







算法基本流程
- 给数据中的每一个样本一个权重(初始权重全部相等)
- 训练数据中的每一个样本,得到第一个分类器
- 计算该分类器的错误率,根据错误率计算要给分类器分配的权重(注意这里是分类器的权重)
- 将第一个分类器分错误的样本权重增加,分对的样本权重减小(注意这里是样本的权重)
- 然后再用新的样本权重训练数据,得到新的分类器,到步骤3
- 直到步骤3中分类器错误率为0,或者到达迭代次数
- 将所有弱分类器加权求和,得到分类结果(注意是分类器权重)
步骤3中错误率的定义

分类器的权重计算公式

步骤4中权重更改公式
错误样本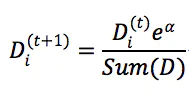
正确样本
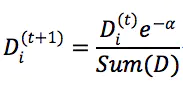
权重
权重分为样本权重和分类器权重
- AdaBoost会提高前一轮被弱(基)分类器误分的样本的权重,降低那些被正确分类得样本的权值。这样就会让被误分的样本在下一轮中被弱分类器更加关注(因为误分的样本权重大)。
- AdaBoost采取加权投票的原则,即加大分类误差率小的弱分类器的权重,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权重,使其在表决中起较小的作用。
算法基本思路
假设我们的训练集样本是

训练集的在第k个弱学习器的输出权重

由于是刚开头的尚未训练的状态,目前w1i的所有权重都是平均分配的。
此时开始训练出第一个弱分类器,并且可以得到其错误率。
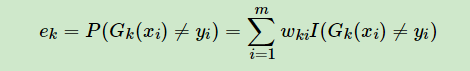
根据错误率,得到这个弱分类器的权重系数

此时可以更新样本的权重分布D,假设第k个弱分类器的样本集权重系数为D(k)=(wk1,wk2,…wkm) 则对应的第k+1个弱分类器的样本集权重系数为
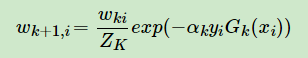
从计算公式可以看出,如果第i个样本分类错误,则yiGk(xi)<0,会导致样本的权重在第k+1个弱分类器中增大,如果分类正确,则权重在第k+1个弱分类器中减少.
这里Zk是规范化因子

最后根据设定的轮数按以上步骤进行训练,最后可以得到最终分类器。
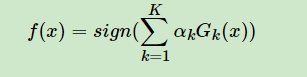














 2251
2251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









