







文章目录
前言
在当今大数据时代,数据的获取与整理对于各个领域的研究和决策都具有至关重要的意义。图书领域也不例外,丰富且精准的图书数据能够为读者提供更优质的阅读推荐,助力图书行业从业者洞察市场趋势,还能为相关学术研究提供坚实的数据基础。
豆瓣作为国内知名的文化社区,汇聚了海量的图书信息,其分类体系清晰且涵盖面广,为我们采集图书数据提供了绝佳的数据源。本次项目聚焦于豆瓣图书数据,旨在构建一个全面、系统的图书数据集,以满足多方面对于图书信息分析的需求。
本项目将通过数据爬取技术,深入挖掘豆瓣图书分类标签页面以及各分类下的图书详细页面,采集关键信息,并运用合理的数据处理手段对采集到的数据进行清洗、整合,最终形成高质量的数据集。希望通过此次实践,不仅能为后续针对图书数据的分析与应用搭建良好的数据基石,也能为对数据采集与处理感兴趣的同行提供有价值的参考与借鉴,共同探索数据背后的无限可能,进一步推动图书相关领域在数据驱动下的创新发展。
一、数据爬取步骤
- 分析豆瓣图书分类标签页面
- 爬取豆瓣图书分类标签及地址
- 根据分类地址爬取每个分类的图书数据
- 每个分类的图书数据保存为一个CSV文件
- 整合所有的CSV文件为一个CSV文件
二、豆瓣图书页面分析
1. 图书分类标签页面分析
豆瓣图书分类标签地址:https://book.douban.com/tag/
豆瓣图书分类标签页面如下图所示:
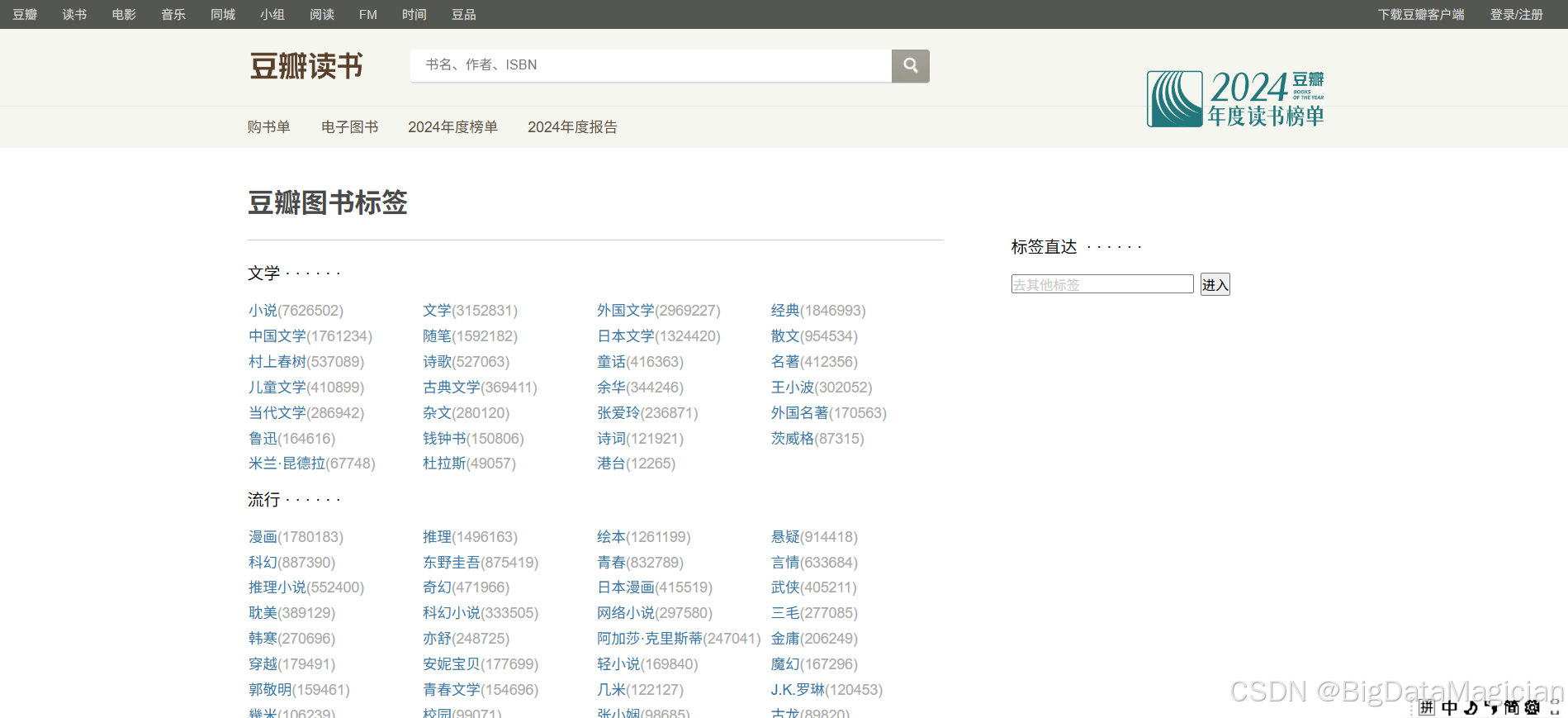
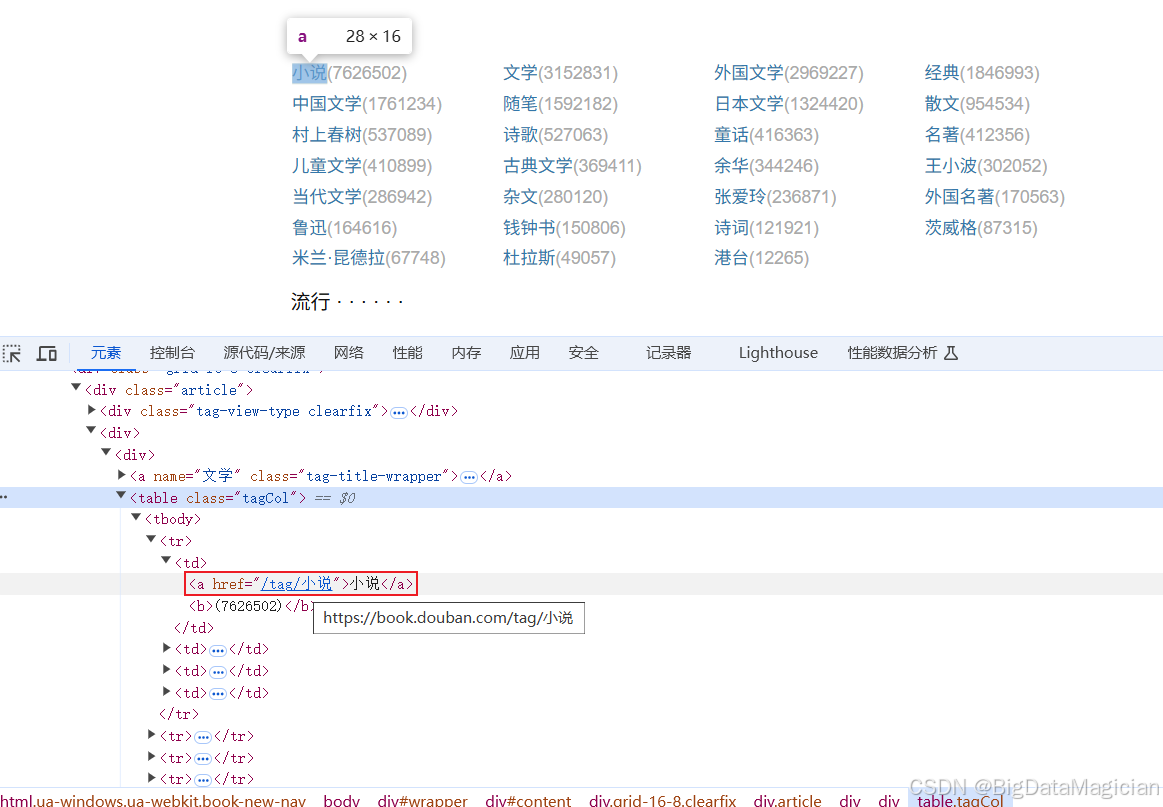
可以在每个<a>标签中获取分类标签连接和标签名,如下图所示:
2. 图书页面分析
进入分类之后,可以看到每个页面中有多个图书数据,包含图书图片、标题、作者、出版社、出版日期、价格、评分、评价人数、情节、纸质版价格这些字段,这些就是需要爬取的字段数据。
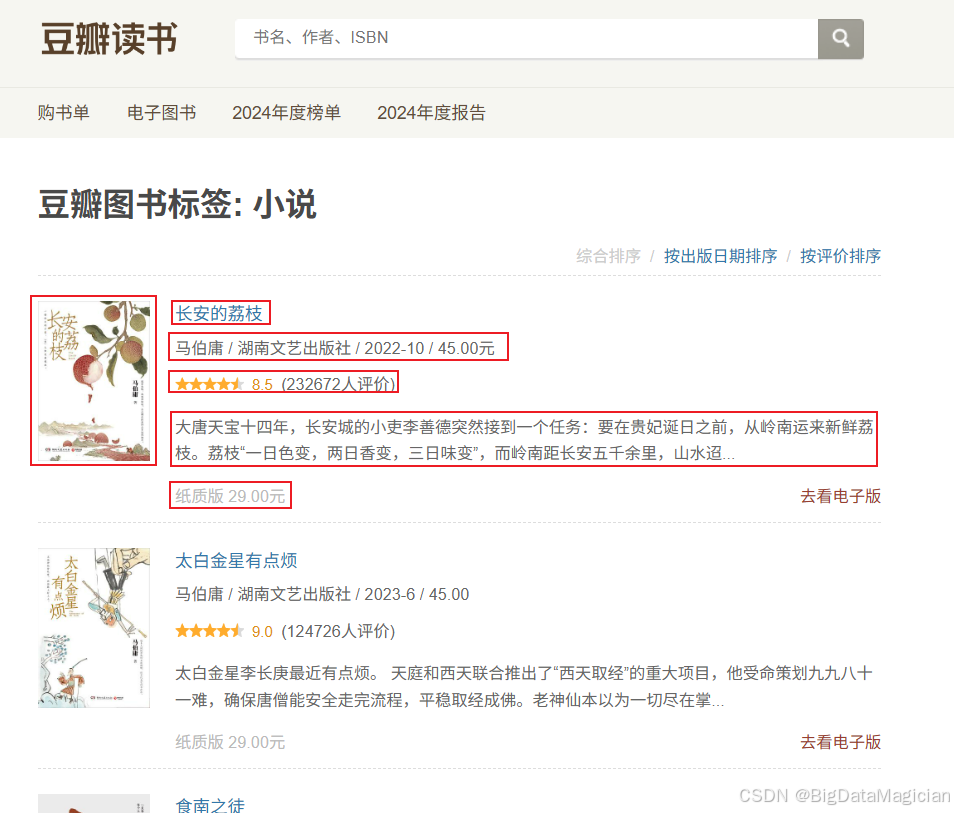
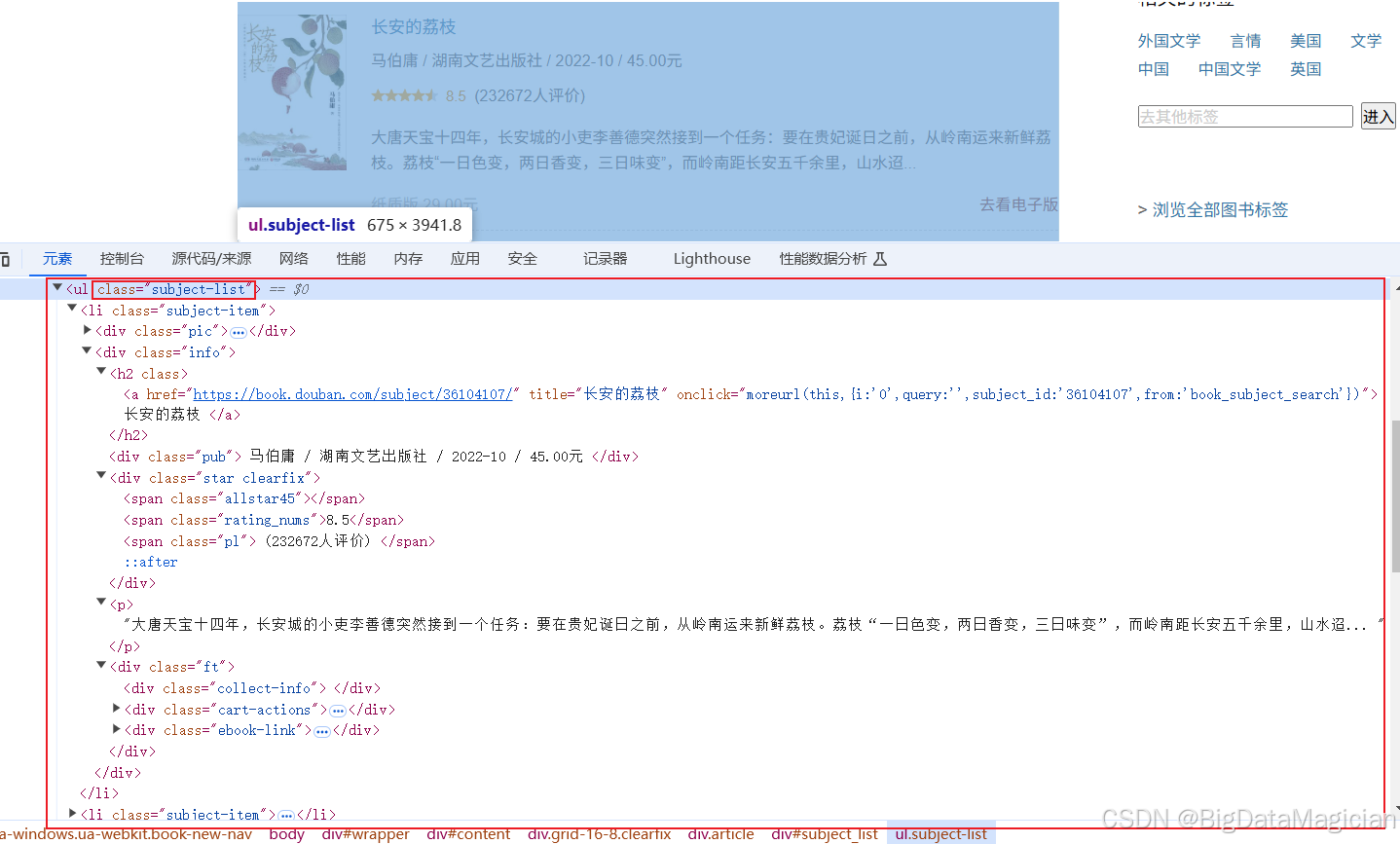
查看源码发现每项图书的数据在列表标签<ul class="subject-list">中,如下图所示:
在每个页面的最底部可以看到图书是分页显示的,如下图所示:
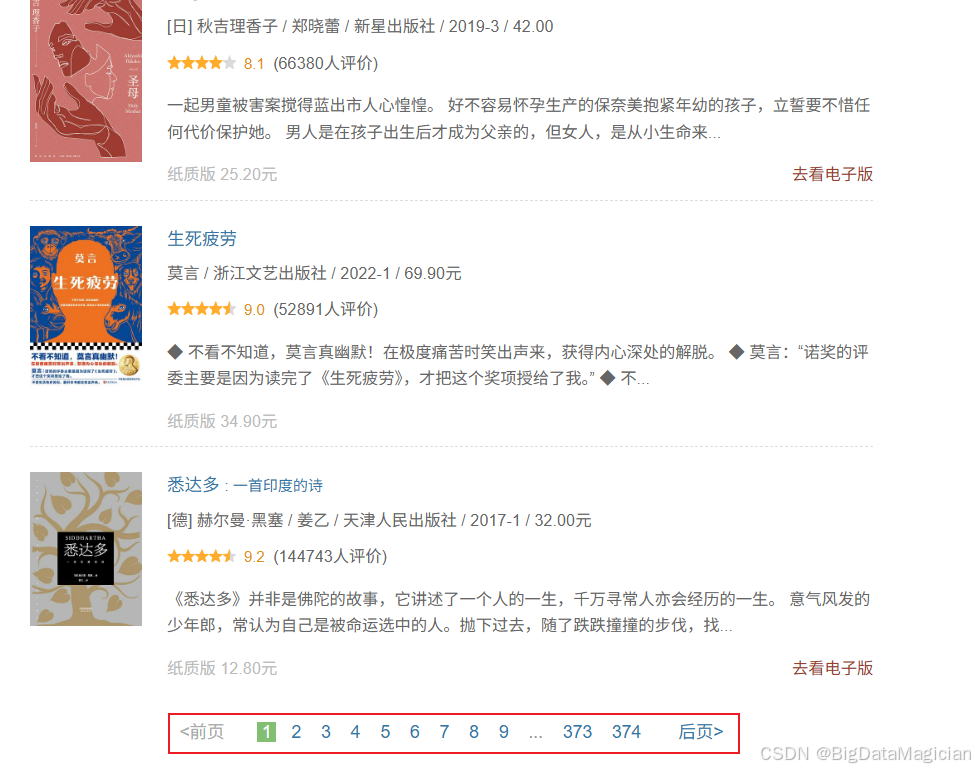
