







Faster RCNN是由 R-CNN、Fast R-CNN 改进而来,是非常经典的目标检测的两阶段网络。
此篇博客是我通过学习以下优秀博客归纳整理而得:
Faster R-CNN:详解目标检测的实现过程 - 郭耀华 - 博客园
yolov5与Faster-RCNN 训练过程正负样本和评价指标_norman_sen的博客-CSDN博客_yolov5正负样本
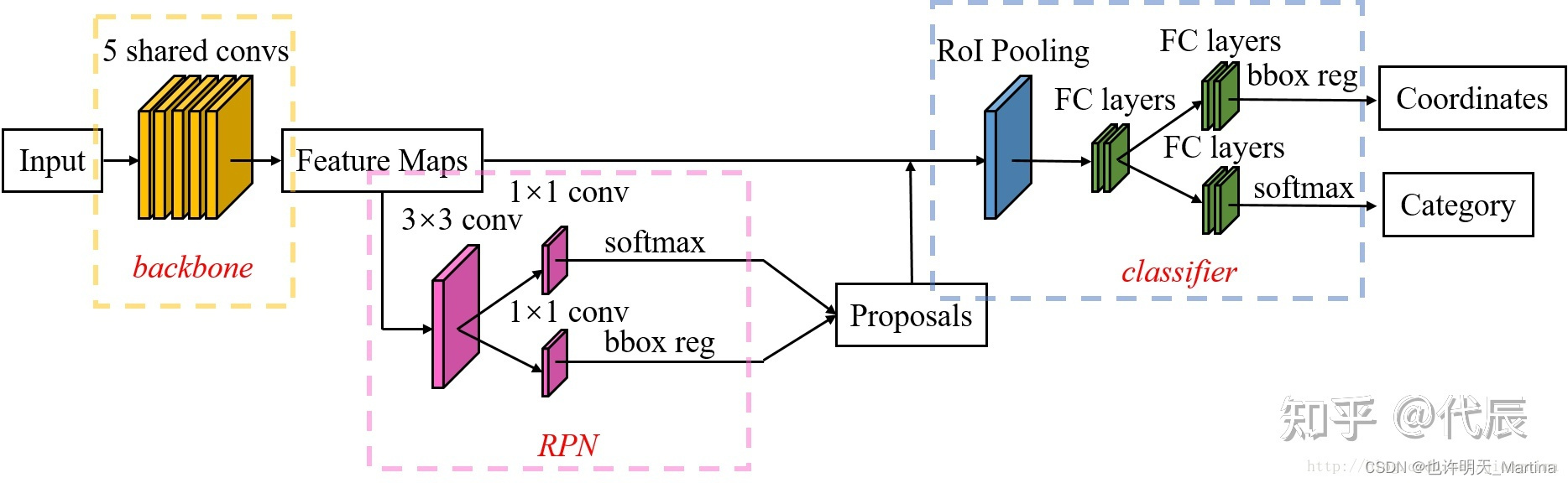
一、Faster R-CNN的整体结构
- 输入、数据预处理。首先,将尺寸大小为 M×N 的图片输入 Faster-RCNN 网络进行 resize 操作,处理图片的尺寸到 H×W,适应模型要求。
- Conv layers——backbone提取特征。Faster-RCNN 可以采用多种的主干特征提取网络,常用的有VGG,Resnet,Xception等等。作为一种CNN网络目标检测方法,Faster RCNN使用一组基础的 conv+relu+pooling 层提取 image的feature maps ,该 feature maps 被共享用于后续 RPN 层和全连接层。也就是使用共享的卷积层为全图提取特征。
- Region Proposal Networks。RPN网络用于生成 region proposals (目标候选区域)。将 RPN 生成的候选框投影到特征图上获得相应的特征矩阵。该层通过 softmax 判断 anchors (锚)属于前景或者背景,再利用 bounding box regression 修正 anchors 获得精确的 proposals 。
- RoI Pooling。该层收集输入的 feature maps 和 proposals,将每个特征矩阵缩放到 7×7 大小的特征图,综合这些信息后提取 proposal 和 feature maps,送入后续全连接层判定目标类别。
- Classifier。通过全连接层得到最后的概率,计算得到类别,同时再次 bounding box regression 获得检测框最终的精确位置。尤其注意的是,Faster R-CNN 真正实现了端到端的训练 (end-to-end training)。
Faster R-CNN整体结构图如下所示:
二、基础网络——backbone
Faster R-CNN 第一步要使用在图片分类任务 (例如,ImageNet) 上 预训练好的卷积神经网络,使用该网络得到的 中间层特征的输出 。
原始的 Faster R-CNN 使用的是在 ImageNet 上预训练的 ZF 和 VGG,但之后出现了很多不同的网络,且不同网络的参数数量变化很大。例如,MobileNet,以速度优先的一个小型的高效框架,大约有 330 万个参数,而 ResNet-152(152 层),曾经的 ImageNet 图片分类竞赛优胜者,大约有 6000 万个参数。最新的网络结构如 DenseNet,可以在提高准确度的同时缩减参数数量。
如今,ResNet 已经取代大多数 VGG 网络作为提取特征的基础框架。Faster-RCNN 的三位联合作者 (Kaiming He, Shaoqing Ren 和 Jian Sun) 也是论文「Deep Residual Learning for Image Recognition」的作者,这篇论文最初介绍了 ResNets 这一框架。
ResNet 对比 VGG 的优势在于它是一个更深层、大型的网络,因此有更大的容量去学习所需要的信息。这些结论在图片分类任务中可行,在目标探测的问题中也应该同样有效。ResNet 在使用残差连接和批归一化的方法后更加易于训练,这些方法在 VGG 发布的时候还没有出现。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7038
7038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









