







http://www.cnblogs.com/snowballed/p/7245739.html
在前面学习了存储过程的开发、调试之后,我们现在就需要来使用存储过程了。简单的使用,像上篇《懵懂oracle之存储过程2》中提到的存储过程调用,我们可以将写好的存储过程在另一个PL/SQL块亦或是另一个存储过程中调用执行,而很多情况下,我们往往需要定时执行这个存储过程,那么我们就需要使用到Oracle的JOB,让我们的数据库可以定期的执行特定的任务。
下面就让我们来了解下JOB的方方面面:
在Oracle 10g以前,Oracle提供了dbms_job系统包来实现job,到Oracle 10g时,就多出了dbms_scheduler包来实现job,它比dbms_job拥有更强大的功能和更灵活的机制,在本文暂只介绍dbms_job的知识,所用的数据库版本Oracle 11g。
1 初始化
1.1 初始化权限
使用dbms_job包如果遇到权限问题,那么需要使用管理员账号给此用户赋予权限:
1 grant execute on dbms_job to 用户;
1.2 初始化参数
重点关注job_queue_processes参数,它告诉了数据库最多可创建多少个job进程来运行job,可通过下面语句查询改参数值情况:
1 select name, value, display_value from v$parameter where name in ('spfile', 'job_queue_processes');
当job_queue_processes参数对应的value为0时,则代表所有创建的job都不会运行,因此我们需将此参数值根据各自需要修改至n(1~1000):
- 当上述语句未查询出spfile参数时,则表示数据库以pfile启动,该文件默认位置为%ORACLE_HOME%\database目录下的init<sid>.ora文件(sid-->数据库实例名)。此时若要修改参数值,则需打开此文件进行增加或修改下行信息,而后重启数据库才能生效:
1 JOB_QUEUE_PROCESSES=n
-
当上述语句可查询出spfile参数时,则表示数据库以spfile启动,该文件的位置可从value值中得到。此时若要修改参数值,则可通过在数据库执行下列语句进行修改:

1 alter system set job_queue_processes=n; 2 /* 3 alter system 参数名=值 [scope=应用范围]; 4 scope需知: 5 scope=both,表示修改会立即生效且会修改spfile文件以确保数据库在重启后也会生效如果(以spfile启动此项为缺省值); 6 scope=memory,表示修改会立即生效但不会修改spfile文件,因此重启后失效(以pfile启动此项为缺省值,且只可设置这个值); 7 scope=spfile,表示只修改spfile文件,在重启数据库后才生效(对应静态参数则只可设置此项值,设置其它值会报错: 8 ORA-02095: specified initialization parameter cannot be modified)。 9 */
2 dbms_job包分析(可在数据库中查看此包获取相关信息,暂未分析包内user_export存过的用法)
2.1 内部存过参数汇总
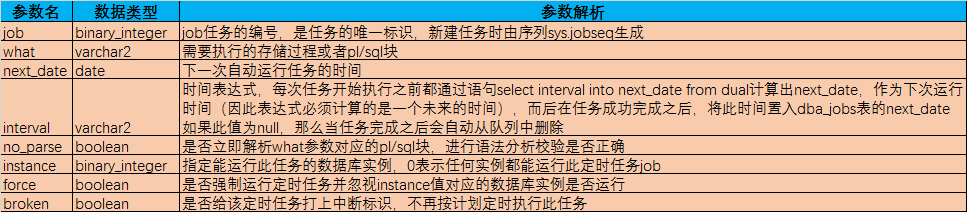
2.2 内部存过详解

1 create or replace procedure sp_test_hll_170726 AUTHID CURRENT_USER as 2 v_flag number; 3 begin 4 select count(1) 5 into v_flag 6 from user_tables 7 where table_name = 'TEST_TABLE_170726'; 8 if v_flag = 0 then 9 execute immediate 'create table test_table_170726(id number, create_time date default sysdate)'; 10 end if; 11 select count(1) 12 into v_flag 13 from user_sequences 14 where sequence_name = 'SEQ_TEST_TABLE_170726_ID'; 15 if v_flag = 0 then 16 execute immediate 'create sequence seq_test_table_170726_id'; 17 end if; 18 execute immediate 'insert into test_table_170726(id) values(seq_test_table_170726_id.nextval)'; 19 commit; 20 end sp_test_hll_170726; 21 /
1) submit:用于新建一个定时任务
- 定义:
1 procedure submit(job out binary_integer, 2 what in varchar2, 3 next_date in date default sysdate, 4 interval in varchar2 default 'null', 5 no_parse in boolean default false, 6 instance in binary_integer default 0, 7 force in boolean default false);
- 范例1:
1 declare 2 jobno number; 3 begin 4 dbms_job.submit( 5 jobno,--定义的变量作为submit存过的出参,submit内部调用序列生成此值 6 'sp_test_hll_170726;' , --job要执行的工作(范例为要执行的存储过程,必须加分号,格式如:存过1;存过2;存过3;……) 7 sysdate,--设置下次运行时间为当前系统时间,以使job在提交后立马运行(因为之后的系统时间>=此时的'sysdate') 8 'sysdate+10/(24*60*60)' --设置定时周期为10秒运行一次 9 ); 10 dbms_output.put_line(jobno);--输出以供查看本次创建的job的编号,或查看dba_jobs/all_jobs/user_jobs视图中最新行亦可 11 commit;--请记得提交,提交之后才会生效并按计划执行此项定时任务 12 end; 13 /
- 范例2(存过sp_hll_test_20170415见《懵懂oracle之存储过程》):
