







TJU自然语言处理(6):词汇获取
介绍
- 总体目标:设计一种算法和统计技术,通过对大规模文本语料库的挖掘,获取其中词语出现的各类形式,来填补现有机读词典的不足。
- 俗话来说就是人类不断发明着新词,而字典不可能及时收录,这就需要词汇获取,而词汇获取的任务是扩大传统辞典中所包含的词条的信息,完善词条各方面的属性。
词汇获取的分类

评价方法
Precision (精确率)
Recall (召回率)
F-measure (F测量值)
Fallout (漏识率)

fp:不是正确的,但你选出来了
tp:正确的而且你选出来了
fn:正确的,但没选出来
tn:不是正确的而且没选出来

- 问题:为什么不用系统正确判断所占比例(准确率)来衡量性能呢?
- 答:当tn或者tp数量非常多,以至于不在一个数量级时,会造成算出的准确率差异在小数点后几位才有区别。此时F-measure更加好一点。
动词子范畴
- 定义:动词可以被划分为不同的句法范畴,也就是说,动词可以用不同的句法形式来表示自己的语义对象。我们把根据动词所允许搭配的补足成分的类型(名词短语,介词短语等)对动词进行分类称之为子范畴。我们总是对于某个特定的补足语来谈一个动词的子范畴。
- 子范畴框架:动词可以出现于其中的一个特殊语义论元集即称为一个子范畴框架。例如:动词为Greet,和它一同出现的论元为主语和宾语,都可以看作是名词短语,所以在该句中greet的框架为Np,np。
- 为何称为子范畴:因为如果我们把可以带有某一特定语义论元集合的动词作为一类,那么我们可以通过各种不同的句法形式(syntactic means)来表达这种语义,每一种表达形式都可以称为一个子范畴。例如:
带有语义对象theme(主题)和recipient(受体)的一类动词可以有这样的子范畴,这类动词既可以使用宾语和介词短语来表示他们的语义论元,如donate,又可以使用双宾语结构来表示,每种表示形式都是这类动词的一个子范畴。
学习子范畴框架的算法
两个步骤:暗示(cues),假设检验。
- 暗示:定义了包含词语和句法范畴的正则模式,该正则模式的出现表明某个特定的框架的出现有比较高的确定性。确定性可以形式化为错误概率。对于某个特定的暗示cj,定义错误概率ξj,表示如果在暗示cj的基础上为动词v 指定框架f,那么错误的可能性有多大。
- 假设检验:

附着歧义
分析句子的句法结构时,可能产生附着歧义。比如下面:
介词短语(pp)是依赖于ate 还是 cake
概率模型
为简化问题,只考虑对一个介词构建模型;
事件空间:
由所有符合下列条件的子句组成:包含一个及物动词,有一个在动词之后的名词短语,以及在名词之后的介词短语。
定义两个随机变量指示器
VAp:是否存在一个在动词v后面以p开头的介词短语附着于v(VAp=1)或者不附着于v(VAp=0)?
NAp:是否存在一个在名词n后面以p开头的介词短语附着于n(NAp=1)或者不附着于n(NAp=0)?
-
对于上面两个随机变量:NAp=1时,VAp也可能等于1。而VAp=1时,NAp=0。
-
两个独立假设:(1)介词短语是否修饰动词v和是否修饰名词n是独立的;(2)动词是否被介词短语修饰与名词无关,而名词是否被介词短语修饰也与动词无关。

那么,如何确定C(v,p)C(n,p),同时,也要注意语料库中有可能存在介词短语没有明显歧义的情况。
Hindle和Rooth启发算法
作用:确定C(v,p)C(n,p)
- 计算所有的非歧义情况(如上页中的示例)构建初始模型;
- 将初始模型应用到所有歧义情况中,通过比较 和预先定义的阈值大小,做出相应的附着关系判断。
- 在两种附着关系的计数中,均匀地分配其余的歧义情况。即,对于每一个歧义情况,C(v,p)和C(n,p)各增加0.5。

