







项目描述
二元分类是机器学习中最基础的问题之一,在这份教学中,你将学会如何实作一个线性二元分类器,来根据人们的个人资料,判断其年收入是否高于 50,000 美元。我们将以两种方法: logistic regression 与 generative model,来达成以上目的,你可以尝试了解、分析两者的设计理念及差别。
实现二分类任务:
- 个人收入是否超过50000元?
数据集介绍
这个资料集是由UCI Machine Learning Repository 的Census-Income (KDD) Data Set 经过一些处理而得来。为了方便训练,我们移除了一些不必要的资讯,并且稍微平衡了正负两种标记的比例。事实上在训练过程中,只有 X_train、Y_train 和 X_test 这三个经过处理的档案会被使用到,train.csv 和 test.csv 这两个原始资料档则可以提供你一些额外的资讯。
- 已经去除不必要的属性。
- 已经平衡正标和负标数据之间的比例。
特征格式
- train.csv,test_no_label.csv。
- 基于文本的原始数据
- 去掉不必要的属性,平衡正负比例。
- X_train, Y_train, X_test(测试)
- train.csv中的离散特征=>在X_train中onehot编码(学历、状态…)
- train.csv中的连续特征 => 在X_train中保持不变(年龄、资本损失…)。
- X_train, X_test : 每一行包含一个510-dim的特征,代表一个样本。
- Y_train: label = 0 表示 “<=50K” 、 label = 1 表示 " >50K " 。
项目要求
- 请动手编写 gradient descent 实现 logistic regression
- 请动手实现概率生成模型。
- 单个代码块运行时长应低于五分钟。
- 禁止使用任何开源的代码(例如,你在GitHub上找到的决策树的实现)。
数据准备
项目数据保存在:work/data/ 目录下。
参考:https://colab.research.google.com/drive/1JaMKJU7hvnDoUfZjvUKzm9u-JLeX6B2C#scrollTo=ZEAKhugPkUyH
预处理
环境导入
import numpy as np
import pandas as pd
读取相应的数据
X_train = pd.read_csv('work/data/X_train')
X_train.shape
#(54256, 511)
Y_train = pd.read_csv('work/data/Y_train')
Y_train.shape
# (54256, 2)
数据处理
X_train.head()
| id | age | Private | Self-employed-incorporated | State government | Self-employed-not incorporated | Not in universe | Without pay | Federal government | Never worked | ... | 1.2 | Not in universe.12 | Yes.3 | No.3 | 2.3 | 0.3 | 1.3 | weeks worked in year | 94 | 95 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 33 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 52 | 0 | 1 |
| 1 | 1 | 63 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 52 | 0 | 1 |
| 2 | 2 | 71 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ... | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 3 | 3 | 43 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 52 | 0 | 1 |
| 4 | 4 | 57 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 52 | 0 | 1 |
5 rows × 511 columns
对于X_train进行处理,包括去掉无关的列、将缺示值补0,然后进行归一化:
def NormalizeFunc(X):
X = X.drop('id',axis=1)
X.fillna(0)
X_mean = X.mean()
X_std = X.std()
return (X - X_mean) / (X_std + 1e-8), X_mean, X_std
X_train, X_mean, X_std = NormalizeFunc(X_train)
X_train.shape
# (54256, 510)
对于Y_train进行处理:
Y_train = Y_train['label'].fillna(0)
因为numpy矩阵计算比较方便,故转换为numpy矩阵:
X_train = X_train.to_numpy()
Y_train = Y_train.to_numpy()
进行训练集和验证集的划分:
ratio = 0.9
train_size = int(len(X_train) * ratio)
X, Y = X_train[:train_size], Y_train[:train_size]
X_val, Y_val = X_train[train_size:], Y_train[train_size:]
X.shape,Y.shape
# ((48830, 510), (48830,))
编写基础函数
创建逻辑回归函数:
def Sigmoid(z):
# clip()可以限制输出的大小,保证输出值在一定范围内
return np.clip(1 / (1.0 + np.exp(-z)), 1e-8, 1 - (1e-8))
def Func(X,w,b):
# matmul()是矩阵乘法
return Sigmoid(np.matmul(X,w) + b)
def Predict(X,w,b):
# round()是四舍五入的实现函数,默认值为0,也就是说保留整数
# astype()是将ndarray类型转换为某一指定类型
return np.round(Func(X, w, b)).astype(np.int)
创建准确度计算函数:
def Accuracy(Y_pred, Y_label):
acc = 1 - np.mean(np.abs(Y_pred - Y_label))
return acc
创建损失函数,虽然训练过程中不会直接用到损失函数,但是也是比较直观的衡量训练效果的函数。
