







版权声明:本文为博主原创文章,博主允许转载,转载时请附上原创地址http://blog.csdn.net/csdn066。 http://blog.csdn.net/csdn066/article/details/76474061
#######pacemaker+corosync实现高可用集群#####
一.基础知识
1.pacemaker
pacemaker是一个开源的高可用资源管理器(CRM),位于HA集群架构中资源管理、资源代理(RA)这个层次,它不能提供底层心跳信息传递的功能,要想与对方节点通信需要借助底层的心跳传递服务,将信息通告给对方。(作为通信层和提供关系管理服务,心跳引擎,检测心跳信息)
2.Corosync
Corosync是集群管理套件的一部分,它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。
二.配置 server2和server3
1.yum源 server2和server3的yum源相同
[root@server3 ~]# vim /etc/yum.repos.d/rhel-source.repo
[rhel-source]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.66.250/rhel6.5
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.66.250/rhel6.5/HighAvailability
gpgcheck=0
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.66.250/rhel6.5/LoadBalancer
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.66.250/rhel6.5/ResilientStorage
gpgcheck=0
[ScalableFileSystem]
name=ScalableFileSystem
baseurl=http://172.25.66.250/rhel6.5/ScalableFileSystem
gpgcheck=0
2.节点配置
server2
[root@server2 ~]# yum install -y pacemaker corosync
[root@server2 ~]# cd /etc/corosync/
[root@server2 corosync]# ls
corosync.conf corosync.conf.example.udpu uidgid.d
corosync.conf.example service.d
[root@server2 corosync]# cp corosync.conf.example corosync.conf
[root@server2 corosync]# vim corosync.conf ##corosync的配置文件
1 # Please read the corosync.conf.5 manual page
2 compatibility: whitetank ##兼容0.8以前的版本
3
4 totem {
##totem定义集群内各节点间是怎么通信的,totem本是一种协议,专用于corosync专用于各节点间的协议
5 version: 2 ##totem的版本,不可更改
6 secauth: off ##安全认证
7 threads: 0 ##用于安全认证开启的并线程数
8 interface {
9 ringnumber: 0 ##回环号码
10 bindnetaddr: 172.25.66.0
##绑定心跳网段,corosync会自动判断本地网卡上配置的哪个ip地址是属于这个网络的,并把这个接口作为多播心跳信息传递的接口
11 mcastaddr: 226.94.1.1
##心跳信息组播地址,每个节点的组播地址必须为同一个
12 mcastport: 5405 ##组播时使用的端口
13 ttl: 1
##只向外一跳心跳信息,避免组播报文回路
14 }
15 }
16
17 logging {
18 fileline: off ##指定要打印的行
19 to_stderr: no ##日志信息是否发往错误输出(默认否)
20 to_logfile: yes ##是否记录日志文件
21 to_syslog: yes
##是否记录于syslog日志-->此类日志记录于/var/log/message中
22 logfile: /var/log/cluster/corosync.log ##日志存放位置
23 debug: off
##只要不是为了排错,最好关闭debug,它记录的信息过于详细,会占用大量的磁盘IO.
24 timestamp: on
##是否打印时间戳,利于定位错误,但会产生大量系统调用,消耗CPU资源
25 logger_subsys {
26 subsys: AMF
27 debug: off
28 }
29 }
30
31 amf {
32 mode: disabled
33 }
##如果想让pacemaker在corosync中以插件方式启动,需要 在corosync.conf文件中加上如下内容:
34 service {
35 name: pacemaker ## 模块名,启动corosync时同时启动pacemaker
36 ver: 0
37 }
[root@server2 corosync]# scp corosync.conf server3:/etc/corosync/##server3与server2配置相同
[root@server2 corosync]# /etc/init.d/corosync start
[root@server2 corosync]# tail -f /var/log/cluster/corosync.log ##开启服务后查看日志,确定服务配置没有错误
Jul 30 23:27:53 [2403] server2 pengine: info: determine_online_status_fencing: Node server3 is active
Jul 30 23:27:53 [2403] server2 pengine: info: determine_online_status: Node server3 is online
Jul 30 23:27:53 [2403] server2 pengine: notice: stage6: Delaying fencing operations until there are resources to manage
Jul 30 23:27:53 [2403] server2 pengine: notice: process_pe_message: Calculated Transition 6: /var/lib/pacemaker/pengine/pe-input-3.bz2
Jul 30 23:27:53 [2403] server2 pengine: notice: process_pe_message: Configuration ERRORs found during PE processing. Please run "crm_verify -L" to identify issues.
