只是根据header中的相关字段信息获得编码
而apparent_encoding是实实在在地从返回内容分析得出编码
把apparent_encoding(utf-8)赋值给encoding后,可读到中文
完整参数:

12个访问参数即request参数中除了params外的其他12个(见下文)
request方法

七种方法的内部实现其实都是调用了这个request方法
request方法下可选参数kwargs的13中访问控制参数:
13
- params

把一些键值对增加到url中 - data

此时是把键值对存放到url对应位置作为数据来存储 - json

作为内容,赋值到服务器的json上 - headers
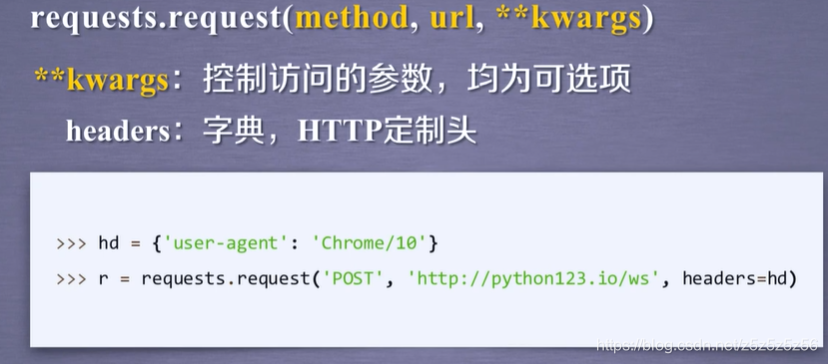
模拟Chrome10浏览器访问

7.

8

9

设置代理服务器来访问百度,可以隐藏爬虫源地址,防止爬虫逆追踪
10-13

所有的关键字:

head方法

post方法

put方法

patch方法

delete方法

因为常用所以有些参数放在前面
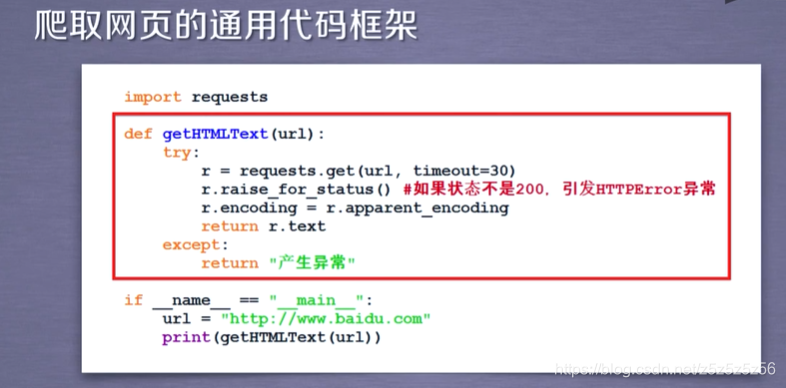
request库的代码框架
try——except

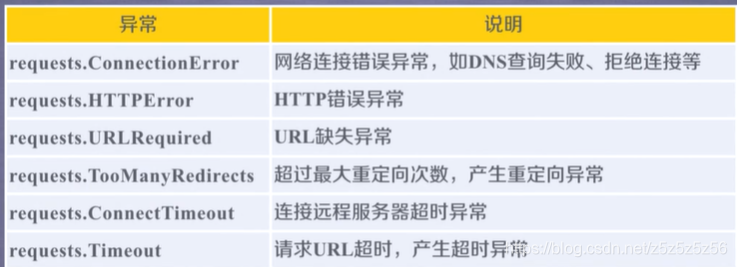
request库的异常

第二单元 robots协议
表明哪些可以爬,哪些不能爬
可以指定爬虫不能爬

*是通配符
disallow是不能访问的资源目录
没有robots协议文件的网站,则默认内容都可以爬,嘿嘿嘿~



第三单元 项目实战
-
亚马逊案例:
修改header模拟浏览器访问以爬取防护做得比较好的网页

虽然经过实际实践2021.2.15没有模拟也可以爬取到内容哈哈 -
百度360搜索案例
使用params关键词修改url内容(中的keywords)实现搜索

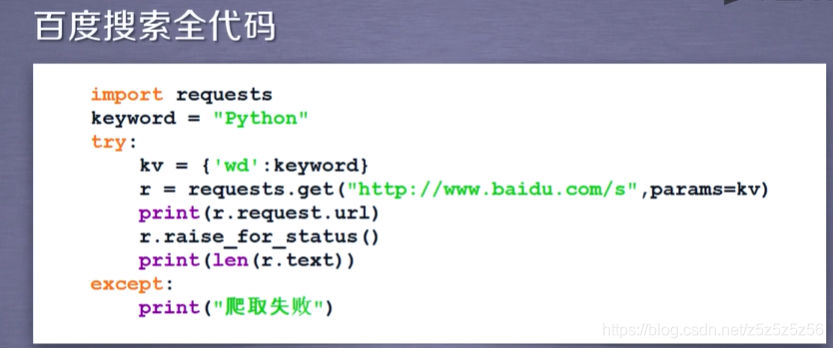
360搜索就是把键值对wd改成q即可 -
网络图片的爬取
首先随便找一个图片链接,执行以下代码
其意思是打开文件定义为文件标识符f,然后将返回的内容r写到这个文件中
r.content表示返回内容的二进制形式

这样的代码使得爬取下来的图片用源文件名
- ip地址归属地查询
这个栗子2021.2已不可用
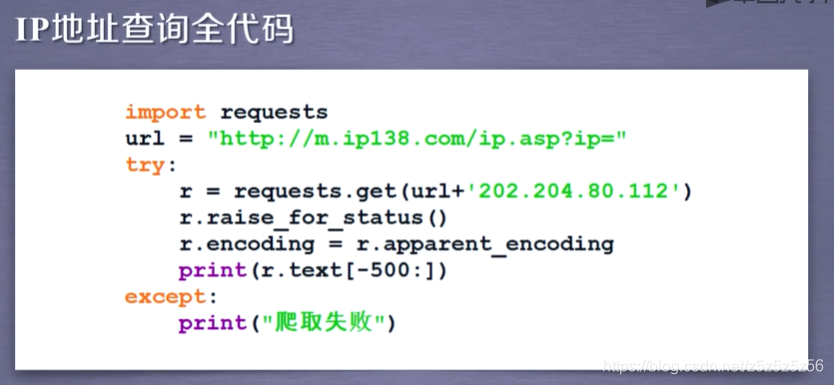
最后提醒一句 requests是库,request是发送给网络的对象
end














 9775
9775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









