






前言
众所周知啊,新手一般是最爱记录的
这篇文章的主要目的是想自己熟练一下YoloV8的训练、预测过程
采用的数据集是:NWPU VHR-10数据集
一、数据集及数据集处理
NWPU VHR-10 (Cheng et al.,2016) 这个高分辨率(VHR)遥感图像数据集是由西北工业大学(NWPU)构建的,包含10类正例样本650张以及不包含给定对象类的任何目标的150张反例图像(背景),正例图像中至少包含1个实例,总共有3651个目标实例。具体类别信息如下:
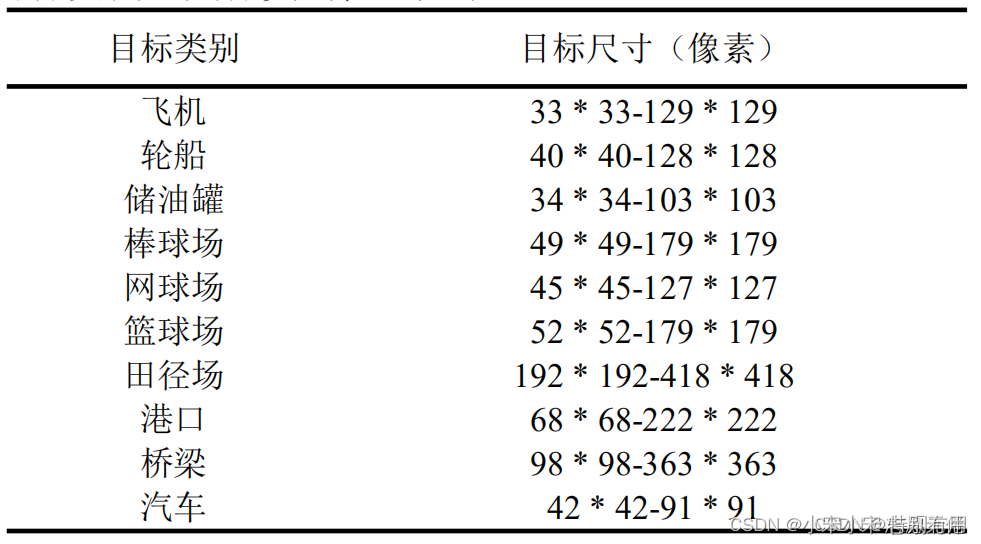
具体相信内容可以看https://blog.csdn.net/weixin_43427721/article/details/122057389,毕竟是从人家那里下载的数据…
NWPU VHR-10采用HBB的标注方法。ground truth文件夹包含650个单独的txt文件,每个文件对应于positive image set文件夹中的一个图像,这些文本文件的每一行都定义了一个ground truth边界框,格式如下:
(x1,y1),(x2,y2),a
其中(x1,y1)为bounding box的左上角坐标,(x2,y2)为bounding box的右下坐标
而我们yolo目标检测所需要的标签坐标格式如下:
<object-class> <x> <y> <width> <height>
x,y是目标的中心坐标,width,height是目标的宽和高。这些坐标是通过归一化的,其中x,width是使用原图的width进行归一化;而y,height是使用原图的height进行归一化。
所以,我们需要进行坐标转换,下面是写了一个坐标转换的代码(代码写得稀碎,改了又改,注释掉的代码可以直接删掉)
import os
import cv2
import re
# 这个函数是用来计算yolo标签的格式的 但是缺少一些东西 需要先计算得到size和box
# size是原图的(w,h)
# box是坐标
def voc_to_yolo(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
# print(x,y,w,h)
x = '%.6f' % x
y = '%.6f' % y
w = '%.6f' % w
h = '%.6f' % h
return (x, y, w, h)
# 这个函数是用来提取原始标签文本一行里面的数字
def extract_numbers_from_line(line):
# with open(file_path, 'r') as file:
# content = file.read()
# 使用正则表达式提取所有数字
numbers = re.findall(r"[-+]?\d*\.\d+|\d+", line.strip())
