







牛顿第二定律的常见表述如下:
物体加速度的大小跟作用力成正比,跟物体的质量成反比,且与物体质量的倒数成正比。
结合我们所学过的牛顿第二定律,我们知道物体的加速度a和作用力F之间的关系应该是线性关系,于是我们提出假设 a=w∗F,并进行5次实验,统计到不同的作用力下木块加速度如下表所示:
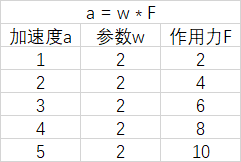
我们很快就能得出w为2,通过大量实验数据的训练,我们便可以确定参数w是物体质量的倒数(1/m)
这是人的思维,换作机器,我们改怎么才能让机器确定模型的参数w就是物体质量的倒数呢?
机器如一个机械的学生一样,只能通过尝试答对(最小化损失)大量的习题(已知样本)来学习知识(模型参数w),期望用学习到的知识w组成完整的模型H(θ,X),使模型能回答不知道答案的考试题(未知样本)
在牛顿第二定律的案例中,基于对数据的观测,我们提出的是线性假设,即作用力和加速度是线性关系,用线性方程表示。
因此,在教机器学习牛顿第二定律之前,我们先要创建牛顿第二定律的实验数据:
def creat_npy():
arr = []
for i in range(1,1001):
arr.append(i)
arr.append(2 * i)
arr = np.array(arr)
# print(arr)
np.save('arr.npy', arr)
creat_npy()

我们先用列表的形式创建实验数据,每条数据包括2项,分别是加速度与作用力,第0-1项是第一条数据,第2-3项是第二条数据,…
这样的数据肯定是不能直接用的,我们需要对数据进行处理:
def load_data():
data = np.load('arr.npy')
feature_names = [ 'F', 'a' ]
feature_num = len(feature_names)
# print(data.shape[0])
data = data.reshape([data.shape[0] // feature_num, feature_num])
ratio = 0.8
offset = int(data.shape[0] * ratio)
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
这里取了80%的数据作为训练集,20%的数据作为样本集
接下来,我们开始定义神经网络,神经网络能干什么?
简单来说,向网络中输入一个值(x),乘以权重,结果就是网络的输出值。对于牛顿第二定律,可以理解为,输入加速度a,乘以权重w,输出作用力F。
那么我们怎么样获取权重呢?
一般来说,我们会把权重设置为一个随机数,而权重可以随着网络的训练进行更新,从而找到最佳的值,这样网络就能尝试匹配输出值与目标值。
我们怎么更新权重才能使它变成我们的期望值?
讲到这里,我们就要进行分析了,这里我们用机器实际生成的权重举例:
class Network(object):
def __init__(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