查看源码后可以看到每页的连接地址是有规律的,如下图所示:
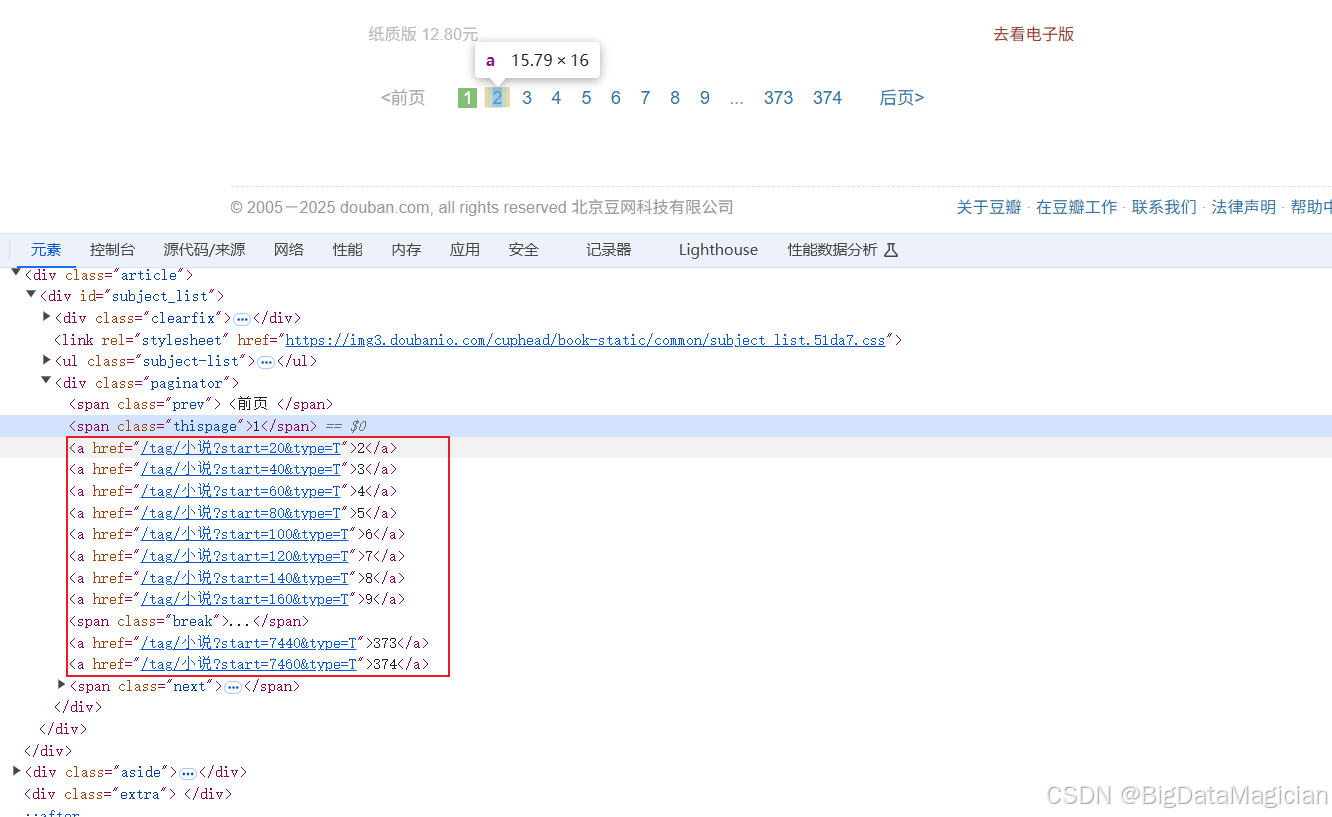
总结后得出地址构成为:
url = 'https://book.douban.com/tag/' + 图书分类标签 + '?start=' + 页数*20 + '&type=T'
三、数据采集实现
1. 图书分类标签数据采集
图书分类标签数据采集实现代码如下:
import pandas as pd
import requests
from bs4 import BeautifulSoup
def get_page_content(url):
"""
该函数用于获取指定URL页面的内容。
:param url: 要请求的页面的URL
:return: 页面的文本内容
"""
# 设置请求头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
}
try:
# 发送请求,设置超时时间为10秒
response = requests.get(url=url, timeout=10, headers=headers)
# 检查响应状态码,若不是200则抛出异常
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"请求出错: {e}")
return None
def parse_page_content(content):
"""
该函数用于解析页面内容,提取图书分类标签的名称和链接。
:param content: 页面的文本内容
:return: 包含图书分类标签信息的列表
"""
# 使用BeautifulSoup解析页面内容
soup = BeautifulSoup(content, 'lxml')
# 选择所有图书分类标签的链接
a_list = soup.select('.tagCol a')
data_list = []
for a in a_list:
# 获取标签名称
name = a.string
# 构建完整的链接
href = 'https://book.douban.com' + a.attrs.get('href')
print(name, href)
# 构建包含标签名称和链接的字典
data_dict = {'name': name, 'href': href}
