








一、什么是数组
数组,从字面上看,就是一组数据的意思,没错,数组就是用来存储一组数据的。在iOS开发中,数组是非常重要且常用的集合,所以学好数组是非常有必要的。
二、数组的分类
按存储的内容分类
数值数组:用来存储数值得
字符数组:用来存储字符 ‘a’
指针数组:用来存放指针(地址)的
结构数组:用来存放一个结构体类型的数据
按维度分类
一维数组
二维数组
多维数组
作为iOS开发,掌握一维数组就可以了。
三、数组的定义、初始化、使用
1、初始化数组
一般会在数组定义的同时进行初始化。
其中在{ }中的各数据值即为各元素的初值,各值之间用逗号间隔
int ages[3] = {4, 6, 9};
指定数组的元素个数,对数组进行部分显式初始化
定义的同时对数组进行初始化,没有显式初始化的元素,那么系统会自动将其初始化为0
int nums[10] = {1,2};
不指定元素个数,定义的同时初始化,它是根据大括号中的元素的个数来确定数组的元素 个数
int nums[] = {1,2,3,5,6};
指定元素个数,同时给指定元素进行初始化
int nums[5] = {[4] = 3,[1] = 2};
先定义,后初始化
int nums[3];
nums[0] = 1;
nums[1] = 2;
nums[2] = 3;
2、数组的使用
通过下标(索引)访问:
ages[0]=10;
int a = ages[2];
printf(“a = %d”, a);
3、数组注意事项
(1)在定义数组的时候[]里面只能写整型常量或者是返回整型常量的表达式.
(2)错误写法
// 没有指定元素个数,错误
int a[];
(3)[]中不能放变量
int number = 10;
int ages7[number]; // 不报错, 但是没有初始化, 里面是随机值
printf(“%d\n”, ages7[4]);
int number = 10;
int ages7[number] = {19, 22, 33} // 直接报错
int ages8[5];
// 只能在定义数组的时候进行一次性(全部赋值)的初始化
int ages10[5];
ages10 = {19, 22, 33};
// 一个长度为n的数组,最大下标为n-1, 下标范围:0~n-1
int ages11[4] = {19, 22, 33}
ages[8]; // 数组角标越界
4、数组的遍历
数组的遍历:遍历的意思就是有序地查看数组的每一个元素。
示例 1:
int ages[4] = {19, 22, 33, 13};
for (int i = 0; i < 4; i++) {
printf(“ages[%d] = %d\n”, i, ages[i]);
}
实例2:
int main(int argc, const char * argv[])
{
int age[] = {1,3,3,5,3};
for (int i = 0; i < sizeof(age)/sizeof(age[1]); i++)
{
printf(“age[%i]=%i\n”,i,age[i]);
}
5、数组内部存储细节
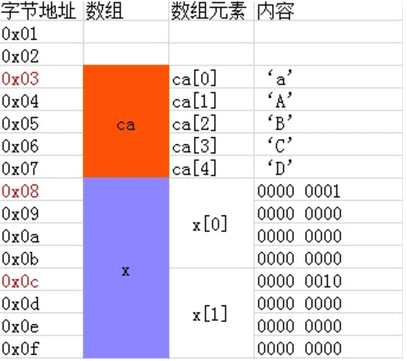
作为程序员内存是最为关注的,下面来搞搞数组内部的存储机制。
存储方式:
(1)计算机会给数组分配一块连续的存储空间
(2)数组名代表数组的首地址,从首地址位置,依次存入数组的第1个、第2个….、第n个元素
(3)每个元素占用相同的字节数(取决于数组类型)
(4)并且数组中元素之间的地址是连续。
模拟数组的存储如下图:
6、数组元素作为函数参数
数组可以作为函数的参数使用,进行数据传送。数组用作函数参数有两种形式:
一种是把数组元素(下标变量)作为实参使用。
数组元素就是下标变量,它与普通变量并无区别。 因此它作为函数实参使用与普通变量是完全相 同的,在发生函数调用时,把作为实参的数组元素的值传送给形参,实现单向的值传送。
一种是把数组名作为函数的形参和实参使用。
7、数组名作函数参数的注意点
(1)在函数形参表中,允许不给出形参数组的长度
void change2(int array[])
{
array[0] = 88;
}
(2)形参数组和实参数组的类型必须一致,否则将引起错误。
//
void prtArray(double array[3]) // 错误写法
{
for (int i = 0; i < 3; i++) {
printf("array[%d], %f", i, array[i]);
}
}
int main(int argc, const char * argv[])
{
int ages[3] = {1, 5, 8};
prtArray(ages[0]);
}
(3)当数组名作为函数参数时, 因为自动转换为了指针类型,所以在函数中无法动态计算除数组的元素个数
// //
void printArray(int array[])
{
printf("printArray size = %lu\n", sizeof(array)); // 8
int length = sizeof(array)/ sizeof(int); // 2
printf("length = %d", length);
}
四、选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元 素,然后放到排序序列末尾。以此类推,直到所有元素均排序完毕。
选择排序的基本思想
第一趟排序在所有待排序的n个记录中选出关键字最小的记录,将它与数据表中的第一个记录交换位置,使关键字最小的记录处于数据表的最前端;第二趟在剩下的n-1个记录中再选出关键字最小的记录,将其与数据表中的第二个记录交换位置,使关键字次小的记录处于数据表的第二个位置;重复这样的操作,依次选出数据表中关键字第三小、第四小…的元素,将它们分别换到数据表的第三、第四…个位置上。排序共进行n-1趟,最终可实现数据表的升序排列。
五、冒泡排序
冒泡排序(Bubble Sort,台湾译为:泡沫排序或气泡排序)是一种简单的排序算法。它重复 地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来 是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
冒泡排序 分为: 大数下沉 小数上浮
冒泡排序的基本思想:
(1)比较相邻的元素。如果第一个比第二个大,就交换他们两个。
(2)对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应 该会是最大的数。
(3)针对所有的元素重复以上的步骤,除了最后一个。
(4)持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
六、折半查找
在有序表中,取中间元素作为比较对象,若给定值与中间元素的要查找的数相等,则查找成功; 若给定值小于中间元素的要查找的数,则在中间元素的左半区继续查找;
若给定值大于中间元素的要查找的数,则在中间元素的右半区继续查找。不断重复上述查找过 程,直到查找成功,或所查找的区域无数据元素,查找失败。
折半查找的基本思想
在有序表中,取中间元素作为比较对象,若给定值与中间元素的要查找的数相等,则查找成功;
若给定值小于中间元素的要查找的数,则在中间元素的左半区继续查找;
若给定值大于中间元素的要查找的数,则在中间元素的右半区继续查找。
不断重复上述查找过 程,直到查找成功,或所查找的区域无数据元素,查找失败。
















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