[root@server3 ~]# yum install -y pacemaker corosync
[root@server3 ~]# /etc/init.d/corosync start
Starting Corosync Cluster Engine (corosync): [ OK ]
[root@server2 corosync]# yum install -y crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm
[root@server3 corosync]# yum install -y crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm ##安装crm shell
• 关于crm shell的使用
---crm可以显示并修改配置文件
---直接执行crm命令进行交互式修改配置文件,交互式输入的内容被记 录在配置文件中
---show 显示配置文件
---commit提交
---如果添加资源时出错,首先进入resource,将添加的资源stop,然后进 入cofigure,delete添加错误的资源
[root@server2 ~]# crm ##crm命令进入交互式shell
crm(live)# configure ##进入configure,执行show我们就可以看到配置文件的内容
crm(live)configure# show
node server2
node server3
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
这里简单介绍在添加资源时命令写错的解决方法
[root@server2 ~]# crm ##在添加ivp时将ip地址写错了crm(live)# resource ##先进入资源——resource
crm(live)resource# ##table我们可以看到在这里可以进行的操作
? failcount param show unmove
bye help promote start untrace
cd list quit status up
cleanup manage refresh stop utilization
demote meta reprobe trace
end migrate restart unmanage
exit move secret unmigrate
crm(live)resource# stop vip ##首先停掉资源,当资源在使用时是无法对他进行改动的
crm(live)resource# delete vip ##但是不能在这里delete,会报错语法错误
ERROR: syntax: delete vip
[root@server2 ~]# crm
crm(live)# configure ##进入configure执行delete
crm(live)configure# delete vip
crm(live)configure# commit ##删除后一定要提交,接下来就可以重新进行配置了
crm(live)configure# bye
[root@server2 ~]# crm
crm(live)# configure
crm(live)configure# property stonith-enabled=false
##因为在这里我们还没有对fence进行配置,先将stonith-enabled 设置为 false,表示资源不会迁移
crm(live)configure# commit
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.66.100 cidr_netmask=32 op monitor interval=30s
##添加vip资源,params 指定参数 op monitor 监控配置,interval指定执行操作的频率,单位:秒
crm(live)configure# commit ##提交
[root@server2 ~]# crm node standby
Node server2: standby ##此时server2的状态为standby
Online: [ server3 ]
vip (ocf::heartbeat:IPaddr2): Started server3
[root@server3 ~]# ip addr ##server3接管了vip
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:c7:a3:48 brd ff:ff:ff:ff:ff:ff
inet 172.25.66.3/24 brd 172.25.66.255 scope global eth0
inet 172.25.66.100/32 brd 172.25.66.255 scope global eth0
inet6 fe80::5054:ff:fec7:a348/64 scope link
valid_lft forever preferred_lft forever
[root@server2 ~]# crm node online
##在这里要注意,当另一个节点online后,节点间不会进行回切,这样避免了因资源接管导致的资源丢失
Online: [ server2 server3 ]
vip (ocf::heartbeat:IPaddr2): Started server3
如果是两个节点的集群,应该设置no-quorum-policy为ignore,如果一个节点down掉,另一个节点仍能正常运行。
[root@server2 ~]# /etc/init.d/corosync stop
Signaling Corosync Cluster Engine (corosync) to terminate: [ OK ]
Waiting for corosync services to unload:.. [ OK ]
