







一、引言
(一)词嵌入技术的研究意义
在自然语言处理(NLP)领域,词嵌入技术通过将离散词语映射为连续语义向量,有效解决了文本数据的高维稀疏问题,为语义计算和语言理解提供了数学化基础。作为词嵌入的代表性方法,Word2Vec 与 GloVe 通过不同机制捕捉词语语义关系,在文本分类、机器翻译等任务中展现出卓越性能,成为当前 NLP 研究的核心技术之一。
(二)研究目标与方法
本文聚焦 Word2Vec 与 GloVe 的技术原理、模型特性及应用效果,通过对比分析揭示两者在语义向量生成机制上的差异,为研究者选择合适模型提供理论依据。结合数学建模与实证分析,系统阐述两种模型如何将语言符号转化为具有语义表征能力的向量空间。
二、Word2Vec 模型原理与架构
(一)分布式假设与神经网络建模
Word2Vec 由 Google 于 2013 年提出 ,基于 “上下文相似的词语语义相近” 这一分布式假设,通过浅层神经网络高效学习词向量,将词语的语义信息转化为低维连续向量空间中的数值表示。这种转化使得计算机能够以数学方式理解和处理自然语言,解决了传统 One-Hot 编码带来的高维稀疏性和语义鸿沟问题 。例如,在 “我喜欢苹果” 和 “我爱吃苹果” 这两个句子中,“喜欢” 和 “爱” 具有相似的上下文,Word2Vec 能将它们映射到相近的向量空间位置,从而捕捉到语义相似性。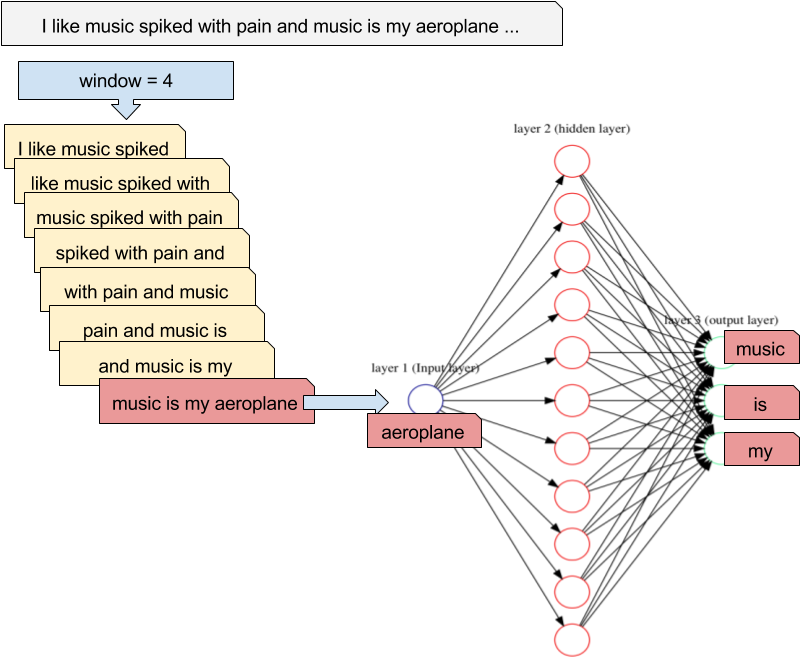
Word2Vec 的核心架构包括连续词袋模型(CBOW)和跳字模型(Skip-Gram)。CBOW 模型旨在通过上下文词向量预测中心词,假设我们有一个句子 “鸟儿在天空飞翔”,当以 “天空” 为中心词时,其上下文词为 “鸟儿”“在”“飞翔” 。模型首先将上下文词的 One-Hot 编码输入嵌入层,通过查找嵌入矩阵得到对应的词向量,再对这些词向量进行平均池化操作,将得到的固定长度向量输入到 Softmax 层,输出中心词在整个词汇表上的概率分布。其目标函数是最大化给定上下文词时中心词出现的条件概率,即:
\( \underset{\theta}{\arg\max}\prod_{t=1}^{T}\log P(w_t|w_{t - c},\cdots,w_{t + c}) \)
其中,\(T\)是语料库中词的总数,\(w_t\)是第\(t\)个词,\(c\)是上下文窗口大小,\(\theta\)是模型参数 。
跳字模型则是反向操作,通过中心词预测上下文词。仍以上述句子为例,当以 “天空” 为中心词时,模型利用中心词 “天空” 的词向量,通过神经网络预测其上下文词 “鸟儿”“在”“飞翔” 的概率分布。跳字模型通过优化中心词对上下文词的联合概率分布来学习词向量,目标函数为:
\( \underset{\theta}{\arg\max}\prod_{t=1}^{T}\prod_{-c\leq j\leq c,j\neq0}\log P(w_{t + j}|w_t) \)
这种模型更关注局部词序信息,在处理长距离依赖和低频词时表现更优,因为它对每个中心词都进行多次预测,能更充分地学习到低频词的语义信息。
(二)高效训练技术
在大规模语料库上训练 Word2Vec 模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