def Cross_entroy(Y_pred,Y_label):
return -np.dot(Y_label, np.log(Y_pred)) - np.dot((1 - Y_label), np.log(1 - Y_pred))
创建梯度计算函数:
def Gradient(X,Y_label,w,b):
Y_pred = Func(X, w, b)
pred_error = Y_label - Y_pred
w_grad = -np.sum(pred_error * X.T, 1)
b_grad = -np.sum(pred_error)
return w_grad,b_grad
在运行过程中,不希望模型一段时间内只学习正样本或者负样本,这样训练效果并不会很好,所以需要要将数据进行乱序排列,这个在机器学习中也是比较常用的。
def Shuffle(X,Y):
# 官方的该功能程序实现比较简单
# 先生成样本对应的序类
# 然后使用自带函数进行shuffle
# 返回时直接把shuffled的数据作为下标进行使用
randomize = np.arange(len(X))
np.random.shuffle(randomize)
return (X[randomize], Y[randomize])
训练过程
这里使用小批次梯度下降的方法来进行训练,这算是神经网络中比较常用的一种训练方法了。
首先初始化模型参数:
w = np.zeros((X.shape[1],)) # X.shape[1] 为每一个样本的特征数目
b = np.zeros((1,))
之后设置训练时的相关参数,这里设置step变量目的是为了随着训练的进行,learning rate的值可以逐渐减少,从而期望更好的找到global minima。仔细想想其实这里Adam也是可以用的,Adam使用的只有损失函数的梯度。
max_iter = 10
batch_size = 8
train_size = X.shape[0]
learning_rate = 0.2
step = 1
按照参考,对于损失函数和准确度进行记录,便于之后画图:
train_loss = []
dev_loss = []
train_acc = []
dev_acc = []
紧接着便是模型的训练过程:
for epoch in range(max_iter):
X, Y = Shuffle(X,Y)
# Mini-batch training
for idx in range(int(np.floor(train_size / batch_size))):
X_batch = X[idx*batch_size:(idx+1)*batch_size]
Y_batch = Y[idx*batch_size:(idx+1)*batch_size]
w_grad, b_grad = Gradient(X_batch,Y_batch,w,b)
w = w - learning_rate/np.sqrt(step) * w_grad
b = b - learning_rate/np.sqrt(step) * b_grad
step += 1
y_train_pred = Func(X,w,b)
Y_train_pred = np.round(y_train_pred)
train_acc.append(Accuracy(Y_train_pred,Y))
train_loss.append(Cross_entroy(y_train_pred,Y)/train_size)
y_val_pred = Func(X_val,w,b)
Y_val_pred = np.round(y_val_pred)
dev_acc.append(Accuracy(Y_val_pred,Y_val))
dev_loss.append(Cross_entroy(y_val_pred,Y_val)/X_val.shape[0])
print('Training loss: {}'.format(train_loss[-1]))
print('Development loss: {}'.format(dev_loss[-1]))
print('Training accuracy: {}'.format(train_acc[-1]))
print('Development accuracy: {}'.format(dev_acc[-1]))
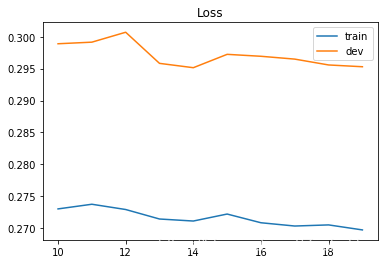
# Training loss: 0.2697334076998331
# Development loss: 0.295299642339157
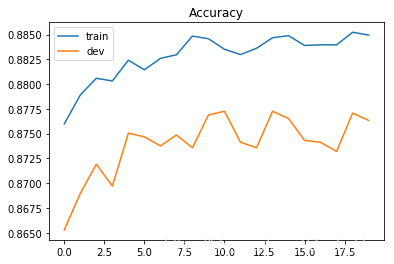
# Training accuracy: 0.8849477780053245
# Development accuracy: 0.8763361592333211
画出损失函数和准确度变化图像:
import matplotlib.pyplot as plt
# Loss curve
plt.plot(train_loss)
plt.plot(dev_loss)
plt.title('Loss')
plt.legend(['train', 'dev'])
plt.savefig('loss.png')
plt.show()
# Accuracy curve
plt.plot(train_acc)
plt.plot(dev_acc)
plt.title('Accuracy')
plt.legend(['train', 'dev'])
plt.savefig('acc.png')
plt.show()
预测测试集数据
首先导入数据:
X_test = pd.read_csv('work/data/X_test')
X_test.head()
之后对数据进行处理:
X_test = X_test.drop('id',axis=1)
X_test = (X_test - X_mean) / (X_std + 1e-8)
X_test = X_test.to_numpy()
predictions = Predict(X_test,w,b)
predictions
# array([0, 0, 0, ..., 1, 0, 0])
将预测结果保存到文件中,这个要记住……常常用,但是总记不住。
with open('work/data/logistic', 'w') as f:
f.write('id,label\n')
for i, label in enumerate(predictions):
rk/data/logistic', 'w') as f:
f.write('id,label\n')
for i, label in enumerate(predictions):
f.write('{},{}\n'.format(i, label))














 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









