







目录
1、背景:
Manachar算法主要是处理字符串中关于回文串的问题的,它可以在 O(n) 的时间处理出以字符串中每一个字符为中心的回文串半径,由于将原字符串处理成两倍长度的新串,在每两个字符之间加入一个特定的特殊字符,因此原本长度为偶数的回文串就成了以中间特殊字符为中心的奇数长度的回文串了。
Manacher算法提供了一种巧妙的办法,将长度为奇数的回文串和长度为偶数的回文串一起考虑,具体做法是,在原字符串的每个相邻两个字符中间插入一个分隔符,同时在首尾也要添加一个分隔符,分隔符的要求是不在原串中出现,一般情况下可以用#号。
2、算法对比:
| 算法种类 | 时间复杂度 | 空间复杂度 | 简述 |
|---|---|---|---|
| 暴力枚举法 | O(N3) | O(N3) | 遍历所有子字符串,子串数为 N2,长度平均为 N/2 |
| 动态规划法 | O(N2) | O(N2) | 两层循环,外层循环从后往前扫,内层循环从当前字符扫到结尾处,省略已经判断过的记录 |
| 中心检测法 | O(N2) | O(1) | 分奇偶两种情况,以 i 为中心不断向两边扩展判断,无需额外空间 |
| 马拉车算法 | O(N) | O(N) | 从左到右扫描,省略已经判断过的记录,线性 |
3、算法过程及分析:
1:什么是回文串?
正序和反序相同的串。
2:过程分析
根据上一条可知,ABBA的回文串长度就是4。
在实际问题中,输入的数据有可能是奇数位,也有可能是偶数位,针对这种情况,可以在相邻两个字符中间插入一个分隔符,这样就能够保证所有的数据都是奇数位(如果原串是奇数位,需要添加偶数位的分隔符,如果原串是偶数位,需要添加奇数位的分隔符)
接下来就拿ABBA举例,前面有提到在每两个字符之间加入一个特殊字符: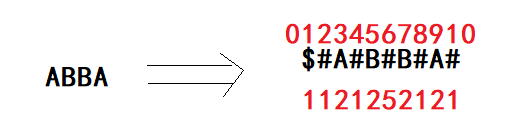
补:加入'$’后就不用特殊处理越界问题了
上图中,我们对这一串数据进行增加分隔符的操作后可以得到每一位所对应的下标(上部分的数字),那大家可以观察一下下面的数字,看看能不能思考出来下面的数字对应的是什么。
如果你能够猜到下面的数字对应的是回文串的半径长话,恭喜你,离正确的表达很近了!下面的数字对应的意思就是以当前的字母为中心的最长回文子串向左/右扩张的长度,但是这个一半的长度是通过原数组加上分隔符后得到的,那么这个值就跟原数组的最长回文子串的长度很接近了,下面咱们就来分析分析怎么求出这个长度的。

对于上图中的数据,对于第一个A来说,它的回文子串向右扩张的长度是2,也就是说出去最左边的A(只有它自己)其它的数据都是跟左边的对称的,因为我们在每两个字母之间加上了分隔符,所以最后一个肯定是‘#’,我们只需减去这个'#'求得长度,就是当前数据为中心的最长回文子串的长度了!既然如此的话,我们的任务也就变成了求最长回文子串向左/右扩张的长度,这里暂且将它定义为p[i]。
3:计算p[i]:
为了计算这个p[i],我们定义两个变量id和mx

(简单地说,这里的id表示的是使得mx和mx对称点之间距离最大的点,而mx在上图中也已经表示出来了)
我想你一定十分好奇,为什么这样呢?别着急,听我慢慢说来。
按照暴力的方法,我们是从左到右遍历一遍,那么遍历的过程中,我们会需要求出每一个 i 对应的回文字符串长度,那么通常会出现有些 i 的回文长度较短,被包括在之前的较长的回文字符串中,如果这个 i 的回文长度我们可以通过之前的数组中的某些值来求出,那么岂不是很便利?

前面我们提到过,从mx关于id的对称点到mx这一部分是当前的最长的回文串,既然如此的话我们在分析i的时候如果首先判断一下i关于id对称点j的p[j]是否在mx对称点到mx之间,如果在的话,我们直接就可以得出结论,p[i]=p[j],如果不在的话我们需要重新计算(赋初值为1),不过这样也便利了很多!
p[i]=i<mx?min(p[2*id-i],mx-i):1;
 既然说到如果不存在的例子,那么就画一个不存在的图,图中的p[i]+i已经大于mx(也就是超出可以判断的范围)了,这个时候我们需要从i开始,一点一点向右移动,来判断以该点为中心的回文串有多长(尽可能长),因为p[i]是从1开始的,我们可以直接使用while循环判断i左右p[i]位置的两个数据是否相等,如果相等就让p[i]加一。
既然说到如果不存在的例子,那么就画一个不存在的图,图中的p[i]+i已经大于mx(也就是超出可以判断的范围)了,这个时候我们需要从i开始,一点一点向右移动,来判断以该点为中心的回文串有多长(尽可能长),因为p[i]是从1开始的,我们可以直接使用while循环判断i左右p[i]位置的两个数据是否相等,如果相等就让p[i]加一。
while(new_num[i-p[i]]==new_num[i+p[i]])
p[i]++;
if(mx<i+p[i])
{
id=i;
mx=i+p[i];
}4、扩展部分:
1:求最长回文子串的长度:
Manacher算法依旧是遍历了一遍数组,我们可以定义一个标记的大值的变量,然后在遍历的过程中判断当前回文子串的长度是否大于这个变量,如果大于的话,就进行交换。
if(p[i]-1>max_len)
{
max_len=p[i]-1;
}2:求i处的最长回文子串的左右边界:
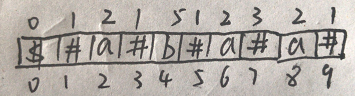
就拿图中下标为4的b来说,b的下标-(p[b的下标]-1)-1就是左边界的值(前面有提到p[i]-1代表的是回文子串的长度),b的下标+(p[b的下标]-1)-1就是有边界的值。
left=(i-p[i]+2)/2-1;
right=(i+p[i]-2)/2-1;5、代码:
int init(char *num)
{
int k=0;//k代表的是加入分隔符后的字符串的长度
new_num[k++]='$';
new_num[k++]='#';
for(int i=0;i<num_long;++i)
{
new_num[k++]=num[i];
new_num[k++]='#';
}
new_num[k]='\0';
return k;
}
void manacher(char *num)
{
int id=0,mx=0;
new_num_long=init(num);//加入分隔符的字符串的最大长度
int max_len=0;//最大的回文串长度
for(int i=0;i<new_num_long;++i)
{
p[i]=i<mx?min(p[2*id-i],mx-i):1;
while(new_num[i-p[i]]==new_num[i+p[i]])
p[i]++;
if(mx<i+p[i])
{
id=i;
mx=i+p[i];
}
if(p[i]-1>max_len)
{
max_len=p[i]-1;
}
}
}















 659
659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









