







在R-CNN模型中,候选区域生成后,需要归一化每个候选区域的尺寸,例如 使用Alexnet网络提取特征的话,需要先将候选区域图片归一化到到227 * 227,然后才能输入Alexnet网络提取特征。
SPPnet(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)的特点是接受任意大小候选区域,经过可变的池化后生成固定长度的特征。SPPnet可提升 24-102 倍R-CNN检测的速度。但是固定输入图像尺寸的话,会导致截取的区域未涵盖整个目标或者缩放带来图像的扭曲,会引起网络精度的下降。
事实上,CNN的卷积层不需要固定尺寸的图像,而需要固定尺寸输入的是全连接层,因此大牛提出了,将SPP层放到卷积层的后面,分割开卷基层和全连接层,将不固定尺寸的输出通过空间金字塔池化为固定输出。
R-CNN模型流程:
image -> Region image -> crop/warp -> conv layers -> fc layers -> output feature
R-CNN针对每一个候选区域,要卷积一次,所以一张图片,需要卷积2000+次;
image -> conv layers -> SPP ->Region image-> fc layers -> output feature
SPPnet针对每一张图片,才卷积一次。
R-CNN提取特征比较耗时,需要对每个缩放后的候选区域进行学习;而SPPNet只对图像进行一次特征提取,之后使用SPPNet在特征图上提取每个候选区域的特征。
SPP层详细解释:
假设我们输入一张任意大小的特征图,需要提取21个特征。
输入:图片 大小 W * H
输出:21个神经元
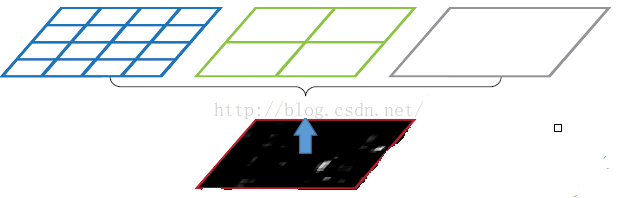
如图所示,当我们输入一张图片的时候,利用不同大小的刻度,对一张图片进行了划分。上图中,利用了三种不同大小的刻度,对一张输入的图片进行了划分,最后总共可以得到16+4+1=21个块,我们即将从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。
第一张图片,分成了16块,每个块大小 W/4,H/4;
第二张图片,分成了4块,每个块大小 W/2,H/2;
第三张图片,一个整块,块大小 W,H;
空间金字塔最大池化的过程:就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出神经元。最后把一张任意大小的图片转换成了一个固定大小的21维特征。上面的三种不同刻度的划分,每一种刻度我们称之为:金字塔的一层,每一个图片块大小我们称之为:window size。
有了SPP层提取固定长度的特征后,还需要将候选区域从原图映射到最后一个卷积层产生的feature图。
- 对任何一个候选区域,获取它的两个角点,左上角 和右下角,这两个角点就可以唯一确定候选区域的位置了。
- 事实上,原图经过一些列的卷积池化后,输出最后的特征图,原图上的像素点与最后的特征图的像素点是一一对应的。那么原图的候选区域就可以映射到特征图的唯一的一个特征图候选区域。















 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