存在的问题
- 该模型建模时只考虑了v,n,pp,然而现实句子中其它的信息可能对确定pp的依附性也有很大的作用。
- 该模型仅考虑了紧跟在np后面的pp是修饰在其前的np的还是vp的这一基本情况,实际上pp的依附性有很多种情况。
- 复合名词的附着关系(door bell manufacturer,woman aid worker)
选择倾向
大多数的动词都有倾向于带某类论元的性质,我们把这种规律性称之为选择倾向。比喻eat倾向于food类的东西,think的主语一般是人。
选择倾向能进行语义推测,比如词典没有它,但我们能根据选择倾向能大致推出是什么类型的词。
还能排列一个句子可能的句法分析结果。
Resnik提出的模型
该模型可以应用到任何词类的语义约束中:动词和主语、动词和直接宾语、动词和介词短语、形容词和名词、名词和名词等。以动词和直接宾语为例。
两个重要的概念:
选择倾向强度 (SPS):度量了动词约束它的直接宾语的强度。定义为直接宾语的先验分布(普通动词直接宾语的分布)和我们所求的动词直接宾语分布之间的相对熵。 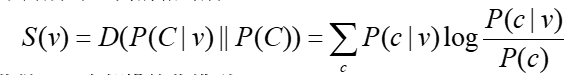
选择关联强度:衡量某个词类和相应动词的关联程度。
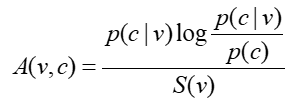
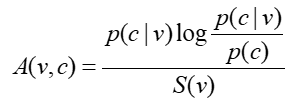
如何指定关联强度和名词(而非名词类)之间的关系:
如果名词只属于一个类,那么A(v,n)=A(v,c)
如果名词不只属于一个类,那么它的关联强度定义为所有类中最大的。

语义相似性
词汇获取的最高目标是词义的获取;但怎样表述词义并为自动系统所用尚未解决。如何计算语义相似性是现实的问题。
对于如何判断词汇的语义相似,可以通过替换上下词来衡量。
语义相似性的应用:
1.词语的泛化,例如还是上节的那个例子,如果我们知道durian和apple,banana,and mango等在语义上很相似,那么我们就可以推断durian也是动词eat可以接的一个比较好的论元。
2.查询扩展,在检索时利用语义相似的的一些次对用户的查询输入进行扩展,可以弥补用户在输入时考虑的不周全。
3.K近邻分类,在k近邻分类中,基本思想就是对于未知样本x取其k个近邻,看这k个近邻中多数属于哪个类就把x归入哪个类。可以通过计算在语义上相近的词来取得样本的k个近邻。
度量方法:向量空间度量方法

X,y表示向量,|x|表示X向量中非零值的个数,|Y|表示y向量中非零值的个数,|x交y|表示x,y中相同值的个数,|x并y|表示x,y中所有不同的非零值的个数的和。



对于实数值的向量情况,cosine的计算方式如下。如果|x|(x的模)为1,则向量x称为正规向量,对于两个正规向量的cosine就等于x与y的点乘。
向量度量法分析
优点:简洁直观,计算简单
缺点:同现信息不能反映词序和语法依存关系,所以这种方法不能反映语法差别(fallen和fell)
度量方法:概率度量方法
为什么引入:基于向量空间的这些方法中,只有cosine可以应用于实数值的向量,其他的都只是针对二值向量 。
cosine的方法也有其自身的问题,就是计算cosine要求的前提是要在欧氏空间下。然而欧氏空间对于以概率值为元素的向量并不是一个好的选择。

之所以称之为dis-similarity,是因为所有的这些方法都是计算出来的值越小说明越相似。
Kl距离(散度)(相对熵)在前面介绍选择偏向(selectional preferrence)的时候介绍过,在这里用来衡量两个概率分布的相似性,公式的基本含义就是如果真实的分布为p,我们假设采用了q分布,那么会有多少信息丢失,丢失的信息越少,两个分布越相似。Kl距离的使用有两个主要的问题,一个是如果qi为0,pi不为0,则的得到的值将为无穷大,然而这种情况是经常出现的,尤其是利用极大似然估计的时候,另一个问题是该测度不是对称的,D(p,q)不等于D(q,p),这与我们对于两个词的语义相似性的直觉是不相符的,如果两个词语义相似那么应该和顺序是无关的。
信息半径Information radius的方法利用了两个分布的平均分布来描述这两个分布,公式中计算利用平均分布描述后共丢失了多少信息量。该方法是对称的,irad(p,q)=irad(q,p),并且没有无穷大值的问题。
L1 norm范式是两个分布的差异的累加,反映了两个分布中不同的部分所占的比重。该方法对于任意的分布p和q都具有对称性。
词汇获取的意义
词汇的获取在统计自然语言处理中起着关键的作用。词汇自动获取具有重要的意义,因为
1.人工构建词汇资源耗费大量的人力、物力,而且人对于超大量信息的收集并不是很擅长。
2.当前许多词汇资源都是面向人类的应用设计的,其中缺失大量进行机器自动处理时需要的信息,毕竟人是有很多先验知识的,而机器没有。而且目前词典资源大多缺乏词条的上下文信息,即时是人也不可能单靠一步双语词典就学会一门语言何况机器。
3.还有一个最重要的原因就是现代语言的多产性,现代语言变化很快,每年都有大量的新词涌现,即时现有的词也会有一些新的意思,新的用法的出现,因此词汇的自动获取是至关重要的。
词汇获取的一个重要的趋势就是努力寻找先验的知识源来约束词汇获取的过程。其中一个重要的知识源就是语言学的理论方面的知识。















 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









