







线程指令
通常,顶点着色器程序计算(x, y, z, w)位置向量,而像素着色器程序计算(red, green, blue, alpha)颜色向量。然而,随着着色器程序变得越来越长且基于标量指令,即使是传统GPU中四组件向量架构的两个组件也难以充分利用。实际上,SIMT架构是在32个独立像素线程上进行并行处理,而不是在一个像素内部对四个向量组件进行并行处理。CUDA C/C++程序主要为每个线程使用标量代码。之前的GPU采用了向量打包(例如,组合工作子向量以提高效率),但这不仅增加了调度硬件的复杂性,还加大了编译器的难度。标量指令更为简单且对编译器友好。纹理指令则保持基于向量,接受源坐标向量并返回过滤后的颜色向量。
为了支持具有不同二进制微指令格式的多款GPU,高级图形和计算语言编译器生成中间汇编级别的指令(例如Direct3D向量指令或PTX标量指令),然后将这些指令优化并转换为GPU的二进制微指令。NVIDIA PTX(并行线程执行)指令集定义[2007]为编译器提供了一个稳定的ISA目标,并在多个GPU世代中提供了与演变中的二进制微指令集架构的兼容性。优化器能够轻易地将Direct3D向量指令扩展为多个标量二进制微指令。PTX标量指令几乎可以一对一地转换为标量二进制微指令,尽管某些PTX指令会扩展为多个二进制微指令,而多个PTX指令有时可以合并成一个二进制微指令。由于中间汇编级别指令使用虚拟寄存器,优化器能分析数据依赖关系并分配实际寄存器。优化器可以消除无用代码,在可行的情况下合并指令,并优化SIMT分支发散点和收敛点。
[1]NVIDIA [2007]. CUDA Programming Guide 1.1 . https://developer.nvidia.com/nvidia-gpu-programmingguide .
[2]NVIDIA [2007]. PTX: Parallel Th read Execution ISA version 1.1 . www.nvidia.com/object/io_1195170102263.
html .
指令集架构(ISA)
这里描述的线程指令集体系结构(ISA)是一个简化的版本,基于Tesla架构PTX ISA,该ISA采用基于寄存器的标量指令集,包含了浮点数、整数、逻辑、转换、特殊函数、流程控制、内存访问以及纹理操作等指令。图B.4.3列出了基本的PTX GPU线程指令;详细信息请参阅NVIDIA PTX规范[2007]。PTX指令的格式如下:
opcode.type d, a, b, c;
其中d是目的操作数;a、b、c是源操作数,而.type是下表其中之一:
| type | .type标识符 |
|---|---|
| Untyped bits 8, 16, 32, and 64 bits | .b8, .b16, .b32, .b64 |
| Unsigned integer 8, 16, 32, and 64 bits | .u8, .u16, .u32, .u64 |
| Signed integer 8, 16, 32, and 64 bits | .s8, .s16, .s32, .s64 |
| Floating-point 16, 32, and 64 bits | .f16, .f32, .f64 |
源操作数是寄存器中的32位或64位标量值,也可以是立即数或常量;谓词操作数为1位布尔值。目标通常是寄存器,除了存储到内存的指令。通过在指令前缀添加@p或@!p(其中p是一个谓词寄存器)来对指令进行条件化预判执行。内存和纹理指令可以传输单个标量或最多四个组件的向量,总数据宽度可达128位。PTX指令定义了一个线程的行为。
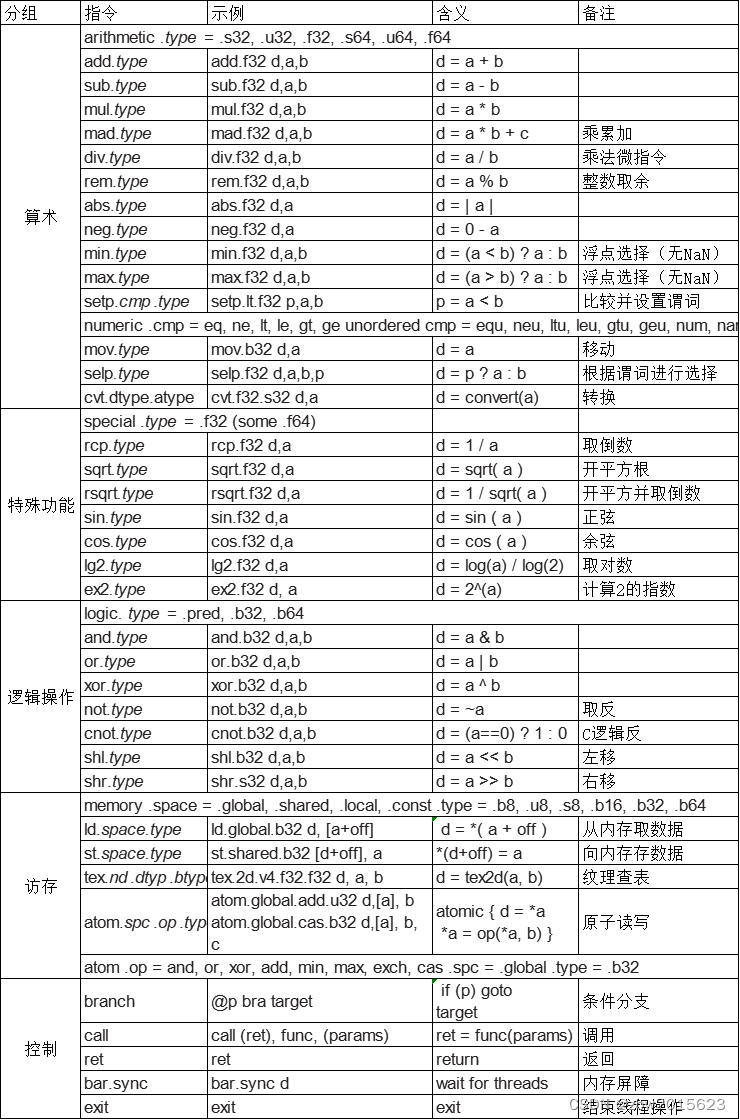
