






MapReduce2.0的运行原理
MR任务执行流程
提交作业->初始化作业->分配任务->执行任务->进度和状态更新->作业完成
架构图
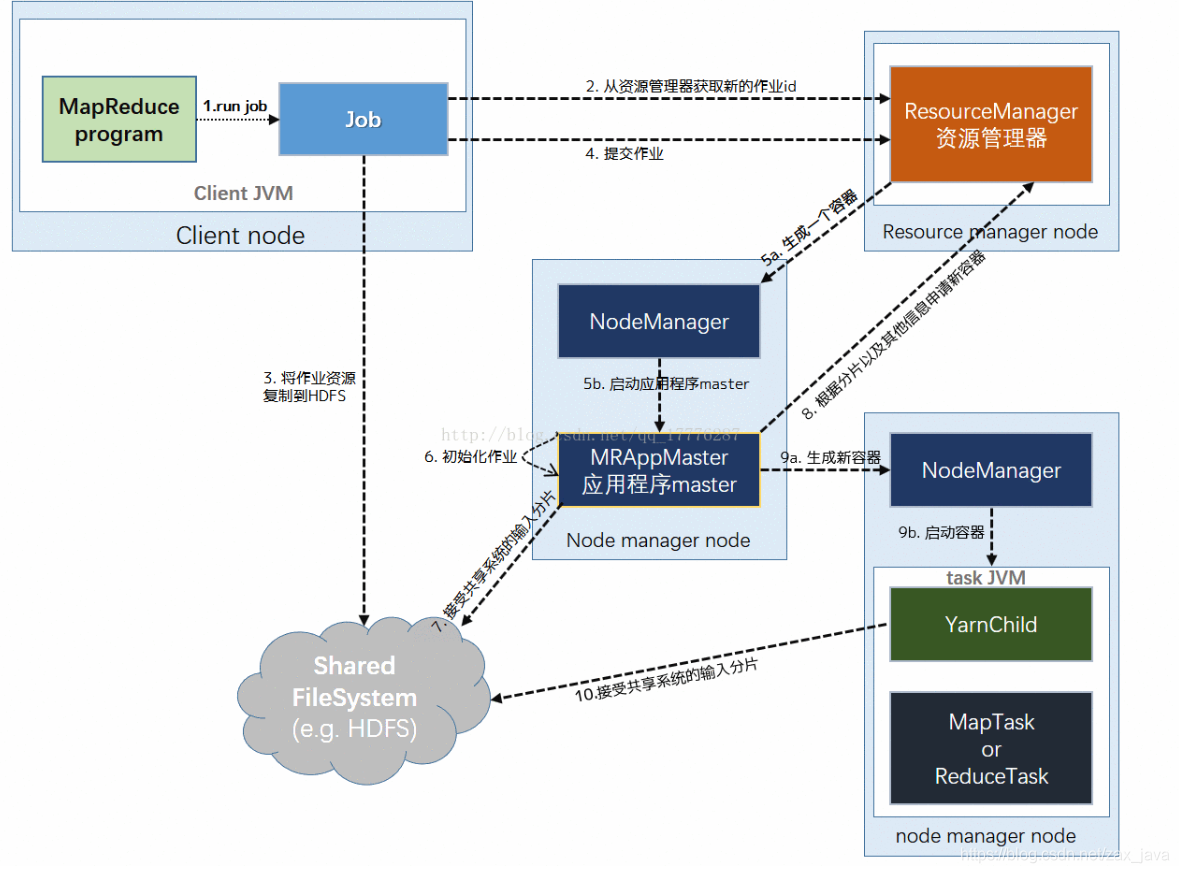
提交作业
- Client 提交到 Job
1.client程序编写好job后将调用job的submit()或waitForCompletion()方法提交作业
2.从RM中获取新的jobId,即ApplicationID - Job 提交到 RM
3.Client检查作业,计算输入分片,将作业资源(这里的资源包括作业JAR、配置和分片信息(map的并行度是切片信息决定,reduce是setNumReduceTask()决定))赋值到HDFS文件系统上
4.调用RM的submitApplication()方法提交作业
初始化作业
- 给作业分配ApplicationMaster
5.当RM检测到submitApplication()方法被调用时,将请求传递给scheduler(调度器)
scheduler分配一个container,然后RM该会在NM管理下在分配的Container中ApplicationMaster - ApplicationMaster初始化作业
6.MR作业的ApplicationMaster 是一个Java应用程序,它的主类是MRAppMaster。它对作业进行初始化,通过创建多个薄记对象以保持对作业进度的跟踪,因为它将接受来自任务的进度和完成报告(这里关联的是后面的进度和状态更新)
7.ApplicationMaster从HDFS中获取在Client计算的输入分片(主要是指map和reduce的个数)
ApplicationMaster决定如何运行构成MapReduce的各项任务,如果job小就在一台上运行就行,但大部分要申请新的container
任务分配
8.ApplicationMaster为job中的所有map、reduce向RM中请求新的container
请求也为任务指定了内存需求,在默认的情况下,map和reduce的任务都分配到1024M的内存,但这可以通过
mapreduce.map.memory.mb和mapreduce.reduce.memory.mb来设置。
任务执行
9.一旦RM的scheduler为job分配了新的container,ApplicationMaster就会通过与NM的通信来启动新的container
10.==在运行任务之前,首先将任务需要的资源本地化(包括作业的配置,JAR文件和所有来自分布式的缓存文件)==然后由主类为YarnChild的java应用程序执行
11.最后运行MR任务
任务状态的更新
- 在YARN下运行,任务每 3s通过
umbilical接口向 ApplicationMaster 汇报进度和状态(包括计数器),作为作业的汇聚视图(aggregate view)。
作业完成
- 除了向 ApplicationMaster 查询进度外,Client 每 5s还通过调用 Job 的
waitForCompletion()来检查作业是否完成(查询的间隔可以通过mapreduce.client.completion.pollinterval属性进行设置)。 - 作业完成后, ApplicationMaster 和任务容器清理其工作状态,
OutputCommitter的作业清理方法会被调用。作业历史服务器保存作业的信息供用户需要时查询。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