1 declare 2 jobno number; 3 begin 4 dbms_job.submit(jobno, 5 'declare 6 a number; 7 b date; 8 c varchar2(20); 9 d number; 10 status user_tables.status%type; 11 e varchar2(200); 12 begin 13 sp_hll_test_20170415(a, b, c, d, status, e); 14 a := 3; 15 sp_hll_test_20170415(a, to_date(''2017-6-16'', ''yyyy-mm-dd''), ''我是常量C'', d, ''0'', e); 16 insert into test_table_170726(id,create_time) values (seq_test_table_170726_id.nextval,to_date(''2017-6-16'', ''yyyy-mm-dd'')); 17 commit; 18 end;', --job要执行的工作(范例为要执行的PL/SQL块,块内单引号处理成双单引号) 19 case 20 when sysdate > trunc(sysdate) + 21 (11 * 60 * 60 + 11 * 60 + 11) / (24 * 60 * 60) then 22 trunc(sysdate + 1) + 23 (11 * 60 * 60 + 11 * 60 + 11) / (24 * 60 * 60) 24 else 25 trunc(sysdate) + (11 * 60 * 60 + 11 * 60 + 11) / (24 * 60 * 60) 26 end, --设置下次运行时间为接下来最近的一次11点11分11秒 27 null --设置为单次运行,一般用于需单次运转的耗时较长的任务,在成功完成后job记录会自动删除掉 28 ); 29 dbms_output.put_line(jobno); 30 commit; 31 end; 32 /
- 备注:
1. what参数,用于定时任务执行的具体内容:
格式 ==> 存过1;存过2;存过3;…… | '处理过单引号的PL/SQL块'
建议使用后者,如果是前者情况,也用begin end进行包裹,如 begin 存过1;存过2;存过3;…… end; ,否则少数情况下会出现一些莫名其妙的问题……暂无实例。
2. interval参数,用于设置定时任务时间间隔:
格式 ==> null | '处理过单引号的时间表达式'
设置为null表示单次运行,在成功完成后会从JOB任务队列中删除此JOB。
时间表达式:通过 select 时间表达式 from dual; 可得到一个未来时间点,每次任务开始执行之前都获取这个未来时间点作为下次运行任务的时间,然后在任务执行完成后,才会把此时间更新至JOB任务队列的next_date字段中,等待下次sysdate >= next_date时再次执行此任务。之所以“>=”而不是“=”,是因为存在后面几种情况:
-1-创建定时任务时,next_date就小于系统时间;
-2-单次任务执行的时间超过任务开始执行时计算出的next_date,以致next_date小于任务执行完成后的系统时间,此时任务会立马进行再一轮的执行;
-3-参数job_queue_processes的限制或者数据库性能的限制或数据库关闭等,导致next_date=当时的sysdate时,任务无法按时开始执行。
由于上面第三种情况的存在,因此对于interval参数设置大致可分两种情况:
-1 时间定隔循环,不考虑时间点的精确性,则只需使用sysdate即可,例如 interval = 'sysdate + 数值' ,数值(1=1天,1/24=1小时,1/(24*60)=1分钟,1/(24*60*60)=1秒钟),数值为1时实现每隔一天执行一次这样的简单循环。
-2 时间定点循环,需确保每次执行的时间点精确性,则一般需配合trunc函数进行处理,例如 interval = 'trunc(sysdate,''dd'') + 数值' ,数值为1/24时实现每天1点执行此任务这样精确的循环,以消除每次执行定时任务时的时间飘移的积累,以致时间点越来越不正确,同时由他人手工调用dbms_job.run对某定时任务进行手动执行,导致取手动运行任务时的系统时间作为sysdate计算下次的时间会产生更大的时间差异,也会使执行的时间和当初计划的时间不符的现象出现,因此用trunc等函数处理来保证时间点的精确性。
常用函数trunc、numtoyminterval、numtoyminterval、add_months、next_day、last_day介绍:
3. instance、force参数,用于设置定时任务于数据库实例的关联性:
1 select sysdate, trunc(sysdate), trunc(sysdate,'MON') from dual; 2 /* 3 trunc(date, [format]): 4 format可取值汇总(不区分大小写): 5 本世纪第一天 ==> CC,SCC 6 本年第一天 ==> SYYYY, YYYY, YEAR, SYEAR, YYY, YY, Y 7 本ISO年第一天(每个星期从星期一开始,每年的第一个星期包含当年的第一个星期四(并且总是包含1月4日)) ==> IYYY, IY, I 8 本季度第一天 ==> Q 9 本月第一天 ==> MONTH, MON, MM, RM 10 本周第一天 ==> WW(按年度1月1日的第一天为每周第一天), 11 IW(星期一为每周第一天), 12 W(按月份1日的第一天作为每周第一天), 13 DAY, DY, D(星期日为每周第一天) 14 本日(零点零分)(缺省值) ==> DDD, DD, J 15 本小时(零分零秒) ==> HH, HH12, HH24 16 本分钟(零秒) ==> MI 17 */ 18 19 select sysdate + numtoyminterval(-5, 'year') 五年前, 20 sysdate + numtodsinterval(-10, 'day') 十天前, 21 sysdate + numtodsinterval(-2, 'hour') 两小时前, 22 sysdate + numtodsinterval(1, 'minute') 一分钟前, 23 sysdate + numtodsinterval(10, 'second') 十秒后, 24 sysdate + numtoyminterval(3, 'month') 三月后 25 from dual; 26 /* 27 numtodsinterval(num, format): 28 num可取整数(正整数表示加,负整数表示减); 29 format可取值汇总(不区分大小写):DAY,HOUR,MINUTE,SECOND 30 31 numtoyminterval(num, format): 32 num可取整数(正整数表示加,负整数表示减); 33 format可取值汇总(不区分大小写):YEAR,MONTH 34 */ 35 36 select sysdate 现在, add_months(sysdate, -12) 一年前, add_months(sysdate, 3) 三月后 from dual; 37 /* 38 add_months(date, num): 39 date为具体时间,经add_months处理不会变动时分秒,日期年月进行加减; 40 