






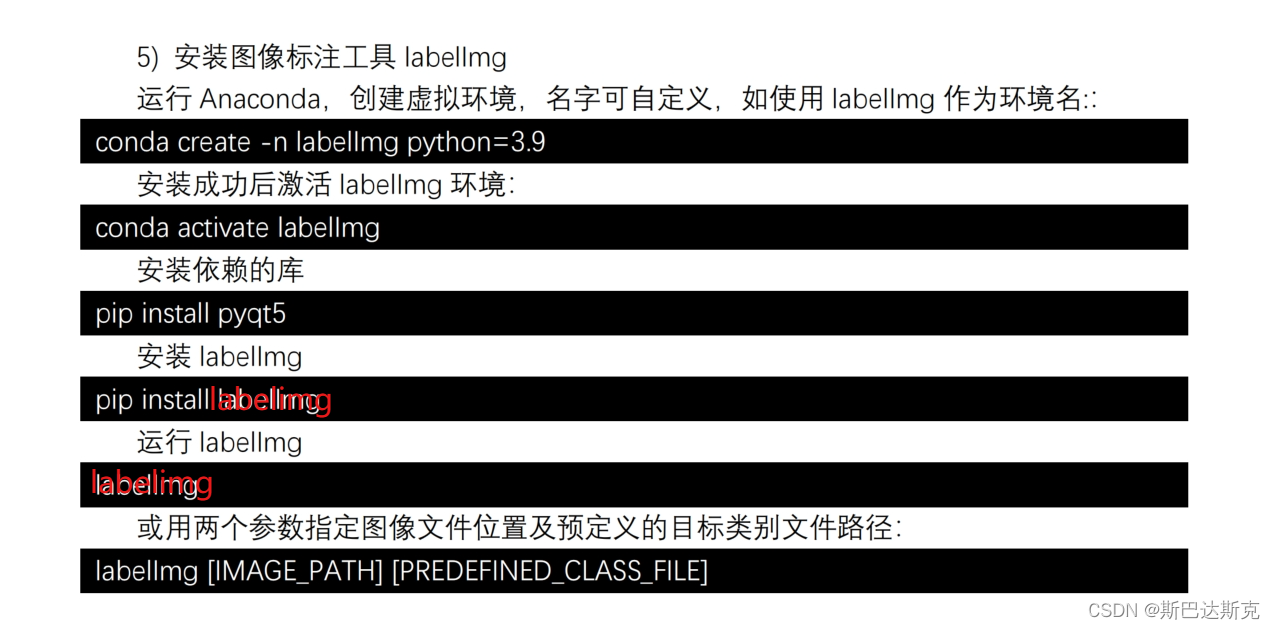
一、安装labelimg
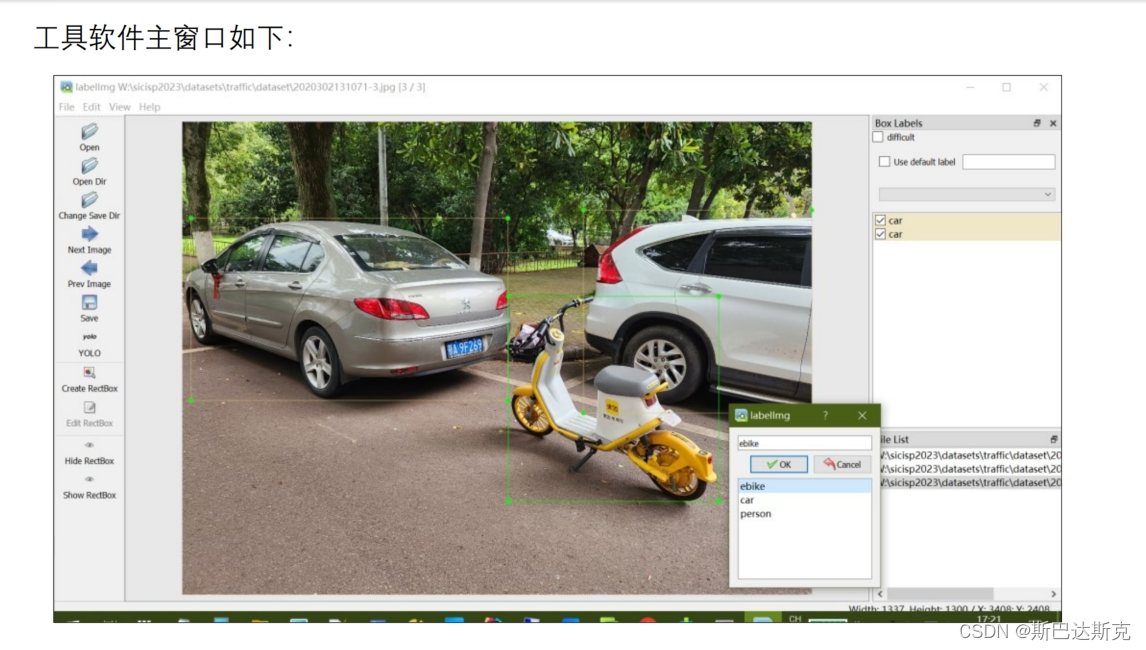
二、界面展示
三、设置预训练类别
首先找到predefined_classes.txt文件:
我的位于:D:\Softwares\Anaconda\envs\labelimg\Lib\site-packages\labelImg\data\class.txt
然后按下列格式把你要训练的类别输入进去,这样标注时就会自动显示类别:

首先找到predefined_classes.txt文件:
我的位于:D:\Softwares\Anaconda\envs\labelimg\Lib\site-packages\labelImg\data\class.txt
然后按下列格式把你要训练的类别输入进去,这样标注时就会自动显示类别:











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



















 4751
4751





