







冒泡排序就如其名一样,大(小)的数据如同气泡一样不停往上冒,经过多次冒泡,数据就变得有序了。
下面举个例子:
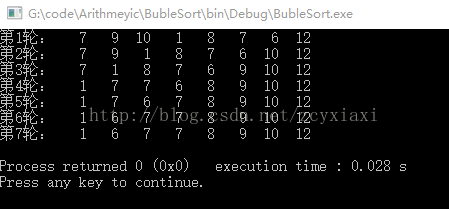
数组 :9 7 10 12 1 8 7 6
第一轮:7 9 10 1 8 7 6 12
第二轮:7 9 1 8 7 6 10 12
第三轮:7 1 8 7 6 9 10 12
第四轮:1 7 7 6 8 9 10 12
第五轮:1 7 6 7 8 9 10 12
第六轮:1 6 7 7 8 9 10 12
第七轮:1 6 7 7 8 9 10 12
实现方法:通过相邻的数进行对比,若第i+1个数比第i个数大,则交换两个数的位置,一轮下来后,最大的数就被交换到数组尾部(冒泡出去了),而下一轮的对比就不会再对这个数进行对比。
常规的冒泡排序算法代码:
void swap(int *a,int *b)
{
int temp ;
temp = *a;
*a = *b;
*b = temp;
}
void BubleSort(int *arr,int len)
{
int i,j;
for(i = 0;i < len - 1;i++)
{
printf("第%d轮:",i+1);
for(j = 0;j < len - 1;j++)
{
if(arr[j] > arr[j+1])
{
swap(&arr[j],&arr[j+1]);
}
printf("%4d",arr[j]);
}
printf("%4d\n",arr[j]);
}
}
int main()
{
int sort[] = {9, 7, 10, 12, 1, 8, 7, 6};
BubleSort(sort,8);
return 0;
}
上面的冒泡排序的时间复杂度是O(n^2),从上面的代码可以看到这种实现方式效率比较低,体现在哪些方面呢?
1.每一轮循环都是(len-1)次,但是我们知道,每一轮对比交换后,就会有i个数是排序好的。
2.如第6轮和第7轮,可以看到两者是没有进行交换的。
从上面可以提出改进的方法:
1.每一轮的对比交换都排除已经排序好的数,即只进行(len-1-i)次对比。
2.如果某一轮没有进行交换,则表示已经排序结束,退出循环。
为了更好地体现改进的效果,对前面的数据的顺序进行调整,代码如下:
#include <stdio.h>
#include <stdlib.h>
void swap(int *a,int *b)
{
int temp ;
temp = *a;
*a = *b;
*b = temp;
}
void BubleSort_improve(int *arr,int len)
{
int i,j;
int flag = 0; //默认没有进行交换
for(i = 0;i < len - 1;i++)
{
flag = 0;
for(j = 0;j < len - 1 - i;j++)
{
if(arr[j] > arr[j+1])
{
swap(&arr[j],&arr[j+1]);
flag = 1;
}
}
printf("第%d轮:",i+1);
for(j = 0;j < len;j ++)
{
printf("%4d",arr[j]);
}
printf("\n");
if(!flag) break;
}
}
int main()
{
int sort[] = {1, 6, 10, 12, 9, 8, 7, 7};
BubleSort_improve(sort,8);
return 0;
}
运行的结果如下图所示:
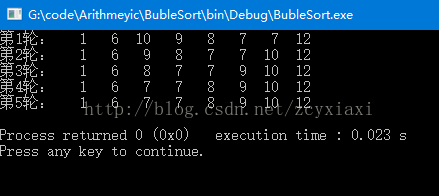
可以看到执行次数明显减少了。虽然运行时间在这里不可以作为参考,但是从逻辑上是可以看出优化后的实现方法更为简单有效。
改进后的冒泡排序算法,最好的情况时间复杂度为O(n),最差为O((n*(n-1))/2).,即O(n^2)。















 117
117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