num可取整数(正整数表示加,负整数表示减); 41 */ 42 43 select next_day(sysdate, 44 case value 45 when 'SIMPLIFIED CHINESE' then 46 '星期六' 47 else 48 'SAT' 49 end) 下周一此时此分此秒, next_day(sysdate, 1) 下周日此时此分此秒 50 from v$parameter 51 where name = 'nls_date_language'; 52 /* 53 next_day(date, format) : 54 date为具体时间,经next_day处理不会变动时分秒,日期被处理至下个周一~周日; 55 format可取值汇总(不区分大小写): 56 星期一~星期日(对应字符集NLS_DATE_LANGUAGE = SIMPLIFIED CHINESE) 57 Monday~Sunday 或者 Mon~Sun(对应字符集NLS_DATE_LANGUAGE = AMERICAN) 58 1~7(1为周日) 59 */ 60 61 select to_date('2017-2-1 11:11:11', 'yyyy-mm-dd hh24:mi:ss') "2017/2/1 11:11:11", 62 last_day(to_date('2017-2-1 11:11:11', 'yyyy-mm-dd hh24:mi:ss')) "17年2月末此时此分此秒" 63 from dual; 64 /* 65 last_day(date) : 66 date为具体时间,经last_day处理不会变动时分秒,日期被处理至月底最后一天 67 */
在Oracle RAC环境下,多个数据库实例并发使用同一个数据库,是Oracle9i新版数据库中采用的一项新技术,解决了传统数据库应用中面临的一个重要问题:高性能、高可伸缩性与低价格之间的矛盾!但是在涉及到我们的定时任务时,如果是RAC环境,它是怎么运行的呢?有多台机器这个定时任务这次到底会在哪个机器上运行呢?instance参数就可配置指定机器对应的数据库实例,如不修改默认此值为0,表示就是所有数据库实例都可运行此项定时任务,每次这个任务执行时就可能在a机器,也可能在b机器,一般我们也是不指定此值的。当遇到需要指定此值时,需关注下面查询的情况,取instance_name作为instance参数值。
1 select inst_id,instance_number,instance_name,host_name, 2 utl_inaddr.get_host_address(host_name) public_ip,status,version 3 from gv$instance;
同时force参数在设置为true时,也能达到和instance=0时一样的效果,解除JOB执行和数据库实例的关联性,它的默认值是false,表示按照instance值的情况进行判断数据库实例的关联性。
4. what、interval参数都需注意内部单引号处理成双单引号,可用 select 参数值 from dual; 查询得到实际对应的存过或PL/SQL块或时间表达式,来判断是否设置正确。
2) isubmit:用于新建一个定时任务同时指定JOB编号
- 定义:
1 procedure isubmit(job in binary_integer, 2 what in varchar2, 3 next_date in date, 4 interval in varchar2 default 'null', 5 no_parse in boolean default false);
- 范例:
1 begin 2 dbms_job.isubmit(23, --指定job编号,不可用已有job的编号,否则报违反唯一约束的异常 3 'declare 4 a number; 5 b date; 6 c varchar2(20); 7 d number; 8 status user_tables.status%type; 9 e varchar2(200); 10 begin 11 sp_hll_test_20170415(a, b, c, d, status, e); 12 a := 3; 13 sp_hll_test_20170415(a, to_date(''2017-6-16'', ''yyyy-mm-dd''), ''我是常量C'', d, ''0'', e); 14 insert into test_table_170726(id,create_time) values (seq_test_table_170726_id.nextval,to_date(''2017-6-16'', ''yyyy-mm-dd'')); 15 commit; 16 end;', 17 sysdate, 18 'trunc(sysdate + numtoyminterval(1,''year''),''yyyy'')+1/24' --每年一月一号一点执行 19 ); 20 commit; 21 end; 22 /
- 备注:
除job为入参需指定外,其它使用情况与submit相同,指定job编号时,不可用已存在job的编号,否则导致异常 ORA-00001: 违反唯一约束条件 (SYS.I_JOB_JOB) 。
3) remove:用于从JOB任务队列中移除一个JOB(不会中断仍在运行的JOB)
- 定义:
1 procedure remove(job in binary_integer);
- 范例:
1 begin 2 dbms_job.remove(23); 3 commit; 4 end; 5 /
- 备注:
移除需移除已存在JOB,否则导致异常 ORA-23421: 作业编号111在作业队列中不是一个作业 。
4) what:用于修改what参数值
- 定义:
1 procedure what(job in binary_integer, what in varchar2);
- 范例:
1 declare 2 jobno number; 3 begin 4 select job into jobno from user_jobs where what like '%sp_test_hll_170726%'; 5 dbms_job.what(jobno, 'begin sp_test_hll_170726; end;'); --修改成pl/sql块形式 6 commit; 7 end; 8 /
5) next_date:用于修改next_date参数值
- 定义:
1 procedure next_date(job in binary_integer, next_date in date);
- 范例:
1 declare 2 jobno number; 3 begin 4 select job into jobno from user_jobs where what like '%sp_test_hll_170726%'; 5 dbms_job.next_date(jobno, trunc(sysdate + 1)); --修改最近一次待执行的时间至明天凌晨 6 commit; 7 end; 8 /
