










定义
public class ConcurrentHashMap<K,V>
extendsAbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable
支持获取的完全并发和更新的所期望可调整并发的哈希表。此类遵守与 Hashtable相同的功能规范,并且包括对应于Hashtable的每个方法的方法版本。不过,尽管所有操作都是线程安全的,但获取操作不必锁定,并且不支持以某种防止所有访问的方式锁定整个表。此类可以通过程序完全与Hashtable进行互操作,这取决于其线程安全,而与其同步细节无关。
获取操作(包括get)通常不会受阻塞,因此,可能与更新操作交迭(包括put和remove)。获取会影响最近完成的更新操作的结果。对于一些聚合操作,比如putAll和 clear,并发获取可能只影响某些条目的插入和移除。类似地,在创建迭代器/枚举时或自此之后,Iterators和Enumerations返回在某一时间点上影响哈希表状态的元素。它们不会抛出ConcurrentModificationException。不过,迭代器被设计成每次仅由一个线程使用。
这允许通过可选的concurrencyLevel构造方法参数(默认值为16)来引导更新操作之间的并发,该参数用作内部调整大小的一个提示。表是在内部进行分区的,试图允许指示无争用并发更新的数量。因为哈希表中的位置基本上是随意的,所以实际的并发将各不相同。理想情况下,应该选择一个尽可能多地容纳并发修改该表的线程的值。使用一个比所需要的值高很多的值可能会浪费空间和时间,而使用一个显然低很多的值可能导致线程争用。对数量级估计过高或估计过低通常都会带来非常显著的影响。当仅有一个线程将执行修改操作,而其他所有线程都只是执行读取操作时,才认为某个值是合适的。此外,重新调整此类或其他任何种类哈希表的大小都是一个相对较慢的操作,因此,在可能的时候,提供构造方法中期望表大小的估计值是一个好主意。
此类及其视图和迭代器实现了Map和Iterator接口的所有可选方法。此类与Hashtable相似,但与HashMap不同,它不允许将null用作键或值。
深入解析
线程不安全的HashMap:因为多线程环境下,使用Hashmap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
效率低下的Hashtable:Hashtable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下Hashtable的效率非常低下。因为当一个线程访问Hashtable的同步方法时,其他线程访问Hashtable的同步方法,就可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
ConcurrentHashMap的分段锁技术:Hashtable容器在竞争激烈的并发环境下表现出效率低下的原因,是因为所有访问Hashtable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成(Segment、HashEntry都是ConcurrentHashMap的内部类)。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构,一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
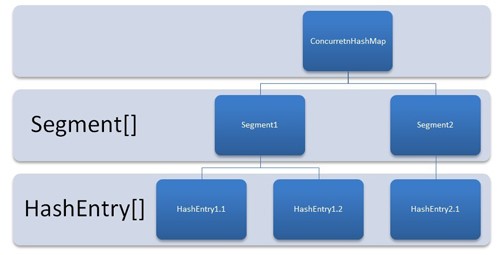
具体可以理解为把一个大的Map拆分成N个小的Hashtable,根据key.hashCode()来决定把key放到哪个Hashtable中。在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中:
/**
* Returns the segment that shouldbe used for key with given hash
* @param hash the hash code for the key
* @return the segment
*/
final Segment<K,V> segmentFor(int hash) {
return segments[(hash>>> segmentShift)& segmentMask];
}/**
* Returns the value to which thespecified key is mapped,
* or {@code null} if this mapcontains no mapping for the key.
*
* <p>More formally, if this map contains amapping from a key
* {@code k} to a value {@code v}such that {@code key.equals(k)},
* then this method returns {@codev}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @throws NullPointerException if thespecified key is null
*/
public V get(Object key){
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}/**
* Maps the specified key to thespecified value in this table.
* Neither the key nor the valuecan be null.
*
* <p> The value can be retrieved by calling the <tt>get</tt> method
* with a key that is equal to theoriginal key.
*
* @param key key with which the specified value isto be associated
* @param value value to be associated with thespecified key
* @return the previous value associatedwith <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>
* @throws NullPointerException if thespecified key or value is null
*/
public V put(K key,V value){
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value,false);
}初始化
下面是ConcurrentHashMap的数据成员:
public classConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>,Serializable {
private static final long serialVersionUID= 7249069246763182397L;
/*
* The basic strategy is to subdivide thetable among Segments,
* each of which itself is a concurrentlyreadable hash table.
*/
/* ---------------- Constants-------------- */
/**
* The default initial capacity for thistable,
* used when not otherwise specified in aconstructor.
