






前言
随着电信基础设施的发展,电信诈骗威胁日益严峻。据相关数据,中国电信诈骗案件金额已超两万亿,76%网民曾受其困扰。新技术催生智能化、跨境犯罪化的诈骗手法,成本低且难察觉。现有的防范手段如检测手机号及机器学习模型存在局限,且目前并没有较全面的中文数据集来进行研究。
在本文中,我们通过选取CCL2023电信网络诈骗数据集中部分类别数据以及收集到的一些数据组成了一个涵盖冒充客服、冒充领导熟人、贷款、公检法诈骗和正常文本的中文5分类数据集。
一、电信诈骗是什么?
电信诈骗是指不法分子通过电话、短信、网络等电信手段,编造虚假信息,诱导受害人转账或泄露个人敏感信息(如银行卡号、验证码等)的诈骗行为。常见的手法包括冒充公检法、冒充熟人、虚假中奖、贷款诈骗、刷单诈骗等。其目的是非法获取钱财,给受害人造成财产损失。
二、数据集问题
1.数据稀缺性:
电信诈骗案件涉及隐私和安全,导致真实数据难以获取,数据规模小,且类别分布不均衡。
2.标注困难:
电信诈骗数据通常需要人工标注,但由于诈骗手法多变且复杂,标注耗时耗力,且难以保证一致性。
3.样本不平衡:
真实环境中,正常通信数据远多于诈骗数据,导致负样本多、正样本少,容易引发模型偏差。
4.动态变化性:
电信诈骗手段不断更新,已有数据难以覆盖新型诈骗形式,导致模型泛化能力受限。
三、五分类数据集
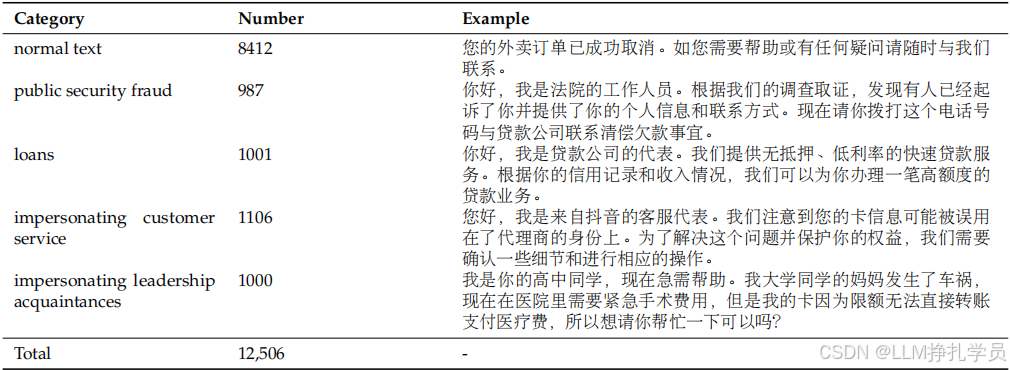
该数据集已在论文中发表,如有需要可以引用:Li, J.; Zhang, C.; Jiang, L. Innovative Telecom Fraud Detection: A New Dataset and an Advanced Model with RoBERTa and Dual Loss Functions. Appl. Sci. 2024, 14, 11628. https://doi.org/10.3390/app142411628
github链接:https://github.com/ChangMianRen/Telecom_Fraud_Texts_5
总结
我们自己做了一个五分类数据集,供大家研究使用,如有需要请注明。禁止商业用途


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