data_list.append(data_dict)
return data_list
def save_to_csv(data_list, file_path):
"""
该函数用于将数据保存到CSV文件中。
:param data_list: 包含图书分类标签信息的列表
:param file_path: 要保存的CSV文件的路径
"""
# 将数据列表转换为DataFrame
df = pd.DataFrame(data_list)
# 将DataFrame保存为CSV文件,不保存行索引,使用utf-8-sig编码
df.to_csv(file_path, index=False, encoding='utf-8-sig')
def main():
"""
主函数,负责调用其他函数完成整个数据爬取和保存的流程。
"""
url = 'https://book.douban.com/tag/'
# 获取页面内容
content = get_page_content(url)
if content:
# 解析页面内容,提取数据
data_list = parse_page_content(content)
if data_list:
# 保存数据到CSV文件
save_to_csv(data_list, './原始数据层/图书分类标签.csv')
if __name__ == "__main__":
main()
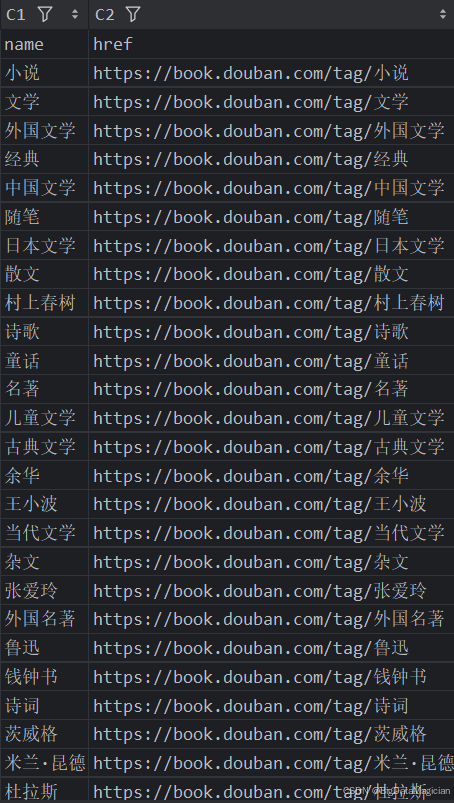
采集后的部分数据如下图所示:
2. 图书数据采集
图书数据采集代码实现如下:
import random
import time
from pathlib import Path
import pandas as pd
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
def get_element_text(element, css_selector):
"""
尝试查找元素并返回其文本内容,如果找不到则返回 None
:param element: 要查找元素的父元素
:param css_selector: CSS 选择器
:return: 元素的文本内容或 None
"""
try:
return element.find_element(By.CSS_SELECTOR, css_selector).text.strip()
except NoSuchElementException:
return None
def get_element_attribute(element, css_selector, attribute):
"""
尝试查找元素并返回其指定属性的值,如果找不到则返回 None
:param element: 要查找元素的父元素
:param css_selector: CSS 选择器
:param attribute: 要获取的属性名
:return: 元素的属性值或 None
"""
try:
return element.find_element(By.CSS_SELECTOR, css_selector).get_attribute(attribute)
except NoSuchElementException:
return None
def process_subject(subject, category_name):
"""
处理单个图书条目,提取相关信息
:param subject: 图书条目元素
:param category_name: 图书分类名称
:return: 包含图书信息的字典
"""
url = get_element_attribute(subject, '.pic > .nbg', 'href')
img_url = get_element_attribute(subject, '.pic > .nbg > img', 'src')
name = get_element_attribute(subject, '.info > h2 > a', 'title')
pub = get_element_text(subject, '.info > .pub')
rating = get_element_text(subject, '.info > .star > .rating_nums')
rating_count = get_element_text(subject, '.info > .star > .pl')
plot = get_element_text(subject, '.info > p')
buy_info = get_element_text(subject, '.info > .ft .buy-info > a')
data_dict = {
'category_name': category_name,
'url': url,
'img_url': img_url,
'name': name,
'pub': pub,
'rating': rating,
'rating_count': rating_count,
'plot': plot,
'buy_info': buy_info,
}
return data_dict
def process_category(driver, category_name, category_href):
"""
处理单个图书分类,遍历该分类下的所有页面并提取图书信息
:param driver: 浏览器驱动
:param category_name: 图书分类名称
:param category_href: 图书分类链接
"""
print(f"开始处理分类: {category_name},链接: {category_href}")
page = 0
while True:
file_dir = f'./原始数据层/图书分类数据集/'
file_name = f'{category_name}.csv'
file_path = Path(file_dir + file_name)
file_path.parent.mkdir(parents=True, exist_ok=True)
# 构建当前页面的 URL
url = category_href + f'?start={page * 20}&type=T'
print(f"正在访问页面: {url}")
driver.get(url)
time.sleep(random.uniform(1, 3))
try:
driver.find_element(By.CLASS_NAME, "subject-item")
except NoSuchElementException:
print(f"分类 {category_name} 页面加载完成,共处理 {page} 页")
break
# 等待所有图书条目元素加载完成
subject_list = WebDriverWait(driver, random.uniform(10, 20)).until(