# 将提取的字符串数字转换为整数
numbers = [int(num) for num in numbers]
if len(numbers) == 5:
return numbers
def Dataset(image_dir, ground_dir, label_dir): # img_dir:图片路径 ground_dir:原始标签路径 label_dir:标签存储路径
# 创建一个空列表存储图片路径
images = []
# 创建一个空列表存储原始标签路径
ground = []
# 遍历 images 文件夹下的所有图片
for image_name in os.listdir(image_dir):
image_path = os.path.join(image_dir, image_name) # 完整的图像路径
ext = os.path.splitext(image_name)[-1] # 获取图像的扩展名
ground_name = image_name.replace(ext, '.txt') # 获取原始标签的文件名
ground_path = os.path.join(ground_dir, ground_name)
label_path = os.path.join(label_dir, ground_name)
# 现在就获得了图片和原始标签
# 处理图像,获得图像的大小尺寸
image = cv2.imread(image_path)
size = image.shape
# 获取到图像大小
w0 = size[1] # 宽度
h0 = size[0] # 高度
# 打开原始便签文本
with open(ground_path, 'r') as file:
# 获取行数
lines = file.readlines()
# 循环处理每一行
# print(lines)
for line in lines:
try:
line.replace(" ", "").replace("\n", "")
x1, y1, x2, y2, la = extract_numbers_from_line(line)
# x, y, w, h= voc_to_yolo([w, h], [x1, x2, y1, y2])
# print(voc_to_yolo([w0, h0], [x1, x2, y1, y2]))
x = float(voc_to_yolo([w0, h0], [x1, x2, y1, y2])[0])
y = float(voc_to_yolo([w0, h0], [x1, x2, y1, y2])[1])
w = float(voc_to_yolo([w0, h0], [x1, x2, y1, y2])[2])