PTX算术指令支持对32位和64位浮点数、有符号整数和无符号整数类型的操作。最近的GPU支持64位双精度浮点数计算,具体参见B.6节内容。在当前的GPU上,PTX 64位整数和逻辑指令会被转换成执行32位操作的两个或多个二进制微指令。GPU特殊函数指令目前仅限于32位浮点数运算。
线程控制流程指令包括条件分支branch、函数调用call和返回return、线程退出exit以及bar.sync(屏障同步)。条件分支指令@p bra target使用先前由比较并设置谓词指令setp设置的谓词寄存器p(或!p)来决定线程是否执行分支跳转。其他指令也可以基于一个谓词寄存器的真或假值来进行条件执行。
访存指令
在CUDA编程和GPU计算中,tex指令通过纹理子系统从内存中的1D、2D和3D纹理数组获取并过滤纹理样本。纹理取样通常使用插值浮点坐标来寻址纹理。一旦图形像素着色器线程计算出其像素片段的颜色,光栅操作处理器(ROP)就会将该颜色与分配给(x, y)像素位置的像素颜色进行混合,并将最终颜色写入内存。
为了支持计算需求以及C/C++语言编程,Tesla PTX指令集架构实现了内存加载/存储指令。它采用整数字节寻址方式,配合寄存器加偏移量地址算术,以便于传统的编译器代码优化。虽然内存加载/存储指令在处理器中很常见,但在Tesla架构的GPU中,这是一项重要的新功能,因为之前的GPU仅提供了满足图形API所需的纹理和像素访问能力。
对于计算而言,加载/存储指令可以访问三个读写内存空间,这些空间对应于CUDA编程模型中的相应内存区域:
- 本地内存(Local memory):用于每个线程私有的临时可寻址数据(实现于外部DRAM中)
- 共享内存(Shared memory):为同一CTA(并发线程数组)或线程块内的协作线程提供低延迟访问共享数据的方式(实现于芯片上的SRAM上)
- 全局内存(Global memory):用于所有线程共享的大规模数据集(实现于外部DRAM中)
对应的内存加载/存储指令包括ld.global、st.global(访问全局内存)、ld.shared、st.shared(访问共享内存)以及ld.local、st.local(访问本地内存)。
计算程序利用快速屏障同步指令bar.sync来同步同一个CTA/线程块内通过共享内存和全局内存进行通信的线程。
进行线程间通信的屏障同步指令
在CUDA程序中,快速屏障同步允许通过简单调用__syncthreads();函数频繁地利用共享内存和全局内存进行线程间通信。这一同步内建函数生成一个单一的bar.sync指令。然而,在每个CUDA线程块中实现多达512个线程之间的快速屏障同步是一个挑战。
将线程组织成包含32个线程的SIMT线程束可以将同步难度降低32倍。当线程在SIMT线程调度器处等待屏障时,它们不会消耗任何处理器周期。当一个线程执行bar.sync指令时,它会增加屏障的到达线程计数器,并且调度器将该线程标记为正在等待屏障。一旦所有CTA(并发线程数组)线程都到达,屏障计数器将与预期的终止计数值匹配,此时调度器就会释放所有在屏障处等待的线程,并恢复执行线程。这种设计极大地提高了并行计算中的同步效率,确保了多线程间的协同工作。
流处理器
多线程流处理器(SP)核心是多处理器中的主要线程指令处理单元。其寄存器文件(RF)为最多64个线程提供了1024个标量32位寄存器。它执行所有基本的浮点运算,包括add.f32(浮点加法)、mul.f32(浮点乘法)、mad.f32(浮点乘加)、min.f32(浮点最小值选取)、max.f32(浮点最大值选取)和setp.f32(浮点比较并设置条件码)。这些浮点加法和乘法操作与IEEE 754标准兼容,支持单精度FP数,包括非数值(NaN)和无穷大。
SP核心还实现了图B.4.3所示的所有32位和64位整数算术、比较、转换以及逻辑PTX指令。
浮点加法和乘法操作默认采用IEEE近似到最近偶数的舍入模式。mad.f32浮点乘加操作首先进行截断后的乘法,然后进行近似到最近偶数的加法。SP会将输入的小数非规范操作数(denormal operands)截断至符号保留的零。如果结果在目标输出指数范围下溢,则在舍入后将其截断至符号保留的零。