*/
static final int DEFAULT_INITIAL_CAPACITY= 16;
/**
* The default load factor for this table,used when not
* otherwise specified in a constructor.
*/
static final float DEFAULT_LOAD_FACTOR= 0.75f;
/**
* The default concurrency level for thistable, used when not
* otherwise specified in a constructor.
*/
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
/* ---------------- Fields -------------- */
/**
* Mask value for indexing into segments.The upper bits of a
* key's hash code are used to choose thesegment.
*/
final int segmentMask;
/**
* Shift value for indexing withinsegments.
*/
final int segmentShift;
/**
* The segments, each of which is aspecialized hash table
*/
final Segment<K,V>[] segments;
}所有的成员都是final的,其中segmentMask和segmentShift主要是为了定位段,参见上面的segmentFor方法。每个Segment相当于一个子Hash表。
ConcurrentHashMap的构造函数:
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw newIllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel){
++sshift;
ssize <<= 1;
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1;
this.segments = Segment.newArray(ssize);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity/ ssize;
if (c * ssize< initialCapacity)
++c;
int cap = 1;
while (cap < c)
cap <<= 1;
for (int i = 0; i < this.segments.length; ++i)
// 这里的Segment其实就相当于Hashtable
this.segments[i] = new Segment<K,V>(cap, loadFactor);
}由上面的代码可知segments数组的长度ssize通过concurrencyLevel计算得出。为了能通过按位与的哈希算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方(power-of-two size),所以必须计算出一个是大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度。假如concurrencyLevel等于14,15或16,ssize都会等于16,即容器里锁的个数也是16。注意concurrencyLevel的最大大小是65535,意味着segments数组的长度最大为65536,对应的二进制是16位。
初始化segmentShift和segmentMask。这两个全局变量在定位segment时的哈希算法里需要使用,sshift等于ssize从1向左移位的次数,在默认情况下concurrencyLevel等于16,1需要向左移位移动4次,所以sshift等于4。segmentShift用于定位参与hash运算的位数,segmentShift等于32减sshift,所以等于28,这里之所以用32是因为ConcurrentHashMap里的hash()方法输出的最大数是32位的。segmentMask是哈希运算的掩码,等于ssize减1,即15,掩码的二进制各个位的值都是1。因为ssize的最大长度是65536,所以segmentShift最大值是16,segmentMask最大值是65535,对应的二进制是16位,每个位都是1。
初始化每个Segment。输入参数initialCapacity是ConcurrentHashMap的初始化容量,loadfactor是每个segment的负载因子,在构造方法里需要通过这两个参数来初始化数组中的每个segment。
上面代码中的变量cap就是segment里HashEntry数组的长度,它等于initialCapacity除以ssize的倍数c,如果c大于1,就会取大于等于c的2的N次方值,所以cap不是1,就是2的N次方。segment的容量threshold=(int)cap*loadFactor,默认情况下initialCapacity等于16,loadfactor等于0.75,通过运算cap等于1,threshold等于零。
get操作
get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空的才会加锁重读,我们知道HashTable容器的get方法是需要加锁的,那么ConcurrentHashMap的get操作是如何做到不加锁的呢?原因是它的get方法里将要使用的共享变量都定义成volatile,如用于统计当前Segement大小的count字段和用于存储值的HashEntry的value。定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值),在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。之所以不会读到过期的值,是根据java内存模型的happen before原则,对volatile字段的写入操作先于读操作,即使两个线程同时修改和获取volatile变量,get操作也能拿到最新的值,这是用volatile替换锁的经典应用场景。
put操作
由于put方法里需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必须得加锁。Put方法首先定位到Segment,然后在Segment里进行插入操作。插入操作需要经历两个步骤,第一步判断是否需要对Segment里的HashEntry数组进行扩容,第二步定位添加元素的位置然后放在HashEntry数组里。
是否需要扩容。在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阀值,数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
如何扩容。扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
size操作
如果我们要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小后求和。Segment里的全局变量count是一个volatile变量,那么在多线程场景下,我们是不是直接把所有Segment的count相加就可以得到整个ConcurrentHashMap大小了呢?不是的,虽然相加时可以获取每个Segment的count的最新值,但是拿到之后可能累加前使用的count发生了变化,那么统计结果就不准了。所以最安全的做法,是在统计size的时候把所有Segment的put,remove和clean方法全部锁住,但是这种做法显然非常低效。
因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。
那么ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?使用modCount变量,在put, remove和clean方法里操作元素前都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