h = float(voc_to_yolo([w0, h0], [x1, x2, y1, y2])[3])
la = la - 1
print(la, x, y, w, h)
# print(label_path)
# 保存到新的标签(适用于yolo检测的标签
# 创建一个文件
label_name = open(label_path, "a")
# 写入
label_name.write(f"{la} {x} {y} {w} {h}\n")
# label_name.close()
except ValueError as ve:
print(ve)
print(label_path)
print("写入完成\n")
Dataset('images', 'ground truth', 'labels')
代码参考这位博主:https://blog.csdn.net/KD_LW/article/details/112918173
然后就可以将
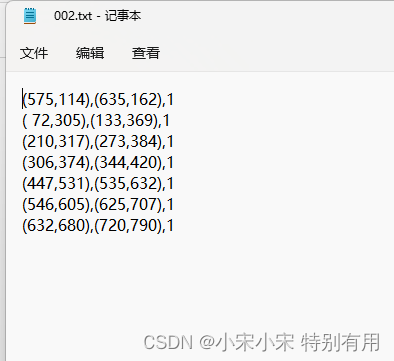
变成

这里还有一个任务,因为拿到的数据集有正负两个样本,我想着把负样本也加入到训练中,但是负样本的文件名也是从001.jpg开始的,所以需要将所有负样本的文件名+650,再生成对应的空的.txt作为标签加入到训练中。
'''
用来负样本加入到数据中,并生成对应的空.txt标签
'''
import os
import shutil
from tqdm import tqdm
def MergeData(image_dir,): # img_dir:负样本图片路径
# 创建一个空列表存储图片路径
images = []
# 创建一个空列表存储原始标签路径
labels = []
# 遍历 images 文件夹下的所有图片
for image_name in os.listdir(image_dir):
# 获取图片完整路径
image_path = os.path.join(image_dir, image_name)
# 获取图片文件的名字
name = os.path.splitext(image_name)[0]
# print(ext)
name_int = int(name)
# print(name+650)
# 文件名+650
image_name = image_name.replace(name, str(name_int+650))
# 新的文件名
new_path = os.path.join(image_dir, image_name)
# 重命名操作
os.rename(image_path, new_path)
# print(image_name)
# print(ext)
# 获取图片文件的扩展名
ext = os.path.splitext(image_name)[-1]
