




 本文探讨GeoMesa如何利用空间Z曲线和GeoHash算法建立高效时空索引,及在HBase上的查询流程。GeoMesa通过Z曲线将多维数据降维,设计RowKey以快速定位数据。查询时,通过启发式策略选择最优索引,构建Scan并行执行,提高查询效率。
本文探讨GeoMesa如何利用空间Z曲线和GeoHash算法建立高效时空索引,及在HBase上的查询流程。GeoMesa通过Z曲线将多维数据降维,设计RowKey以快速定位数据。查询时,通过启发式策略选择最优索引,构建Scan并行执行,提高查询效率。
在项目中使用GeoMesa作为时空索引数据库,打算了解下这个组件如何做到索引数据,又是如何做到数据查询的。本文主要是了解GeoMesa的索引原理(空间Z曲线和GeoHash算法)以及GeoMesa-HBase查询流程。
空间Z曲线与GeoHash算法:
下图中充满空间的Z形状的曲线就叫Z曲线,又叫peano曲线:
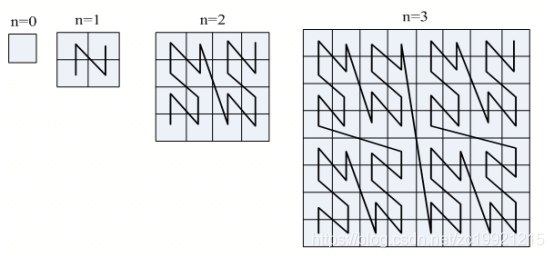
GeoHash算法就是对这些曲线进行编码:
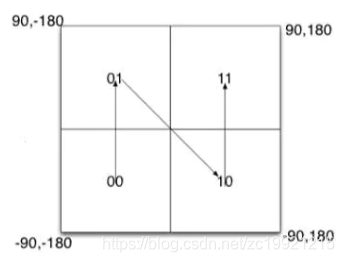
对这个大区间按左右进行划分,左边表示0,右边表示1,再按上下进行划分,下边为0,下边为1,这样就可以用序号表示一块空间。字符串越长,表示的范围越小,空间位置越精确,字符串越短,表示的范围越大越宽泛,字符串越相似表示距离空间越近(跳变情况下不是)。这样就可以将经纬度降维成一维字符串,如果再加上时间,就是将时空三维信息使用一维表示。
当空间形状不是点而是线之类的集合形状时,使用XZ-Ordering曲线表示时空信息,原理和上面类似。
索引信息在HBase中如何表示:
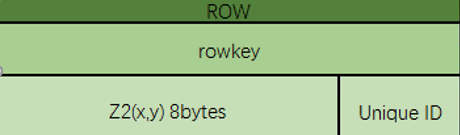
GeoMesa HBase构建索引主要是将空间和时间、属性等信息组织在rowkey中。以空间点数据为例,根据Z曲线降维之后的RowKey设计如下:
ShardKey(1 byte)+Z2(x,y)(2 bytes)+FeatureID
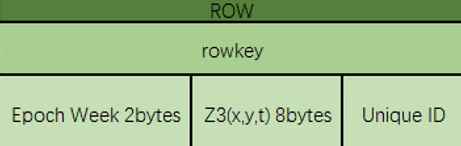
以时空点数据为例,RowKey设计如下:
ShardKey(1 byte)+Epoch Week(2 bytes)+Z3(x,y,t)(8 bytes)+FeatureID
所以GeoMesa有个蛋疼的地方,因为它的索引是通过RowKey展示的,所以每建一种索引就要将全量数据完全拷贝一份,数据量多时非常磁盘资源!但是它比ElasticSearch确实提供了丰富的多的空间功能,而且性能也表现得不错。
GeoMeas-HBase查询时,底层是如何进行的:
高并发查询的过程中发现HBase RegionServer的CPU占用率会特别高(现在想想当时使用ElasticSearch高并发的时候也很高,当时40个核的服务器ES能用掉28个...)
GeoMesa-HBase查询数据,主要是解析查询的CQL语句,采用启发式策略估算从哪个索引表中获取数据最快(真正执行查询时只会查询一个索引表--此时这张表称为主索引)。内部主要是解析CQL语句,确定查询语句内部包含那些检索(空间检索,时空检索等等),每一种索引都会对应一个常量值,根据这些常量值做计算,选择耗时最少的索引作为主要查询的索引(之前的文章说过,一种索引会对应一张数据库表,选择索引也就选择了要查询的数据库表)。
确定要查询的表之后,接着就是构建对应的迭代器获取数据。这部分代码在QueryPlan.scala类中的createPlan()中,内部会根据查询条件,将对应需要获取的RowKey构造成多个Scan:
这些Scan是会将用户输入的空间范围按照上面介绍的进行讲一个矩形不断的划分成4个小格子,如果划分后的小格子是完全包含在用户输入的空间范围内,则这个小格子就是一个Scan,否则还要继续划分,直到划分到一定的空间精度为止。不能完全包含的,那就是相交关系。并且 这些Scan会按照rowKey的min,max进行排序:

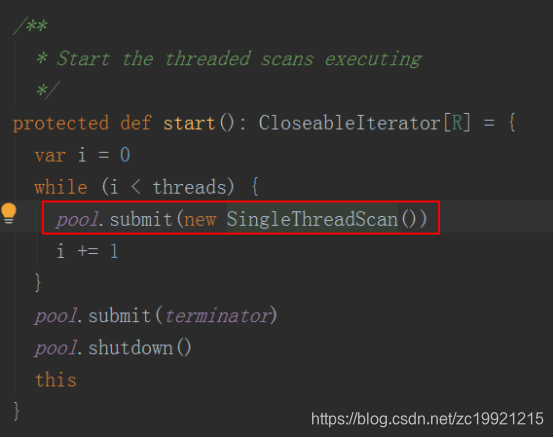
将多个Scan扔到线程池并发执行,所以一个CQL语句执行的时候,才会那么的耗费内存以及CPU!:
参考:
https://malagis.com/spatial-databases-26-z-ordering-curve.html(Gis空间数据库)
https://www.jianshu.com/p/9a13825edbda(GeoMesa索引机制)
https://blog.csdn.net/weixin_41834634/article/details/89203552(GeoMesa RowKey设计)

















 822
822

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









