





 本文深入探讨了cmsgc和g1gc两种垃圾回收算法中的三色标记原理及其在并行执行时面临的挑战。针对并行执行可能导致的对象引用变化问题,详细介绍了IncrementalUpdate与SATB两种解决方案的特点与区别。
本文深入探讨了cmsgc和g1gc两种垃圾回收算法中的三色标记原理及其在并行执行时面临的挑战。针对并行执行可能导致的对象引用变化问题,详细介绍了IncrementalUpdate与SATB两种解决方案的特点与区别。
着色标记
我们都知道cms gc 和g1 gc 的算法都是通过对gc root 进行遍历,并进行三颜色标记,具体标记算法如下:
- 黑色(black):节点被遍历完成,而且子节点都遍历完成。
- 灰色(gray): 当前正在遍历的节点,而且子节点还没有遍历。
- 白色(white):还没有遍历到的节点,即灰色节点的子节点。
并行gc 面对的共同问题
我们都知道cmg gc 和g1 gc 都是和程序有并行执行的阶段。既然有并行,那就有可能在并行运行期间之前的标记过的对象的引用关系可能被改变,比如一个白色对象从被灰色的引用变为被黑色的对象引用。如果不做处理,那这个白色的对象会被漏掉,会被错误的回收。会导致程序错误。
这也是cms gc 和g1 gc 都有remark阶段的原因。都需要重新对被修改的card 进行扫描。
那cms gc 和g1 gc 是怎么解决这个问题的呢。而且有什么区别呢。这就需要了解cms gc 和g1 gc 所用的算法的不一样而导致不一样的解决方案了。
cms gc 是Incremental Update算法,g1 gc 是采用的 stab 算法,下面我们先讲下Incremental Update。
要知道怎么解决问题,我们先描述下问题的场景,并行gc 在什么情况下会出现漏掉活的对象,根据三色扫描算法,如果有下面两种情况发生,则会出现漏扫描的场景:
- 把一个白对象的引用存到黑对象的字段里,如果这个情况发生,因为标记为黑色的对象认为是扫描完成的,不会再对他进行扫描。只能通过灰色的对象
- 某个白对象失去了所有能从灰对象到达它的引用路径(直接或间接)
文字描述可能太抽象,通过下面的图更形象
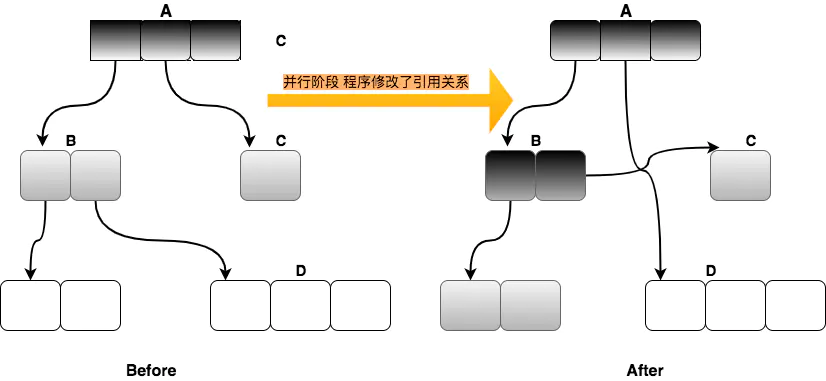
如上图所示,的对象D 同时满足上面两个条件,引用存到了黑对象A上面,同时切断了灰对象B对它的引用,那D对象将被漏扫描了。
那CMS GC和G1 GC 是怎么解决这个问题的呢?
解决这个问题可以从两个角度入手,从上面的图可以看出,指向D的这个引用从源B到目的地址A,所以就有两种算法分别是从源和目标的角度来解决,分别产生了下面两种算法:
SATB 即 Snapshot-at-beginning
satb 算法认为开始标记的都认为是活的对象,如上图所示,引用B到D 的引用改为B到C时,通过write barrier写屏障技术,会把B到D 的引用推到gc 遍历执行的堆栈上,保证还可以遍历到D对象,相对于d来说,引用从B-->A,SATB 是从源入手解决的,即上面说的第2种情况,
这也能理解为啥叫satb 了,即认为开始时所有能遍历到的对象都是需要标记的,即都认为是活的。如果我吧b = null,那么d 久是垃圾了, satb算法也还是会把D最终标记为黑色,导致D 在本轮gc 不能回收,成了浮动垃圾。
Incremental Update write barrier
Incremental Update 算法判断如果一个白色的对象由一个黑色的对象引用,即目的,如上图,D的引用由B-->A,A是目的地址,所以cms 的Incremental Update算法是从目标入手解决的,这是和SATB的第一个区别,发现这种情况时,也是通过write barrier写屏障技术,把黑色的对象重新标记为灰色,让collector 重新来扫描,活着通过mod-union table 来标记,cms 就是这样实现的,这是第二个区别,做法不一样,也是上面讲的防止第一种情况发生。
Incremental Update 和 SATB 的区别。
通过上面的分析,我们知道SATB write barrier 是认为开始标记那一刻认为都是活的,所以有可能有些已经是垃圾的对象就会也被扫描,导致 satb 相对 Incremental Update 会更多的开销,g1 gc 扫描的都是选定的固定个数的region,所以这个开销应该可控,但是而且浮动垃圾也更多。
G1选用 SATB算法的原因,推测:
1、Incremental Update每一次其实都要对对象进行扫描,所以其实SATB开销更小。其次G1之所以采用SATB是因为G1的region里面有一个hash表【RSet】,这个表里面存的都是指向当前这个region的对象的引用,所以每一次SATB只需要去region里面读取hash表里面的内容就行了。可以说是很完美的配合。
2、另外SATB并不会产生浮动垃圾,即使你把b = null,B->D的引用依旧存在region中的hash表里面(Rset)所以最终还是会通过hash表里面的引用把D给清理掉。反倒是产生浮动垃圾的其实是CMS,因为G1最终的回收其实也会产生STW也是串行的
3、查了下资料,SATB算法是能减少remark阶段的时间,是因为他忽略新增的引用,g1 remark 只是处理哪些被删除的引用,就是本来扫描开始是有引用的,但是在并发标记时,不引用了,由于stab认为开始时是活的后面就都是活的,所以在remark阶段统一处理这个引用变更的操作,这个就是浮动垃圾,你说的rset 本来就是记录引用关系的,怎么能清理呢,cms也是有浮动垃圾,一个是就本来有引用的活的,并发标记阶段不引用了,这个是和stab 一样的,还有一个就新增的stab 都不处理,cms处理了,因为remark阶段扫描dirty card 和gc root(已经扫过的不扫),所以浮动垃圾stab是更多的,可能不是在这个扫的region里,cms 因为关注了新增的这个部分,remark时间会更长这个是代价,这应该是g1 采样stab 的根本原因,个人理解。

















 169万+
169万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