## 由于我们的corosync默认是启用stonith功能的,但是我们这里没有stonith设备,如果我们直接去配置资源的话,由于没有stonith功能,所以资源的切换并不会完成,所以要禁用stonith功能,现在我们的环境no-quorum-policy没有设置为ignore,在这种情况下,如果一个节点down掉,这个集群就无法正常工作,因为默认对集群有健康检查,如果节点数小于2,便认为无法组成集群,该集群也就无法工作了。
Online: [ server3 ]
[root@server2 ~]# crm
crm(live)# configure
crm(live)configure# property no-quorum-policy=ignore
##我们在这里重新设置为ignore做实验,这时即使一个节点挂掉了,另一个节点也会正常工作
crm(live)configure# commit
crm(live)configure# show
node server2 \
attributes standby="off"
node server3
primitive vip ocf:heartbeat:IPaddr2 \
params ip="172.25.66.100" cidr_netmask="32" \
op monitor interval="30s"
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore"
[root@server2 ~]# /etc/init.d/corosync stop
Signaling Corosync Cluster Engine (corosync) to terminate: [ OK ]
Waiting for corosync services to unload:. [ OK ]
Online: [ server3 ]
OFFLINE: [ server2 ]
vip (ocf::heartbeat:IPaddr2): Started server3
一.基础知识
1.pacemaker
pacemaker是一个开源的高可用资源管理器(CRM),位于HA集群架构中资源管理、资源代理(RA)这个层次,它不能提供底层心跳信息传递的功能,要想与对方节点通信需要借助底层的心跳传递服务,将信息通告给对方。(作为通信层和提供关系管理服务,心跳引擎,检测心跳信息)
2.Corosync
Corosync是集群管理套件的一部分,它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。
二.配置 server2和server3
1.yum源 server2和server3的yum源相同
[root@server3 ~]# vim /etc/yum.repos.d/rhel-source.repo
[rhel-source]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
baseurl=http://172.25.66.250/rhel6.5
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.66.250/rhel6.5/HighAvailability
gpgcheck=0
[LoadBalancer]
name=LoadBalancer
baseurl=http://172.25.66.250/rhel6.5/LoadBalancer
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.66.250/rhel6.5/ResilientStorage
gpgcheck=0
[ScalableFileSystem]
name=ScalableFileSystem
baseurl=http://172.25.66.250/rhel6.5/ScalableFileSystem
gpgcheck=0
2.节点配置
server2
[root@server2 ~]# yum install -y pacemaker corosync
[root@server2 ~]# cd /etc/corosync/
[root@server2 corosync]# ls
corosync.conf corosync.conf.example.udpu uidgid.d
corosync.conf.example service.d
[root@server2 corosync]# cp corosync.conf.example corosync.conf
[root@server2 corosync]# vim corosync.conf ##corosync的配置文件
1 # Please read the corosync.conf.5 manual page
2 compatibility: whitetank ##兼容0.8以前的版本
3
4 totem {
##totem定义集群内各节点间是怎么通信的,totem本是一种协议,专用于corosync专用于各节点间的协议
5 version: 2 ##totem的版本,不可更改
6 secauth: off ##安全认证
7 threads: 0 ##用于安全认证开启的并线程数
8 interface {
9 ringnumber: 0 ##回环号码
10 bindnetaddr: 172.25.66.0
##绑定心跳网段,corosync会自动判断本地网卡上配置的哪个ip地址是属于这个网络的,并把这个接口作为多播心跳信息传递的接口
11 mcastaddr: 226.94.1.1
##心跳信息组播地址,每个节点的组播地址必须为同一个
12 mcastport: 5405 ##组播时使用的端口
13 ttl: 1
##只向外一跳心跳信息,避免组播报文回路
14 }
15 }
16
17 logging {
18 fileline: off ##指定要打印的行
19 to_stderr: no ##日志信息是否发往错误输出(默认否)
20 to_logfile: yes ##是否记录日志文件
21 to_syslog: yes
##是否记录于syslog日志-->此类日志记录于/var/log/message中
22 logfile: /var/log/cluster/corosync.log ##日志存放位置
23 debug: off
##只要不是为了排错,最好关闭debug,它记录的信息过于详细,会占用大量的磁盘IO.
