







1、关闭flink集群(bin/stop-cluster.sh)stop-cluster.sh
2、开启hadoop分布式集群,包括hfds和yarn,以及分布式集群new-ha2和new-ha3
3、在xshell的new-ha2集群的flink目录下输入在yarn上开启flink集群的指令

开启成功后显示如下图所示,在浏览器输入出现的网址new-ha1:45888进去flink集群
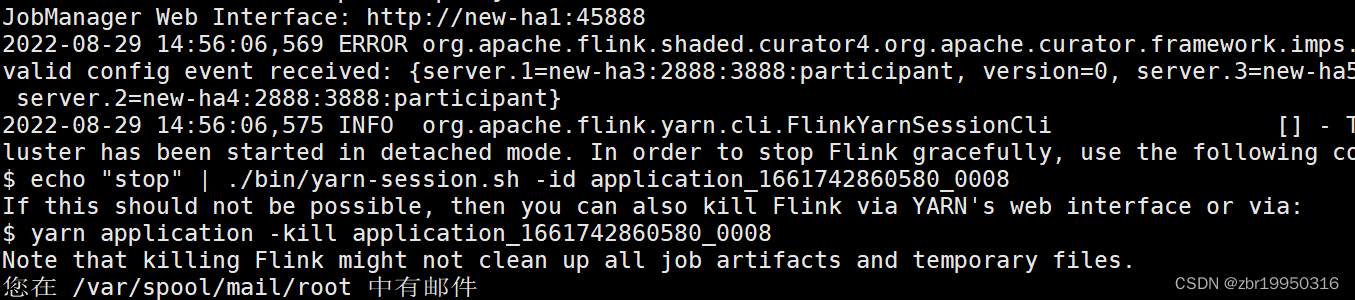
浏览器进入后, 在new-ha2输入提交作业的指令
bin/flink run -c com.atguigu.wc.StreamWordCount apps/FlinkTutorial-1.0-SNAPSHOT.jar -port 7777 -host new-ha1
输入结束后,回车键,查看flink集群的Running jobs如下图

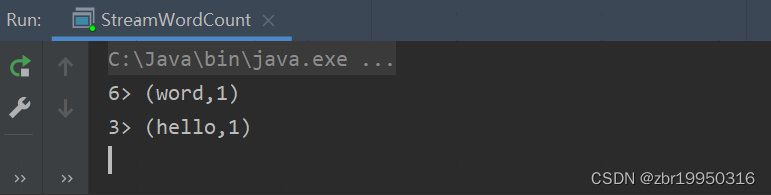
此时在new-ha1集群数入一些数据,比如hello world

此时flink的idea开发环境就会显示
在WEB UI的可视化界面TaskMannger 也能看到

点进去 后会出现
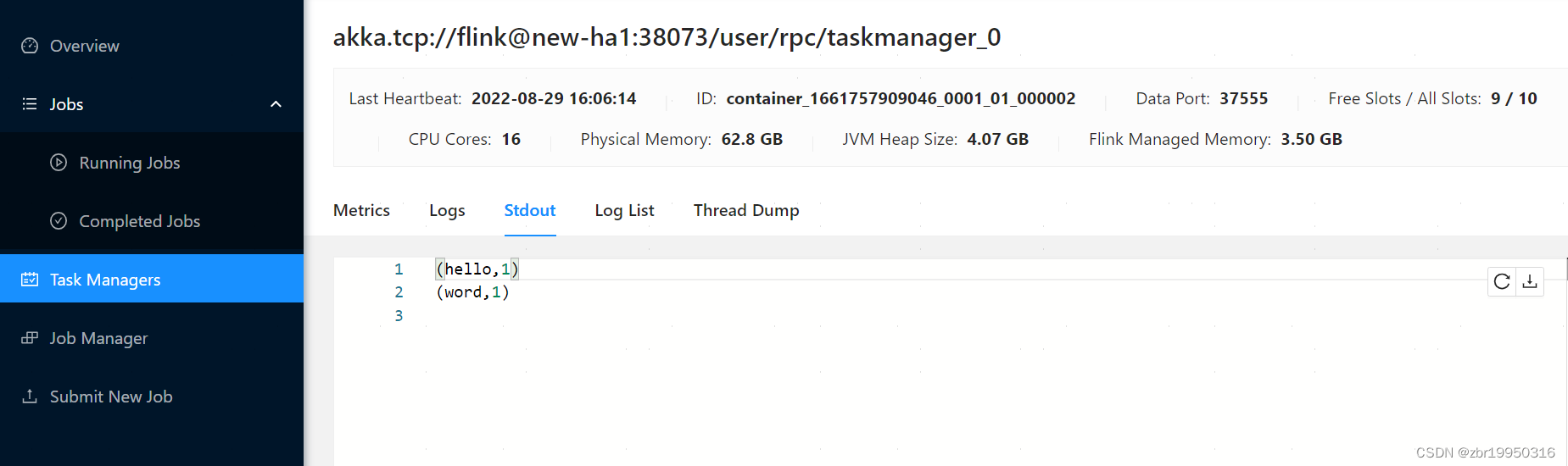
此时在new-ha2集群ctrl c也没有关系,因为此时提交作业的过程和客户端已经没有关系了,已经提交上去之后,running JOBs肯定是可以运行的
这就是flink集群在yarn上开启并提交作业的过程















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