EC.presence_of_all_elements_located((By.CLASS_NAME, "subject-item"))
)
data_list = []
for subject in subject_list:
data_dict = process_subject(subject, category_name)
data_list.append(data_dict)
page += 1
df1 = pd.DataFrame(data_list)
if file_path.exists():
df1.to_csv(file_path, mode='a', header=False, index=False)
else:
df1.to_csv(file_path, mode='w', header=True, index=False)
time.sleep(random.uniform(1, 3))
def main():
# 读取图书分类标签 CSV 文件
df = pd.read_csv('./原始数据层/图书分类标签.csv')
# 初始化浏览器驱动
driver = webdriver.Edge()
time.sleep(random.uniform(1, 3))
driver.get('https://book.douban.com/tag/小说')
time.sleep(60)
for _, category in df.iterrows():
category_name = category['name']
category_href = category['href']
file_dir = f'./原始数据层/图书分类数据集/'
file_name = f'{category_name}.csv'
file_path = Path(file_dir + file_name)
file_path.parent.mkdir(parents=True, exist_ok=True)
if file_path.exists():
print(f"文件已存在,跳过:{file_dir + file_name}")
continue
process_category(driver, category_name, category_href)
# 关闭浏览器驱动
driver.quit()
if __name__ == '__main__':
main()
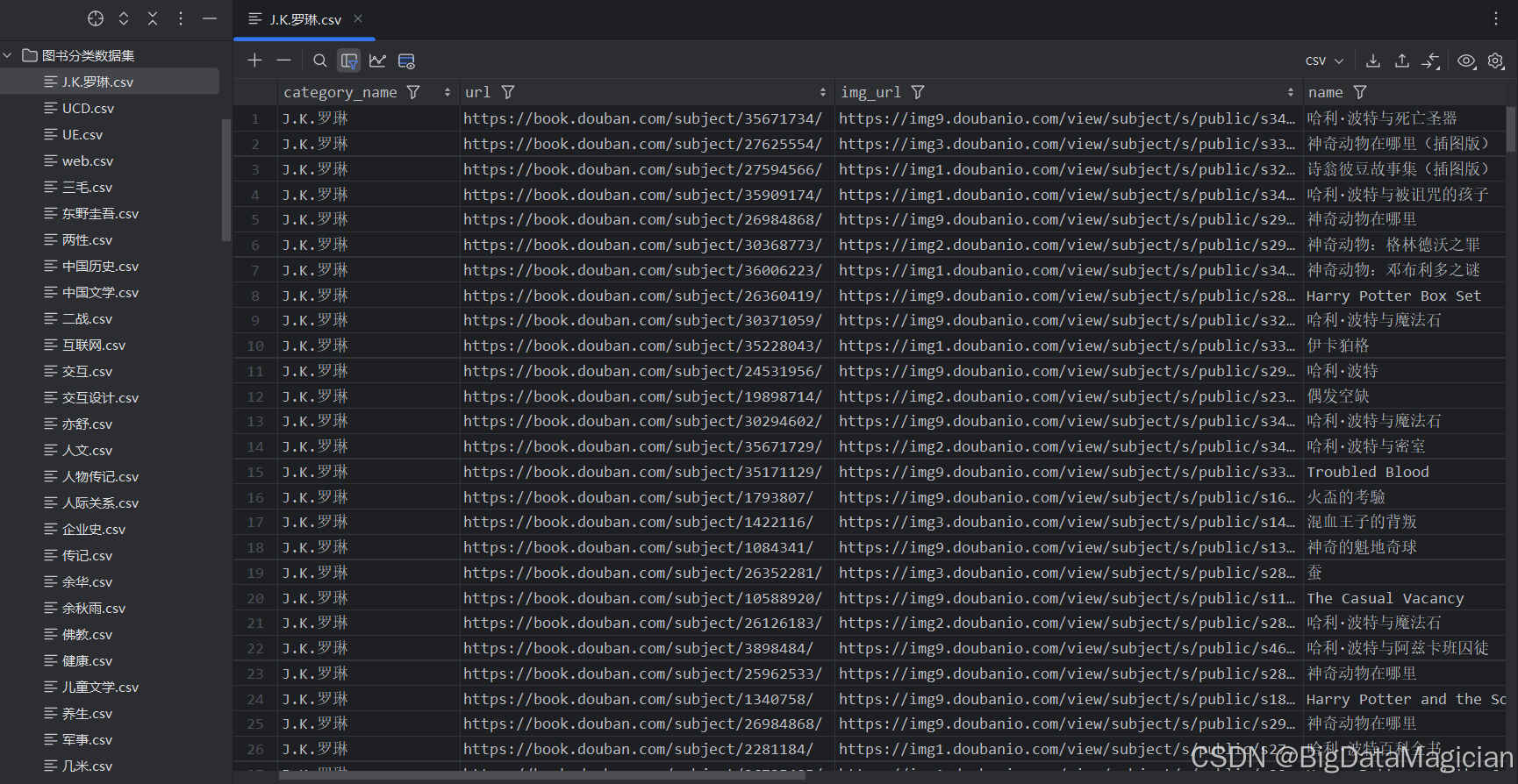
采集后的多个CSV文件及部分数据如下图所示:
3. 把多个分类的CSV数据文件整合到一个CSV文件中
把多个分类的CSV数据文件整合到一个CSV文件中的代码实现如下:
from pathlib import Path
import pandas as pd
def get_all_csv_files(source_dir):
"""
获取指定目录下所有的 CSV 文件路径
:param source_dir: 源目录路径
:return: 包含所有 CSV 文件路径的列表
"""
print(f"正在查找 {source_dir} 目录下的所有 CSV 文件...")
all_files = list(source_dir.glob('*.csv'))
print(f"共找到 {len(all_files)} 个 CSV 文件。")
return all_files
def read_csv_files(file_paths):
"""
读取所有 CSV 文件并将其转换为 DataFrame 对象
:param file_paths: 包含所有 CSV 文件路径的列表
:return: 包含所有 DataFrame 对象的列表
"""
print("开始读取 CSV 文件...")
dfs = []
for file in file_paths:
try:
df = pd.read_csv(file, index_col=None, header=0)
dfs.append(df)
print(f"成功读取文件: {file}")
except Exception as e:
print(f"读取文件 {file} 时出错: {e}")
return dfs
def combine_dataframes(dfs):
"""
合并所有 DataFrame 对象
:param dfs: 包含所有 DataFrame 对象的列表
:return: 合并后的 DataFrame 对象
"""
print("开始合并所有 DataFrame...")
combined_df = pd.concat(dfs, axis=0, ignore_index=True)