6) interval:用于修改interval参数值
- 定义:
1 procedure interval(job in binary_integer, interval in varchar2);
- 范例:
1 declare 2 jobno number; 3 begin 4 select job into jobno from user_jobs where what like '%sp_test_hll_170726%'; 5 dbms_job.interval(jobno, 'sysdate + 1'); --修改为每隔一天运行一次 6 commit; 7 end; 8 /
7) instance:用于修改instance、force参数值
- 定义:
1 procedure instance(job in binary_integer, 2 instance in binary_integer, 3 force in boolean default false);
- 范例:
1 declare 2 jobno number; 3 begin 4 select job into jobno from user_jobs where what like '%sp_test_hll_170726%'; 5 dbms_job.instance(jobno, 1); --修改为数据库实例1才能运行此定时任务 6 commit; 7 end; 8 /
- 备注:
请勿修改已在运行的JOB的数据库实例,根据网络搜索得知:job会不再运行,并出现等待事件:enq: TX - row lock contention,执行的sql是 update sys.job$ set this_date=:1 where job=:2 ,也就是在更新sys的sys.job$表,最后只能杀掉此会话,才消除此等待事件。
一般情况下,建立不要指定JOB在特定实例运行,通常都默认为0。
下面change也需注意此处备注。
8) change:用于修改what、next_date、interval、instance、force参数值
- 定义:
1 procedure change(job in binary_integer, 2 what in varchar2, 3 next_date in date, 4 interval in varchar2, 5 instance in binary_integer default null, 6 force in boolean default false);
- 范例:
1 declare 2 jobno number; 3 begin 4 select job into jobno from user_jobs where what like '%sp_test_hll_170726%'; 5 dbms_job.change(jobno, 6 'begin sp_test_hll_170726; end;', 7 sysdate, 8 'sysdate + 1/24');--实现多参数修改 9 commit; 10 end; 11 /
9) broken:用于给定时任务添加或去除中断标识,将任务挂起或取消挂起(不会中断仍在运行的JOB)
- 定义:
1 procedure broken(job in binary_integer, 2 broken in boolean, 3 next_date in date default sysdate);
- 范例:
1 declare 2 jobno number; 3 begin 4 select job into jobno from user_jobs where what like '%sp_test_hll_170726%'; 5 dbms_job.broken(jobno, true);--挂起 6 commit; 7 end; 8 /
- 备注:
挂起时,会修改JOB任务队列中字段broken='Y',next_date='4000/1/1',next_sec='00:00:00',只要broken='Y',就算next_date<sysdate,此任务也不会执行;
取消挂起时,会修改broken='N',next_date与next_sec安照next_date参数值进行调整,任务查询开始按计划执行。
10) run:用于立即执行此定时任务(被broken挂起的存过也会取消挂起并运行)
- 定义:
1 procedure run(job in binary_integer, force in boolean default false);
- 范例:
1 declare 2 jobno number; 3 begin 4 select job into jobno from user_jobs where what like '%sp_test_hll_170726%'; 5 dbms_job.run(jobno);--立即运行 6 commit; 7 end; 8 /
- 备注:
当任务挂起时,会修改broken='N';
当数据库实例不符时也可通过修改force=true以强制在当前数据库实例运行,确保run能一定运行此项任务。
3 JOB任务队列查询处理汇总
3.1 表汇总(SYS.JOB$、DBA_JOBS、ALL_JOBS、USER_JOBS、DBA_JOBS_RUNNING)
在通过上面介绍的dbms_job包对JOB进行的处理,实际上处理的是数据库的任务队列表SYS.JOB$,我们可以通过下面语句查看该表情况:
1 select t.job, t.lowner, t.powner, t.cowner, t.last_date, t.this_date, t.next_date, t.total, t.interval#, t.failures, t.flag, t.what, 2 t.nlsenv, t.env, t.charenv, t.field1, t.scheduler_flags, t.xid 3 /*, t.cur_ses_label, t.clearance_hi, t.clearance_lo 4 不能查询这三个字段,会报异常ORA-00932: 数据类型不一致: 应为 NUMBER, 但却获得 LABEL 5 它们的数据类型为MLSLABEL,在TRUSTED ORACLE中用来保存可变长度二进制标签。 6 */ 7 from sys.job$ t;
但是它的数据长得不好看,Oracle提供了我们两个视图(DBA_JOBS、USER_JOBS)可以查看:
1 create or replace view sys.dba_jobs as 2 select JOB, lowner LOG_USER, powner PRIV_USER, cowner SCHEMA_USER, 3 LAST_DATE, substr(to_char(last_date,'HH24:MI:SS'),1,8) LAST_SEC, 4 THIS_DATE, substr(to_char(this_date,'HH24:MI:SS'),1,8) THIS_SEC, 5 NEXT_DATE, substr(to_char(next_date,'HH24:MI:SS'),1,8) NEXT_SEC, 6 (total+(sysdate-nvl(this_date,sysdate)))*86400 TOTAL_TIME, 7 decode(mod(FLAG,2),1,'Y',0,'N','?') BROKEN, 8 INTERVAL# interval, FAILURES, WHAT, 9 nlsenv NLS_ENV, env MISC_ENV, j.field1 INSTANCE 10 from sys.job$ j 11 where BITAND(j.scheduler_flags, 2) IS NULL OR 12 BITAND(j.scheduler_flags, 2) = 0 /* don't show jobs with drop flag */; 13 comment on table SYS.DBA_JOBS is 'All jobs in the database'; 14 comment on column SYS.DBA_JOBS.JOB is 'Identifier of job. Neither import/export nor repeated executions change it.'; 15 comment on column SYS.DBA_JOBS.LOG_USER is 'USER who was logged in when the job was submitted'; 16 comment on column SYS.DBA_JOBS.PRIV_USER is 'USER whose default privileges apply to this job'; 17 comment on column SYS.DBA_JOBS.SCHEMA_USER is 'select * from bar means select * from schema_user.bar '; 18 comment on column SYS.DBA_JOBS.LAST_DATE is 'Date that this job last successfully executed'; 19 comment on column SYS.DBA_JOBS.LAST_SEC is 'Same as LAST_DATE. This is when the last successful execution started.'; 20 comment on column SYS.DBA_JOBS.THIS_DATE is 'Date that this job started executing (usually null if not executing)'; 21 comment on column SYS.DBA_JOBS.THIS_SEC is 'Same as THIS_DATE. This is when the last successful execution started.'; 22 comment on column SYS.DBA_JOBS.NEXT_DATE is 'Date that this job will next be executed'; 23 comment on column SYS.DBA_JOBS.NEXT_SEC is 'Same as NEXT_DATE. The job becomes due for execution at this time.'; 24 comment on column SYS.DBA_JOBS.TOTAL_TIME is 'Total wallclock time spent by the system on this job, in seconds'; 25 comment on column SYS.DBA_JOBS.BROKEN is 'If Y, no attempt is being made to run this job. See dbms_jobq.broken(job).'; 26 comment on column SYS.DBA_JOBS.INTERVAL is 'A date function, evaluated at the start of execution, becomes next NEXT_DATE'; 27 comment on column SYS.DBA_JOBS.FAILURES is 'How many times has this job started and failed since its last success?'; 28 comment on column SYS.DBA_JOBS.WHAT is 'Body of the anonymous PL/SQL block that this job executes'; 29 comment on column SYS.DBA_JOBS.NLS_ENV is 'alter session parameters describing the NLS environment of the job'; 30 comment on column SYS.DBA_JOBS.MISC_ENV is 'a versioned raw maintained by the kernel, for other session parameters'; 31 comment on column SYS.DBA_JOBS.INSTANCE is 'Instance number restricted to run the job';
1 create or replace view sys.user_jobs as 2 select j."JOB",j."LOG_USER",j."PRIV_USER",j."SCHEMA_USER",j."LAST_DATE",j."LAST_SEC",j."THIS_DATE",j."THIS_SEC",j."NEXT_DATE",j."NEXT_SEC",j."TOTAL_TIME",j."BROKEN",j."INTERVAL",j."FAILURES",j."WHAT",j."NLS_ENV",j."MISC_ENV",j."INSTANCE" from dba_jobs j, sys.user$ u where 3 j.priv_user = u.name 4 and u.user# = USERENV('SCHEMAID'); 5 comment on table SYS.USER_JOBS is 'All jobs owned by this user'; 6 comment on column SYS.USER_JOBS.JOB is 'Identifier of job. Neither import/export nor repeated executions change it.'; 7 comment on column SYS.USER_JOBS.LOG_USER is 'USER who was logged in when the job was submitted'; 8 