24 timestamp: on
##是否打印时间戳,利于定位错误,但会产生大量系统调用,消耗CPU资源
25 logger_subsys {
26 subsys: AMF
27 debug: off
28 }
29 }
30
31 amf {
32 mode: disabled
33 }
##如果想让pacemaker在corosync中以插件方式启动,需要 在corosync.conf文件中加上如下内容:
34 service {
35 name: pacemaker ## 模块名,启动corosync时同时启动pacemaker
36 ver: 0
37 }
[root@server2 corosync]# scp corosync.conf server3:/etc/corosync/##server3与server2配置相同
[root@server2 corosync]# /etc/init.d/corosync start
[root@server2 corosync]# tail -f /var/log/cluster/corosync.log ##开启服务后查看日志,确定服务配置没有错误
Jul 30 23:27:53 [2403] server2 pengine: info: determine_online_status_fencing: Node server3 is active
Jul 30 23:27:53 [2403] server2 pengine: info: determine_online_status: Node server3 is online
Jul 30 23:27:53 [2403] server2 pengine: notice: stage6: Delaying fencing operations until there are resources to manage
Jul 30 23:27:53 [2403] server2 pengine: notice: process_pe_message: Calculated Transition 6: /var/lib/pacemaker/pengine/pe-input-3.bz2
Jul 30 23:27:53 [2403] server2 pengine: notice: process_pe_message: Configuration ERRORs found during PE processing. Please run "crm_verify -L" to identify issues.
[root@server3 ~]# yum install -y pacemaker corosync
[root@server3 ~]# /etc/init.d/corosync start
Starting Corosync Cluster Engine (corosync): [ OK ]
[root@server2 corosync]# yum install -y crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm
[root@server3 corosync]# yum install -y crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm ##安装crm shell
• 关于crm shell的使用
---crm可以显示并修改配置文件
---直接执行crm命令进行交互式修改配置文件,交互式输入的内容被记 录在配置文件中
---show 显示配置文件
---commit提交
---如果添加资源时出错,首先进入resource,将添加的资源stop,然后进 入cofigure,delete添加错误的资源
[root@server2 ~]# crm ##crm命令进入交互式shell
crm(live)# configure ##进入configure,执行show我们就可以看到配置文件的内容
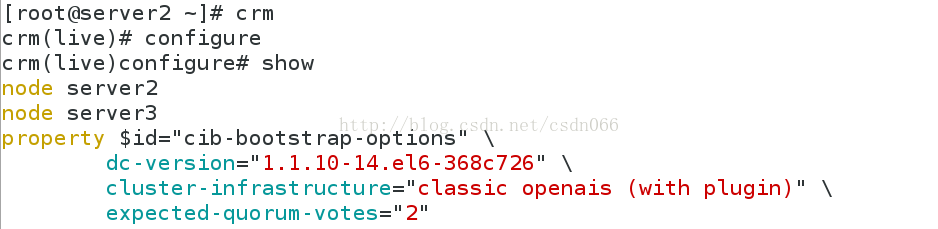
crm(live)configure# show
node server2
node server3
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2"
这里简单介绍在添加资源时命令写错的解决方法
[root@server2 ~]# crm ##在添加ivp时将ip地址写错了crm(live)# resource ##先进入资源——resource
crm(live)resource# ##table我们可以看到在这里可以进行的操作
? failcount param show unmove
bye help promote start untrace
cd list quit status up
cleanup manage refresh stop utilization
demote meta reprobe trace
end migrate restart unmanage
exit move secret unmigrate
crm(live)resource# stop vip ##首先停掉资源,当资源在使用时是无法对他进行改动的
crm(live)resource# delete vip ##但是不能在这里delete,会报错语法错误
ERROR: syntax: delete vip
[root@server2 ~]# crm
crm(live)# configure ##进入configure执行delete
crm(live)configure# delete vip