print("DataFrame 合并完成。")
return combined_df
def save_combined_dataframe(combined_df, output_file_path):
"""
将合并后的 DataFrame 对象保存为 CSV 文件
:param combined_df: 合并后的 DataFrame 对象
:param output_file_path: 输出文件的路径
"""
print(f"开始将合并后的数据保存到 {output_file_path}...")
try:
combined_df.to_csv(output_file_path, index=False, encoding='utf-8-sig')
print(f"所有 CSV 文件已成功合并,并保存至 {output_file_path}")
except Exception as e:
print(f"保存文件时出错: {e}")
def main():
# 设置源目录和目标文件路径
source_dir = Path("./原始数据层/图书分类数据集")
output_dir = Path("./原始数据层")
output_file_path = output_dir / '豆瓣图书数据集.csv'
# 创建输出目录(如果不存在)
output_dir.mkdir(parents=True, exist_ok=True)
# 获取所有 CSV 文件
all_files = get_all_csv_files(source_dir)
# 读取所有 CSV 文件
dfs = read_csv_files(all_files)
# 合并所有 DataFrame
combined_df = combine_dataframes(dfs)
# 保存合并后的 DataFrame
save_combined_dataframe(combined_df, output_file_path)
if __name__ == "__main__":
main()
整合后的数据集有12万多条数据,部分数据如下图所示:



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