特殊功能单元
某些线程指令可以在SFU(特殊功能单元)上执行,与在SPs(流处理器)上执行的其他线程指令并行进行。SFU实现了图B.4.3中所示的特殊函数指令,用于计算32位浮点数近似的倒数、平方根倒数以及一些基本超越函数。此外,它还为像素着色器提供了32位浮点数平面属性插值的功能,可以准确地插值诸如颜色、深度和纹理坐标等属性。
每个流水线式的SFU每周期能够生成一个32位浮点数特殊函数结果;每个多处理器中的两个SFU以8个SPs简单指令速率的四分之一执行特殊函数指令。同时,SFU还能与八个SPs并发执行mul.f32乘法指令,在合适的指令混合情况下,将峰值计算率提高到50%。
对于函数评估,Tesla架构下的SFU采用基于增强型最小最大逼近方法的二次插值来近似计算倒数、平方根倒数、log2x、2x和sin/cos函数。这些函数估算的精度范围在22至24位尾数位之间。关于SFU算术运算的更多详细信息,请参阅B.6节内容。
与其他多处理器的比较
相较于如x86 SSE这样的SIMD向量架构,SIMT(单指令多线程)多处理器能够独立执行单个线程,而不必始终以同步组的方式一起执行。在SIMT硬件中,即使在多个独立线程存在数据并行性时,硬件也能自行发现并利用这种并行性;而在SIMD硬件中,则需要软件开发者在每个向量指令中显式地表达数据并行性。
当32个线程沿着相同的执行路径前进时,SIMT机器会同步执行这些线程的一个“线程束”(warp),而在线程分歧时则能独立执行每一个线程。这种优势显著,因为SIMT程序和指令仅需描述单个独立线程的行为,而不是一个包含四个或更多数据元素的SIMD数据向量。然而,SIMT多处理器具有类似SIMD的高效性,将一条指令单元的面积和成本分散到一个线程束中的32个线程以及八个流处理器核心上。
SIMT技术结合了SIMD的性能优势与多线程编程的高生产力,避免了为边缘条件和部分分歧场景显式编写SIMD向量指令的需求。SIMT多处理器通过硬件多线程和硬件屏障同步机制实现了较低的开销,使得图形着色器和CUDA线程能够轻松表达非常细粒度的并行性。相比于强制程序员使用SIMD向量指令表达并行性,图形和CUDA程序使用线程在每个线程的程序中表示细粒度的数据并行性更为简单且生产效率更高。
将八个流处理器核心紧密耦合成一个多处理器,并进一步实现一定数量这样的多处理器,形成了由多处理器组成的两级多处理器结构。CUDA编程模型充分利用了这一双层层次结构,提供单个线程用于表达细粒度并行计算,并提供网格状的线程块来处理粗粒度并行操作。同一个线程程序可以同时提供细粒度和粗粒度的操作。相比之下,带有SIMD向量指令的CPU为了实现细粒度和粗粒度操作,通常需要采用两种不同的编程模型:不同核心上的粗粒度并行线程,以及针对细粒度数据并行性的SIMD向量指令。
总结
基于Tesla架构的示例GPU多处理器高度支持多线程,能够同时执行多达512个轻量级线程,以适应像素着色器和CUDA线程的细粒度处理需求。它采用了一种名为SIMT(Single Instruction Multiple Thread)的SIMD(单指令多数据流)架构与多线程技术的变体,能够在向32个并行线程组(称为一个线程束)广播一条指令的同时,允许每个线程独立分支和执行。
每个线程在其指令流上在一个或多个流处理器(SP)核心上运行,这些SP核心最多可支持64个线程并发执行。
PTX ISA是一种基于寄存器的加载/存储标量指令集架构,用于描述单个线程的执行过程。由于PTX指令会被优化并转换为特定GPU的二进制微指令,因此硬件指令可以快速演进,而不会影响生成PTX指令的编译器和软件工具的工作流程,从而保持了软硬件开发的灵活性与稳定性。














 3017
3017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