crm(live)configure# commit ##删除后一定要提交,接下来就可以重新进行配置了
crm(live)configure# bye
[root@server2 ~]# crm
crm(live)# configure
crm(live)configure# property stonith-enabled=false
##因为在这里我们还没有对fence进行配置,先将stonith-enabled 设置为 false,表示资源不会迁移
crm(live)configure# commit
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.66.100 cidr_netmask=32 op monitor interval=30s
##添加vip资源,params 指定参数 op monitor 监控配置,interval指定执行操作的频率,单位:秒
crm(live)configure# commit ##提交
crm(live)configure# bye

[root@server3 ~]# crm_mon ##在server上执行该命令监控节点状态的变化

[root@server2 ~]# crm node standby
##将所有资源从节点上移走,执行此命令后我们会看到,server3接替了server2的工作

Node server2: standby ##此时server2的状态为standby
Online: [ server3 ]
vip (ocf::heartbeat:IPaddr2): Started server3
[root@server3 ~]# ip addr ##server3接管了vip
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:c7:a3:48 brd ff:ff:ff:ff:ff:ff
inet 172.25.66.3/24 brd 172.25.66.255 scope global eth0
inet 172.25.66.100/32 brd 172.25.66.255 scope global eth0
inet6 fe80::5054:ff:fec7:a348/64 scope link
valid_lft forever preferred_lft forever
[root@server2 ~]# crm node online
##在这里要注意,当另一个节点online后,节点间不会进行回切,这样避免了因资源接管导致的资源丢失
Online: [ server2 server3 ]
vip (ocf::heartbeat:IPaddr2): Started server3
如果是两个节点的集群,应该设置no-quorum-policy为ignore,如果一个节点down掉,另一个节点仍能正常运行。
[root@server2 ~]# /etc/init.d/corosync stop
Signaling Corosync Cluster Engine (corosync) to terminate: [ OK ]
Waiting for corosync services to unload:.. [ OK ]
## 由于我们的corosync默认是启用stonith功能的,但是我们这里没有stonith设备,如果我们直接去配置资源的话,由于没有stonith功能,所以资源的切换并不会完成,所以要禁用stonith功能,现在我们的环境no-quorum-policy没有设置为ignore,在这种情况下,如果一个节点down掉,这个集群就无法正常工作,因为默认对集群有健康检查,如果节点数小于2,便认为无法组成集群,该集群也就无法工作了。
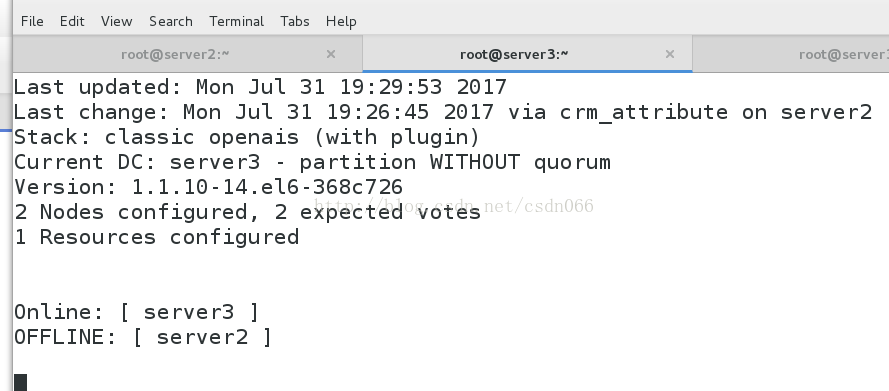
Online: [ server3 ]
OFFLINE: [ server2 ]
[root@server2 ~]# crm
crm(live)# configure
crm(live)configure# property no-quorum-policy=ignore
##我们在这里重新设置为ignore做实验,这时即使一个节点挂掉了,另一个节点也会正常工作
crm(live)configure# commit
crm(live)configure# show
node server2 \
attributes standby="off"
node server3
primitive vip ocf:heartbeat:IPaddr2 \
params ip="172.25.66.100" cidr_netmask="32" \
op monitor interval="30s"
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore"
[root@server2 ~]# /etc/init.d/corosync stop
Signaling Corosync Cluster Engine (corosync) to terminate: [ OK ]
Waiting for corosync services to unload:. [ OK ]
Online: [ server3 ]
OFFLINE: [ server2 ]
vip (ocf::heartbeat:IPaddr2): Started server3

















 719
719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









