






数据预处理
NWPU VHR-10 数据集可从网上下载,其中有三个文件夹,ground truth、negative image set、positive image set
positive image set中有650张图片,这些图片都是至少含有一个目标的,它们的目标信息存放在ground truth文件中。而negative image set中存放了150张无目标图片。我们需对数据进行预处理,将其转化为与voc类似的数据集文件结构。
voc文件格式简单介绍:包含文件annotations存放图片信息、images存放训练图片、ImageSets存放图片训练信息。
将negative image set、positive image set内图片重新进行顺序编号为000001.jpg-000800.jpg,positive image set内图片为000001.jpg-000650.jpg,negative image set内图片为000651.jpg-000800.jpg,然后存放在image文件夹内。
数据集的annotations文件夹内的标注信息xml文件格式相同的xml文件。因为negative image set内图片无对应标注信息,所以只生成包含图片大小的xml文件。
ImageSets文件夹内划分为train.txt、val.txt、trainval.txt、test.txt四个文件,train代表训练集信息,val代表验证集信息,trainval代表训练集和验证集合并的数据信息,test代表测试集信息。
yolov5训练
yolov5源码可从GitHub上下载,源码中的requirements.txt文件是运行时所需的包。将之前预处理的数据放入源码中打他文件夹对应的文件内。
在data文件夹内创建mydata.yaml文件,内容如下:
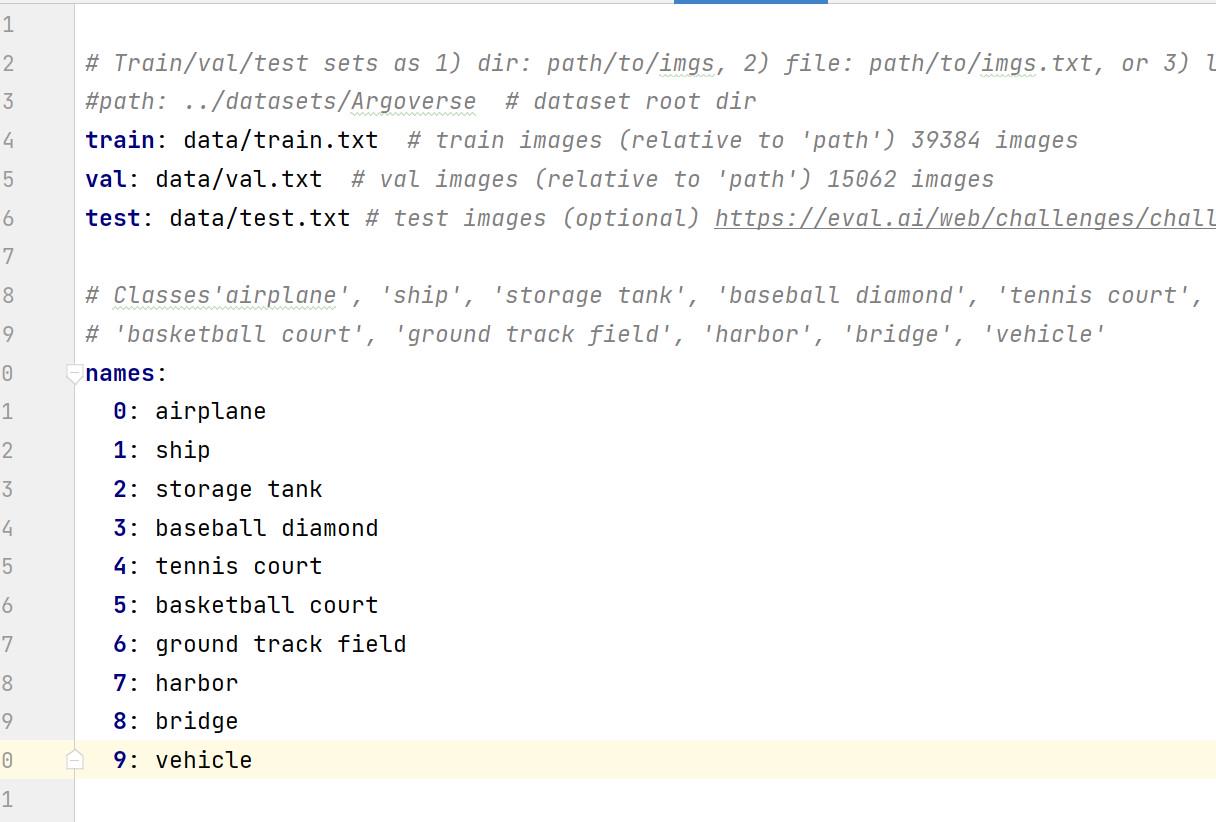
train、val、test是对应文件存储路径,names是NWPU VHR-10数据集包含的十种类别名称。
打开源码中train.py,找到parse_opt函数(大概在430行左右)修改代码:
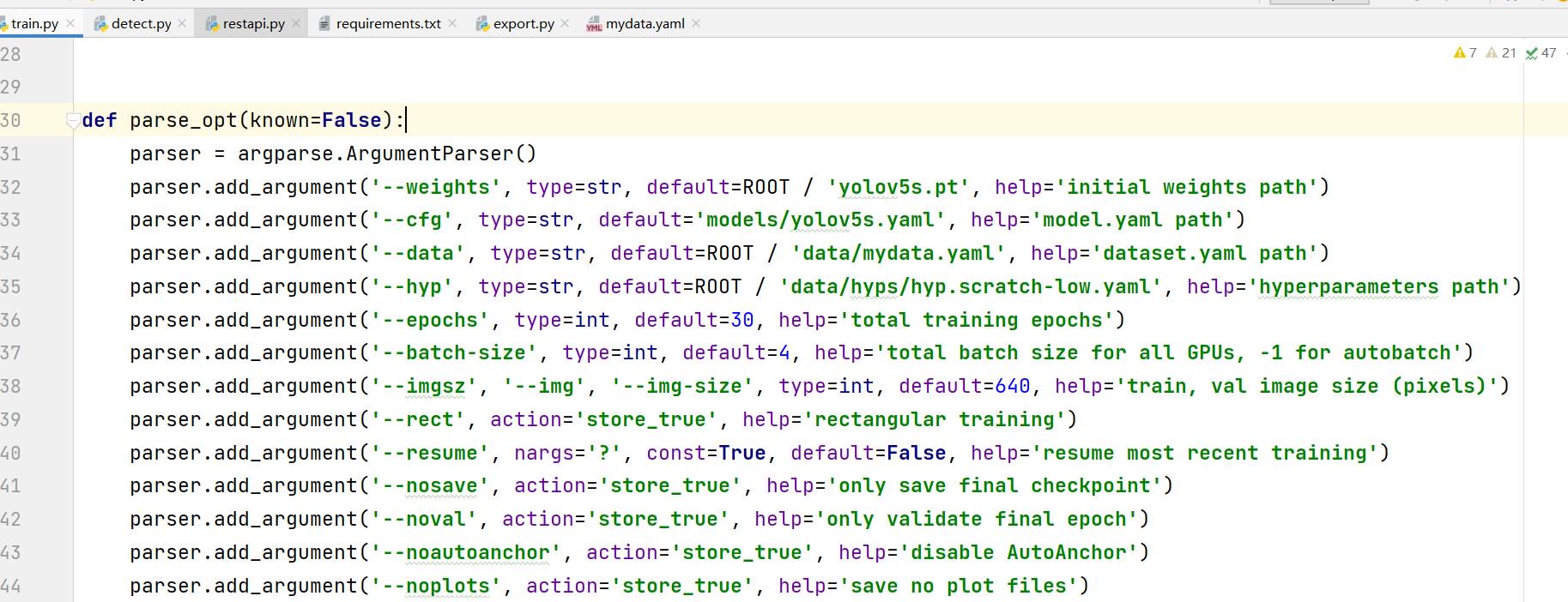
weights后参数代表所使用模型,我使用的是yolov5s模型。cfg代表使用模型信息,需与使用模型保持一致。data代表使用数据集信息,改为mydata.yaml。epochs代表训练次数,根据自己需求和电脑配置更改。batch-size根据需求设置,更改参数后运行程序,运行结果在源码中的runs/train文件夹中。















 3253
3253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