comment on column SYS.USER_JOBS.PRIV_USER is 'USER whose default privileges apply to this job'; 9 comment on column SYS.USER_JOBS.SCHEMA_USER is 'select * from bar means select * from schema_user.bar '; 10 comment on column SYS.USER_JOBS.LAST_DATE is 'Date that this job last successfully executed'; 11 comment on column SYS.USER_JOBS.LAST_SEC is 'Same as LAST_DATE. This is when the last successful execution started.'; 12 comment on column SYS.USER_JOBS.THIS_DATE is 'Date that this job started executing (usually null if not executing)'; 13 comment on column SYS.USER_JOBS.THIS_SEC is 'Same as THIS_DATE. This is when the last successful execution started.'; 14 comment on column SYS.USER_JOBS.NEXT_DATE is 'Date that this job will next be executed'; 15 comment on column SYS.USER_JOBS.NEXT_SEC is 'Same as NEXT_DATE. The job becomes due for execution at this time.'; 16 comment on column SYS.USER_JOBS.TOTAL_TIME is 'Total wallclock time spent by the system on this job, in seconds'; 17 comment on column SYS.USER_JOBS.BROKEN is 'If Y, no attempt is being made to run this job. See dbms_jobq.broken(job).'; 18 comment on column SYS.USER_JOBS.INTERVAL is 'A date function, evaluated at the start of execution, becomes next NEXT_DATE'; 19 comment on column SYS.USER_JOBS.FAILURES is 'How many times has this job started and failed since its last success?'; 20 comment on column SYS.USER_JOBS.WHAT is 'Body of the anonymous PL/SQL block that this job executes'; 21 comment on column SYS.USER_JOBS.NLS_ENV is 'alter session parameters describing the NLS environment of the job'; 22 comment on column SYS.USER_JOBS.MISC_ENV is 'a versioned raw maintained by the kernel, for other session parameters'; 23 comment on column SYS.USER_JOBS.INSTANCE is 'Instance number restricted to run the job';
同时通过下面语句我们可以知道,还有一个同义词ALL_JOBS:
1 select * 2 from all_objects t 3 where t.object_name in ('DBA_JOBS', 'ALL_JOBS', 'USER_JOBS'); 4 select * 5 from sys.all_synonyms 6 where synonym_name in ('DBA_JOBS', 'ALL_JOBS', 'USER_JOBS');
我们通过下面语句都能查询我们建立好的JOB的信息:
1 select * from dba_jobs; 2 select * from all_jobs; 3 select * from user_jobs;
DBA_JOBS/ALL_JOBS/USER_JOBS各字段的含义如下:
1 字段(列) 数据类型 描述 2 JOB NUMBER 任务的唯一标示号 3 【Identifier of job. Neither import/export nor repeated executions change it.】 4 LOG_USER VARCHAR2(30) 提交任务时登录的用户 5 【USER who was logged in when the job was submitted】 6 PRIV_USER VARCHAR2(30) 任务默认权限对应的用户 7 【USER whose default privileges apply to this job】 8 SCHEMA_USER VARCHAR2(30) 对任务作语法分析的用户模式(查询bar表代表查询schema_user.bar表) 9 【select * from bar means select * from schema_user.bar】 10 LAST_DATE DATE 最后一次成功运行任务的时间 11 【Date that this job last successfully executed】 12 LAST_SEC VARCHAR2(32) 长度为8的HH24:MI:SS格式的LAST_DATE 13 【Same as LAST_DATE. This is when the last successful execution started.】 14 THIS_DATE DATE 正在运行任务的开始时间,如果没有运行任务则为null 15 【Date that this job started executing (usually null if not executing)】 16 THIS_SEC VARCHAR2(32) 长度为8的HH24:MI:SS格式的THIS_DATE 17 【Same as THIS_DATE. This is when the last successful execution started.】 