# 根据扩展名替换成对应的label文件
label_name = image_name.replace(ext, '.txt')
# print(label_name)
# 获取对应label的完整路径
label_path = os.path.join(image_dir, label_name)
# 创建空.txt标签文本
f = open(label_path, "x")
# 将图片添加到列表中
images.append(new_path)
# 讲标签添加到列表中
labels.append(label_path)
# 该进行移动操作了
# 遍历每个有效的图片路径
for i in tqdm(range(len(images))):
image_path = images[i]
label_path = labels[i]
image_destination_path = os.path.join("images",os.path.basename(image_path))
# 移动过去
shutil.copy(image_path, image_destination_path)
label_destination_path = os.path.join("labels", os.path.basename(label_path))
# 移动过去
shutil.copy(label_path, label_destination_path)
MergeData("negative image")
二、数据集划分及配置文件的修改
2.1 数据集划分
将数据集按照train:vaild:test = 7:2:1的比例进行划分。
代码如下:
"""
此文件划分数据集
"""
import os
import random
from tqdm import tqdm
import shutil
def CollatDataset(image_dir, label_dir): # img_dir:图片路径 label_dir:标签路径
# 创建一个空列表存储图片路径
imges = []
# 创建一个空列表存储labels路径
labels = []
# 遍历 images 文件夹下的所有图片
for image_name in os.listdir(image_dir):
# 获取图片完整路径
image_path = os.path.join(image_dir, image_name)
# 获取图片文件的扩展名
ext = os.path.splitext(image_name)[-1]
# 根据扩展名替换成对应的label文件
label_name = image_name.replace(ext, '.txt')
# 获取对应label的完整路径
label_path = os.path.join(label_dir, label_name)
