





approach:
A.PCA降维
首先对sift做了pca,pca的前k个主成分保留了原始描述子的大部分能量。这样做增强了召回率,且降低了模型复杂度。
通过如下实验可以看到:

1.除去第一个主成分(2个高斯)外的所有k个维数的系数分布,都近似一个高斯分布。
2.前k个主成分维数的熵是远远大于1的。
这样说明一个问题:一个bit去描述这样一个高斯分布是远远不够的,丢失了很多信息。
B. scalable cascaded hashing
这个方法可以近似看作ANN search
给一个PSIFT数据点y,以及同样的查询点q,那么

放松成:

其中ti这个阈值由广泛实验研究决定(这什么鬼)

这里的ti指候选集相对召回率的期望(不是很好理解,x是绝对系数距离,后面会有ex),pi的估计也是一个必须的过程,这里的做法是对偶的选择配对图像,再从这些图像对中选取relevant feature pairs。根据这些样本,做PCA以后,在绝对系数距离上估计概率密度pi。
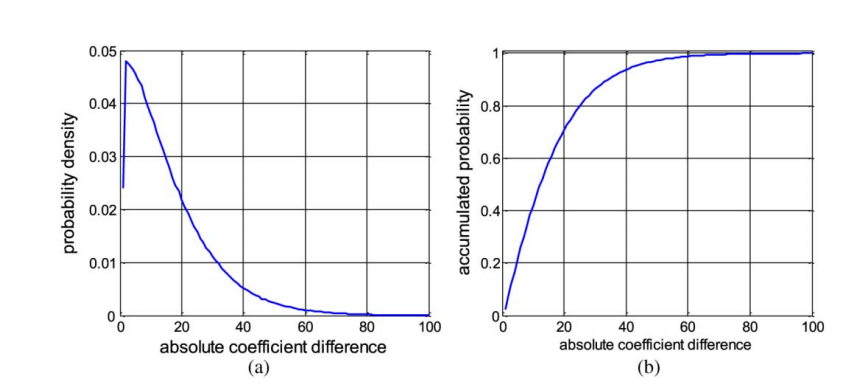
这是第一维度的pi估计图,可以发现只要选取n=40,那么就可以得到94%的 revelant true match。如果我们将每一维度串联起来,并在每一个维度选取合适的参数,那么既可以大大提高recall,并指数减少FP rate,从而减小搜索范围。
全局recall定义如下:
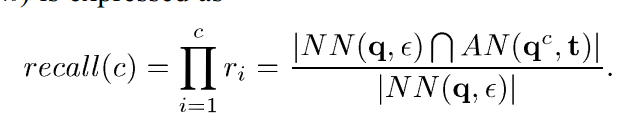
为了保证recall足够大,我们也需要设置阈值,使得ri>=cauthy。
有了上面的准备工作,我们可以提出SCH算法。

对于数据库图像:通过hash函数就会产生hash值。
对于检索图像:采用软阈值的方法,
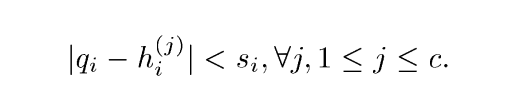
其中si=2ti,这是因为我们并不知道每一个index的feature的确切位置,所以采用软阈值策略。
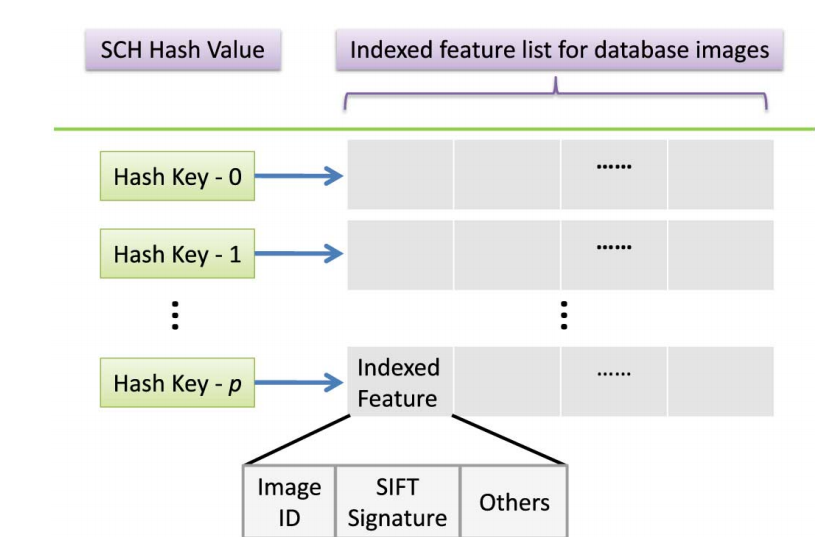
总的invert-index结构如下图
C. 二值向量匹配验证
很简单,直接截图吧:

其中z尖等于一个向量z的中值,因为不同维度之间的相对系数差被假设为稳定的的。最后计算海明距离:
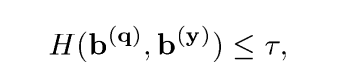
主要有四个重要参数:cauthy,tao,e,c,实验调参数。















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