18 NEXT_DATE DATE 下一次定时运行任务的时间 19 【Date that this job will next be executed】 20 NEXT_SEC VARCHAR2(32) 长度为8的HH24:MI:SS格式的NEXT_DATE 21 【Same as NEXT_DATE. The job becomes due for execution at this time.】 22 TOTAL_TIME NUMBER 数据库用于执行此任务的总秒数统计 23 【Total wallclock time spent by the system on this job, in seconds】 24 BROKEN VARCHAR2(1) 中断标识,Y表示任务中断,不再尝试执行此任务 25 【If Y,no attempt is being made to run this job. See dbms_jobq.broken(job).】 26 INTERVAL VARCHAR2(200) 用于计算下此运行时间的时间表达式 27 【A date function, evaluated at the start of execution, becomes next NEXT_DATE】 28 FAILURES NUMBER 自最后一次成功之后任务运行失败的总次数 29 【How many times has this job started and failed since its last success?】 30 WHAT VARCHAR2(4000) 任务执行的匿名PL/SQL块 31 【Body of the anonymous PL/SQL block that this job executes】 32 NLS_ENV VARCHAR2(4000) 任务运行的NLS会话设置 33 【alter session parameters describing the NLS environment of the job】 34 MISC_ENV RAW(32) 任务运行的其他一些会话参数 35 【a versioned raw maintained by the kernel, for other session parameters】 36 INSTANCE NUMBER 任务执行时限制关联的数据库实例 37 【Instance number restricted to run the job】
同时,Oracle还提供了DBA_JOBS_RUNNING视图供我们查询正在运行的任务:
1 create or replace view sys.dba_jobs_running as 2 select v.SID, v.id2 JOB, j.FAILURES, 3 LAST_DATE, substr(to_char(last_date,'HH24:MI:SS'),1,8) LAST_SEC, 4 THIS_DATE, substr(to_char(this_date,'HH24:MI:SS'),1,8) THIS_SEC, 5 j.field1 INSTANCE 6 from sys.job$ j, v$lock v 7 where v.type = 'JQ' and j.job (+)= v.id2; 8 comment on table SYS.DBA_JOBS_RUNNING is 'All jobs in the database which are currently running, join v$lock and job$'; 9 comment on column SYS.DBA_JOBS_RUNNING.SID is 'Identifier of process which is executing the job. See v$lock.'; 10 comment on column SYS.DBA_JOBS_RUNNING.JOB is 'Identifier of job. This job is currently executing.'; 11 comment on column SYS.DBA_JOBS_RUNNING.FAILURES is 'How many times has this job started and failed since its last success?'; 12 comment on column SYS.DBA_JOBS_RUNNING.LAST_DATE is 'Date that this job last successfully executed'; 13 comment on column SYS.DBA_JOBS_RUNNING.LAST_SEC is 'Same as LAST_DATE. This is when the last successful execution started.'; 14 comment on column SYS.DBA_JOBS_RUNNING.THIS_DATE is 'Date that this job started executing (usually null if not executing)'; 15 comment on column SYS.DBA_JOBS_RUNNING.THIS_SEC is 'Same as THIS_DATE. This is when the last successful execution started.'; 16 comment on column SYS.DBA_JOBS_RUNNING.INSTANCE is 'The instance number restricted to run the job';
通过下面语句可简单查询该表情况:
1 select * from dba_jobs_running;
DBA_JOBS_RUNNING各字段含义如下:
1 字段(列) 数据类型 描述 2 SID NUMBER 正在运行任务的会话ID 3 【Identifier of process which is executing the job. See v$lock. 】 4 JOB NUMBER 正在运行任务的唯一标示号 5 【Identifier of job. This job is currently executing.】 6 FAILURES NUMBER 自最后一次成功之后任务运行失败的总次数 7 【How many times has this job started and failed since its last success?】 8 LAST_DATE DATE 最后一次成功运行任务的时间 9 【Date that this job last successfully executed】 10 LAST_SEC VARCHAR2(32) 长度为8的HH24:MI:SS格式的LAST_DATE 11 【Same as LAST_DATE. This is when the last successful execution started.】 12 THIS_DATE DATE 正在运行任务的开始时间,如果没有运行任务则为null 13 【Date that this job started executing (usually null if not executing)】 14 THIS_SEC VARCHAR2(32) 长度为8的HH24:MI:SS格式的THIS_DATE 15 【Same as THIS_DATE. This is when the last successful execution started.】 16 INSTANCE NUMBER 任务执行时限制关联的数据库实例 17 【Instance number restricted to run the job