# 判断label是否存在
if not os.path.exists(label_path):
print(label_path, "没有")
else:
# 将图片添加到列表中
imges.append(image_path)
# 讲标签添加到列表中
labels.append(label_path)
# 遍历每个有效的图片路径
for i in tqdm(range(len(imges))):
image_path = imges[i]
label_path = labels[i]
# 随机生成一个概率
r = random.random()
print(r)
# 判断图片应该移动到哪个文件夹
# train:vaild:test = 7:2:1
if r < 0.1 :
destination = "test"
elif 0.1 <= r < 0.3:
# 移动到vail文件
destination = "vaild"
else:
# 移动到train文件
destination = "train"
# 创建目标文件夹中images和labels子文件
os.makedirs(os.path.join(destination, "images"), exist_ok=True)
os.makedirs(os.path.join(destination, "labels"), exist_ok=True)
# 生成目标文件夹中图片的新路径
image_destination_path = os.path.join(destination, "images", os.path.basename(image_path))
# 移动过去
shutil.copy(image_path, image_destination_path)
# 生成目标文件夹中label的新路径
label_destination_path = os.path.join(destination, "labels", os.path.basename(label_path))
# 移动过去
shutil.copy(label_path, label_destination_path)
if __name__ == '__main__':
CollatDataset("./images", "./labels")

OK!现在前期准备工作做完了,该进入到关键部分了
2.2 配置文件修改
我们从ultralytics的代码中,可以看到cfg的一个文件夹。
这个文件夹就是存放我们训练所需的数据和模型的配置文件,default.yaml的默认的配置文件。
我们要做的就是在自己的项目中,创建同样的数据和模型配置文件。(写到这发现自己忘记创建项目了。。。
创建一个项目,就叫remote_sensing吧,然后把数据放进去。
