







如博客机器学习3中提到得,当训练集有限时,可能会有多个假设空间或有多个能够和训练集 fit 得模型,此时我们就需要考虑归纳偏好 (inductive bias).
比如,在西瓜问题中,如果我们更偏好特殊得情况,我们就会选择(*, 蜷缩,浊响)作为模型;
在房价问题中,一元一次函数和一元二次函数两个模型应该怎么选择呢?
著名的“奥卡姆剃刀”(Occam’s Razor) 原则认为“若有多个假设与观察一致,则选最简单的那个”
但是何为“简单”便见仁见智了,如果认为函数的幂次越低越简单,则此时一元线性回归算法更好,如果认为幂次越高越简单,则此时多项式回归算法更好,因此该方法其实并不“简单”,所以并不常用.最常用的方法则是基于模型在测试集上的表现来评判模型之间的优劣。
Theorem 1.4.1 (No Free Lunch Theorem). 众算法皆平等,无论算法设计的多么巧妙或者多么愚蠢,他们的期望性能是一样的.
假设我们有算法 La 和算法 Lb, 离散的样本空间 X 和假设空间 H,P (h|X, La) 表示算法 La 基于数据集 X 得到假设 h 得概率,f 表示我们希望学习的真实函数,I() 是指示函数,括号内为真输出 1,括号内为假输出 0. 我们可以计算算法 La 在训练集 (X) 之外的所有 instances 上的误差:
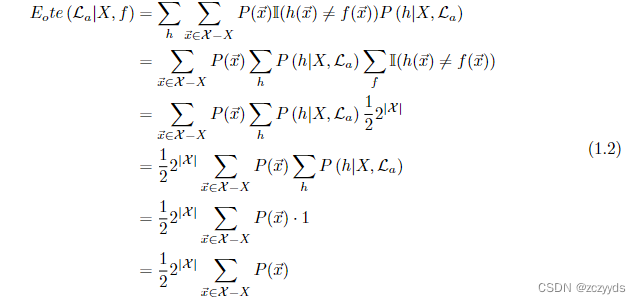
从 Equation 1.2, 我们会惊奇得发现,总误差竟然和选择的算法没有任何关系。这就是 NFL 定理。
但这个推导并不完全,需要注意的是,在这里我们假设真实的目标函数 f 服从均匀分布,但是实际 情形并非如此,通常我们只认为能高度拟合已有样本数据的函数才是真实目标函数
例如,在二分类问题中(将输入映射到{0.1}),假设样本空间只有两个样本时,X = x1, x2, |X | = 2。那么所有可能的真实目标函数 f 如 Equation 1.3 所示:
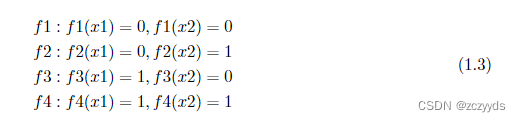
如现在已有的样本数据为 (x1, 0),(x2, 1),那么此时 f2 才是我们认为的真实目标函数,由于没有收集到或者压根不存在 (x1, 0),(x2, 0), (x1, 1),(x2, 0),(x1, 1),(x2, 1) 这类样本,所以 f1, f3, f4 都不算是真实目标函数。
All in all, 脱离实际问题,空泛的谈论什么算法更好,毫无意义















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









