







faster RCNN可以简单地看做“区域生成网络 + fast RCNN“的系统,用区域生成网络RPN代替fast RCNN中的Selective Search方法产生候选区域。
区域生成网络(RPN):
RPN利用了SPP的映射机制,在最后一个卷积层上使用滑窗替代从原始图上滑窗。
在RPN网络中,使用固定尺寸变化、固定scale ratio变化、固定采样方式三个固定来降低使用滑窗的复杂度。
网络的结果,是卷积层的每一个点都有关于K个anchor boxes的输出,包括是否物体,调整box相应的位置,需要注意的是,这K个anchor boxes是在原始输入的图片上,而不是在feature map上。也就是说,网络给出了比较死的位置,大致判断是否有物体及物体的大概位置,至于细节,留给faster rcnn网络的后面微调部分来处理。
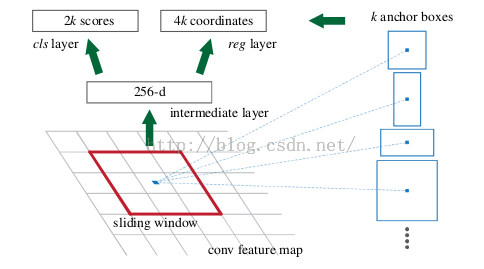
如上图所示,在这个特征图上使用 3*3 的卷积核(滑窗)进行卷积,卷积后可以获得一个 256 维的特征向量(因为在这个3*3的区域上,每一个特征图上得到一个1维向量,256个特性图即可得到256维特征向量)。
3*3 滑窗中心点位置,对应预测输入图像 3 种尺度(128, 256, 512),3种长宽比(1:1, 1:2, 2:1)的region proposal,这种映射的机制称为 anchor,产生了3 * 3 = 9 个 anchor。即每个 3*3 区域可以产生 9 个 region proposal。所以对于 51*39尺寸的feature map,总共有约18000(51*39*9)个anchor,也就是预测约18000个region proposal。
窗口分类及位置微调:
RPN网络后边接到两个全连接层,即 cls layer(分类) 和 reg layer (边框回归)
cls layer包含2个元素,用于判别目标和非目标的估计概率。
reg layer包含4个坐标元素(x,y,w,h),用于确定目标位置
最后根据 region proposal 得分高低,选取前300个region proposal,作为Fast R-CNN的输入进行目标检测。
















 3783
3783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