其实我觉这里觉得这个模型配置文件yolov8_remote.yaml是没有用的,删了就行
data_remote.yaml配置文件内容如下:
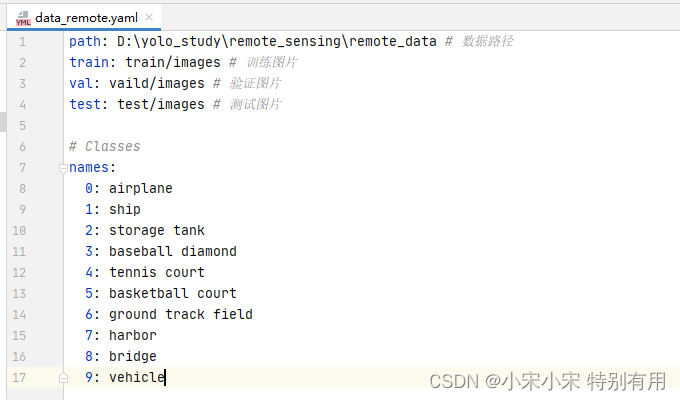
OK!保存好,继续下一步。
三、训练
关于这个ultralytics工具包的下载,我最开始是直接在GitHub上下载的源码进行使用
后来发现,直接在终端进行pip install ultralytics也可以。
直接在PyCharm的terminal输入
pip install ultralytics
创建一个train.py文件
代码如下:
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO("yolov8n.pt")
model.train(data="./cfg/data_remote.yaml", epochs=30)
result = model.val()
关于YOLO里面的模型选择,有n、s、m、l、x五种选择。
train的参数选择,可以参考ultralytics工具包下caf里的default.yaml文件
运行train.py,开始训练。
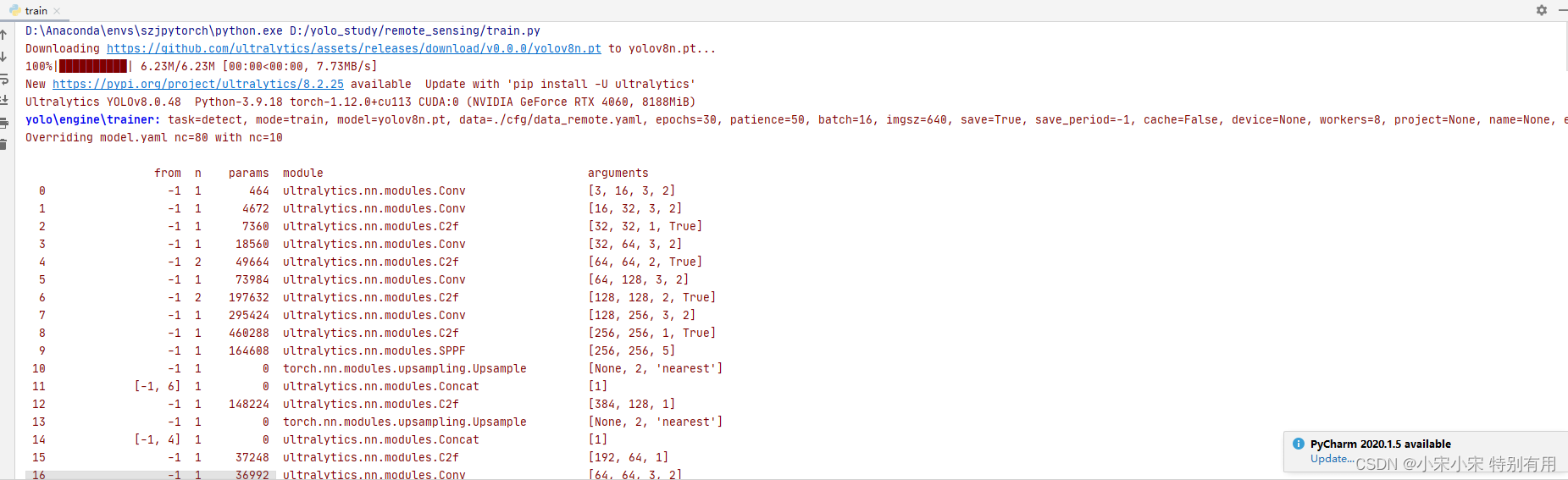
训练后可以看到结果的一些参数评估。
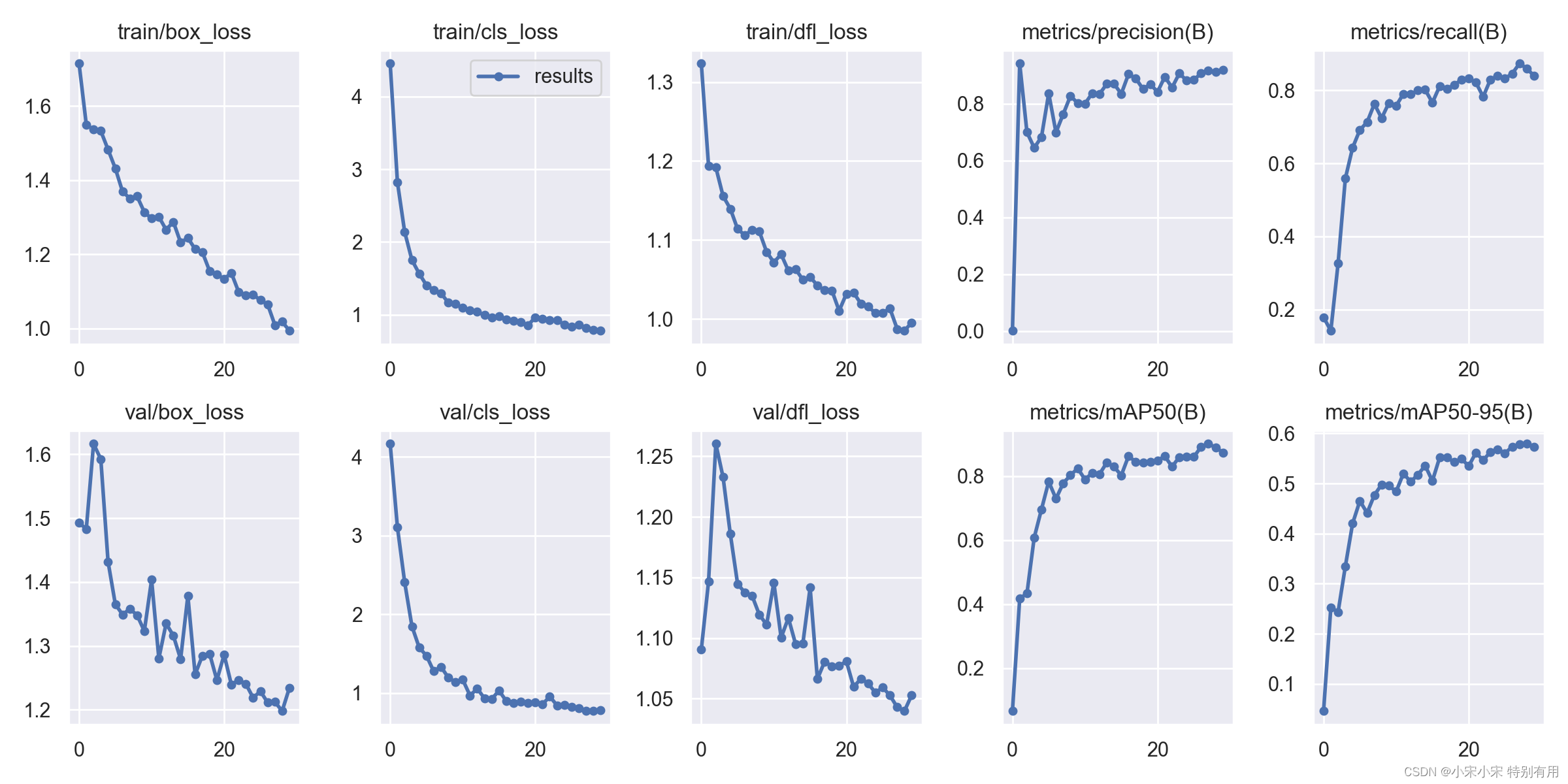
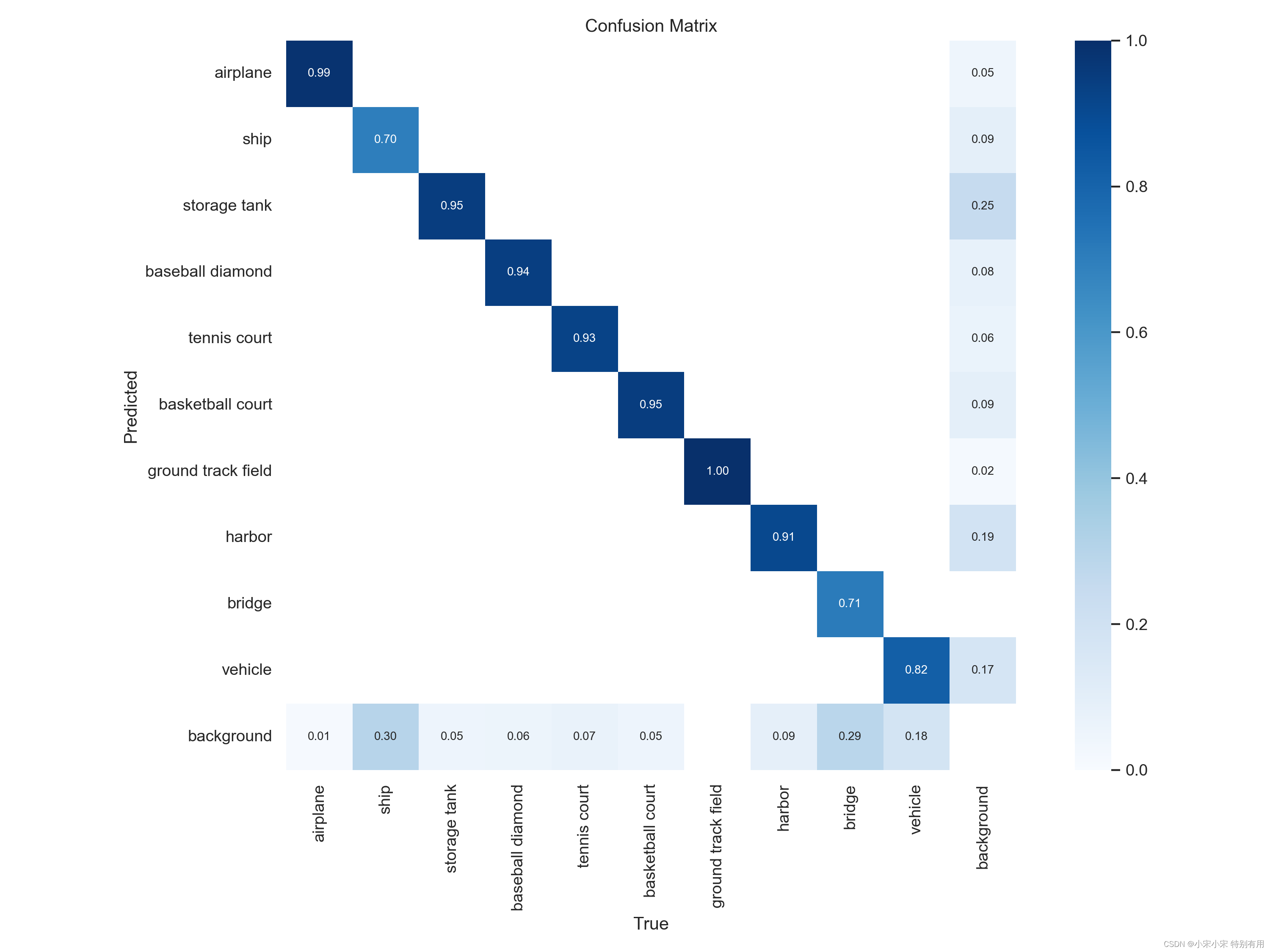
四、预测推理
创建一个predict.py的python文件,代码如下:
from ultralytics import YOLO
from PIL import Image
model = YOLO("./runs/detect/train/weights/best.pt") # 训练好的模型路径
img = Image.open("./remote_data/test/images/490.jpg") # 要预测的图像路径
results = model.predict(source=img, show=True, save=True, save_txt=True) # 展示并保存绘制的图像和坐标
预测结果如下:

总结
以上就是今天要讲的内容,本文仅仅简单介绍了Yolov8的训练过程,详细的模型架构包括代码含义啥的我确实不会。
写文章仅仅是为了记录学习过程,如果被认为有抄袭,侵权等行为,私信我一秒修改。
本人纯小白,所以可能写的很肤浅。
后续学习一下如何做可视化的qt界面,并连接一下本地摄像头。

















 3073
3073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