3.2 JOB的失败重试
当JOB实现失败时,数据库会自动安排重新执行,此时JOB执行时间按下面情况来定:
1) 如果sysdate>=next_date,则直接执行;
2) 第i次失败,等待2i分钟后开始第i+1次数据库自动安排的重新执行,当2i>1440分钟时,时间固定为1440分钟;
3) 重试次数达16次时,JOB不再自动执行(用户还是可手动执行再失败的),标记中断标识,broken='Y',next_date='4000/1/1',next_sec='00:00:00'。
3.3 停止正在运行的JOB
由于remove、broken都只是影响任务后续的执行情况,并不会对正在运行的任务造成影响,而有些情况下,由于存储过程的问题或者数据之间的影响等各种原因导致JOB执行异常,我们需要终止正在运行的异常JOB;也可能是JOB执行时间过长,人为需要停止正在运行的JOB。在这个时候我们需要按下面步骤进行处理:
1 /*** 第一步:查询JOB情况得到需要停止的JOB的编号 ***/ 2 select * from user_jobs; 3 select * from dba_jobs_running; 4 5 /*** 第二步:将需要停止的JOB标记中断,以避免停止后又运行 ***/ 6 begin 7 dbms_job.broken(job编号, true); 8 commit; 9 end; 10 / 11 12 /*** 第三步:查询JOB运行情况,并选择适当语句杀会话,甚至杀进程(谨慎操作) ***/ 13 select /*b.sid, -- session的id 14 c.serial#, -- session的序列号 15 d.spid, -- 操作系统进程ID*/ 16 b.job, -- JOB编号 17 a.what, -- 任务内容 18 b.failures, -- 失败次数 19 b.this_date, -- 开始时间 20 floor(sysdate - b.this_date) || '天' || 21 to_char(trunc(sysdate, 'dd') + (sysdate - b.this_date), 'hh24:mi:ss') this_total, -- 当前耗时 22 (select f.sql_fulltext 23 from v$locked_object e, v$sql f 24 where e.session_id = c.sid 25 and f.hash_value = c.sql_hash_value 26 and rownum = 1) sql_fulltext, -- 如果锁对象,则获取当前sql 27 c.inst_id, -- 数据库实例ID 28 c.status, --会话状态 29 'alter system kill session ''' || b.sid || ',' || c.serial# || 30 ''' immediate;' 普通环境杀会话, -- session级杀会话 31 'alter system kill session ''' || b.sid || ',' || c.serial# || ',@' || 32 c.inst_id || ''' immediate;' RAC环境杀会话, -- RAC环境session级杀会话 33 /* 34 kill session语句并不实际杀死会话,只相当于让会话自我清除,在某些情况下,例如等待远程数据库应答或 35 回滚当前事务时,都会等待这些操作完成,这时就将会话状态标记为"marked for kill",数据库会尽快将它杀掉, 36 如果加上immediate,那么则会要求将控制权立即返回给当前会话 37 */ 38 'alter system disconnect session ''' || b.sid || ',' || c.serial# || 39 ''' post_transaction或immediate;' 数据库杀进程, 40 'alter system disconnect session ''' || b.sid || ',' || c.serial# || ',@' || 41 c.inst_id || ''' post_transaction或immediate;' 数据库RAC环境杀进程, 42 /* 43 disconnect是在数据库中从操作系统层面清除服务器进程, 44 post_transaction表示清除前需等待正在进行的事务完成, 45 而immediate则表示立即清除并回滚正在进行的事务, 46 两者必须有其一,都有时,post_transaction优先级高,忽视immediate子句。 47 用disconnect我们就不用切换到操作系统层面用下面语句去清除进程了 48 */ 49 g.host_name || '==>' || utl_inaddr.get_host_address(g.host_name) "机器==>IP", -- 机器及IP 50 'orakill ' || g.instance_name || ' ' || d.spid "Windows杀进程", 51 'kill ' || d.spid "UnixORLinux杀进程1", 52 'kill -9 ' || d.spid "UnixORLinux杀进程2" -- 用1杀不掉就加-9 53 /* 54 不管是在数据库用disconnect还是上面到操作系统上面敲kill命令,都是杀的进程, 55 杀掉操作系统进程是一件危险的事情,千万不得误杀,请务必谨慎操作,严格确认。 56 */ 57 from user_jobs a, 58 dba_jobs_running b, 59 gv$session c, 60 gv$process d, 61 gv$instance g 62 where a.job = b.job 63 and b.sid = c.sid 64 and c.paddr = d.addr 65 and g.inst_id = c.inst_id; 66 67 /*** 第四步:恢复JOB,使其继续执行 ***/ 68 -- 如果JOB未修复好,可不执行此步操作 69 begin 70 dbms_job.broken(job编号, false); 71 -- dbms_job.broken(job编号, false, 可加个参数修改接来下运行的时间原默认为sysdate); 72 commit; 73 end; 74 /















 1258
1258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









