







1、读取文件
在本地创建要读取的文件如下图
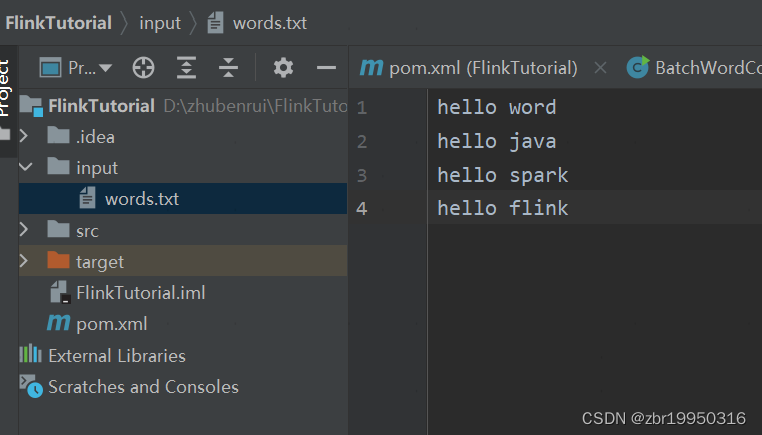
源代码如下
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception{
//1.创建流式的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2、读取文件
DataStreamSource<String> linestringDataStreamSource = env.readTextFile("input/words.txt");
//3、转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = linestringDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
})
.returns(Types.TUPLE(Types.STRING, Types.LONG));
//4、分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
//5、求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
//6、打印
sum.print();
//7、启动执行
env.execute();
}
}
编译后的运行的结果

前面的数字代表当前以本地的哪个线程来执行最终统计,结果输出的任务,对应flink运行时占据的并行资源。
需要注意的是,对flink提供的二元组而言,第一个元素就叫f0,第二个元素叫f1
制定key去做分组,把key当前对应的索引天在这里
按照当前key分组后的聚合操作
代码末尾调用env的execute方法,开始执行任务
2、读取文本流(从外部参数名提取对应主机号和端口号)
(1)用到一个工具ParameterTool,flink给我们单独提供的,用来从当前main方法的Args里边去提取参数的工具 (2)里面有一个方法叫做fromArgs,把当前参数args传进去 (3)首先得到一个String类型的hostname,当前传进来的args解析成了一个个的键值对,类似于里面保存了hashmap,类似于映射,hostname的参数名叫做host
先启动Idea的flink编程
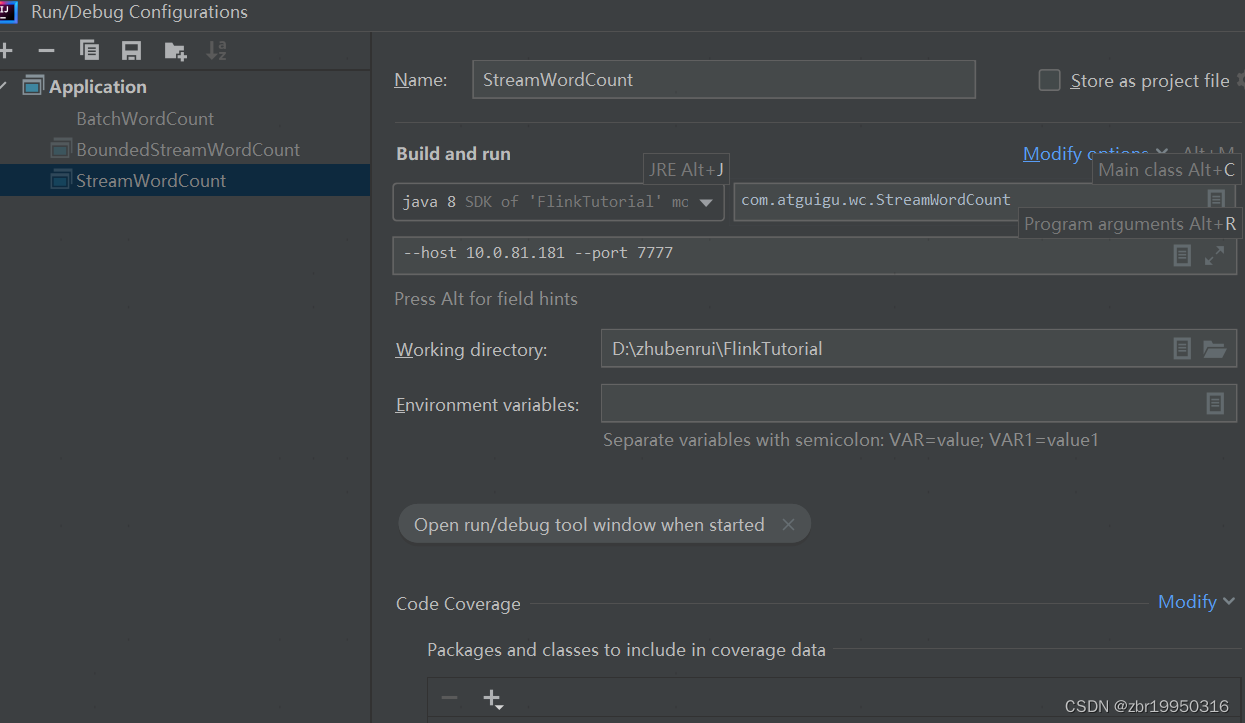
设置地址名和端口号,如下图

在Xshell连接对应端口号,如下图

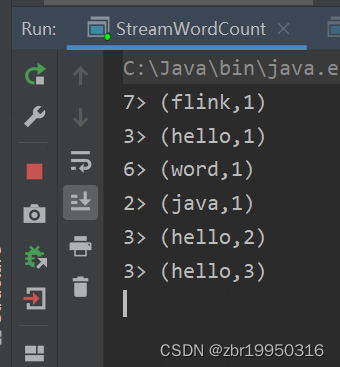
随机写入几个字符串,hello java hello flink hello word

此时在控制台就会打印出图如下图所示
代码如下
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordCount {
public static void main(String[] args) {
//1、创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//从外部参数名提取对应主机名和端口号
//用到一个工具ParameterTool,flink给我们单独提供的,用来从当前main方法的Args里边去提取参数的工具
//里面有一个方法叫做fromArgs,把当前参数args传进去
ParameterTool parameterTool = ParameterTool.fromArgs(args);
//首先得到一个String类型的hostname,当前传进来的args解析成了一个个的键值对,类似于里面保存了hashmap,类似于映射
//hostname的参数名叫做host
String hostname=parameterTool.get("host");
Integer port = parameterTool.getInt("port");
//2、读取文本流
DataStreamSource<String> lineDataStream = env.socketTextStream(hostname,port);
//3、转换数据格式,flatMap把它转换成二元组类型
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
})
//指定返回的元组类型,第一个元素师String,第二个元素是长整形
.returns(Types.TUPLE(Types.STRING, Types.LONG));
//4、分组(按照第一个元素word去做分组)
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
//5、求和(对第二个元素长整形的1求和计算)
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
//6、打印
sum.print();
//7、启动执行
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
上面也不一定不用参数的方法,去掉下面这三行
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hostname=parameterTool.get("host");
Integer port = parameterTool.getInt("port");
在读取文本流这里写上对应的端口号和主机地址就可以了,最终的结果都是一样的















 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









