







PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge。
下载地址为:
点击打开链接。
下载完之后解压,可以在VOCdevkit目录下的VOC2012中看到如下的文件:
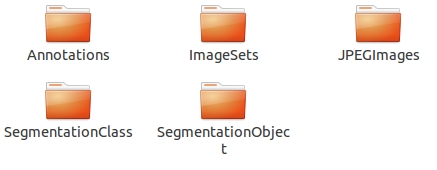
其中在图像物体识别上着重需要了解的是Annotations、ImageSets和JPEGImages。
①
JPEGImages
JPEGImages文件夹中包含了PASCAL VOC所提供的所有的图片信息,包括了训练图片和测试图片。
这些图像都是以“年份_编号.jpg”格式命名的。
图片的像素尺寸大小不一,但是横向图的尺寸大约在500*375左右,纵向图的尺寸大约在375*500左右,基本不会偏差超过100。(在之后的训练中,第一步就是将这些图片都resize到300*300或是500*500,所有原始图片不能离这个标准过远。)
这些图像就是用来进行训练和测试验证的图像数据。
②
Annotations
Annotations文件夹中存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。
xml文件的具体格式如下:
对应的图片为:

③
ImageSets
ImageSets存放的是每一种类型的challenge对应的图像数据。
在ImageSets下有四个文件夹:
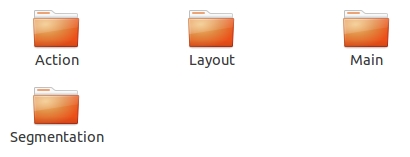
其中Action下存放的是人的动作(例如running、jumping等等,这也是VOC challenge的一部分)
Layout下存放的是具有人体部位的数据(人的head、hand、feet等等,这也是VOC challenge的一部分)
Main下存放的是图像物体识别的数据,总共分为20类。
Segmentation下存放的是可用于分割的数据。
在这里主要考察Main文件夹。
Main文件夹下包含了20个分类的***_train.txt、***_val.txt和***_trainval.txt。
需要保证的是train和val两者没有交集,也就是训练数据和验证数据不能有重复,在选取训练数据的时候 ,也应该是随机产生的。















 6129
6129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









