







数据同步方法主要有全量同步策略、增量同步策略、新增及变化策略、特殊策略
1.全量同步策略
应用场景:
1、首次拿到业务相关数据时且不关心主键的情况下,一般会将全部数据导入到一张表中。
2、针对业务需求: 每日全量,每天存储一份完整数据,作为一个分区。适用于表数据不大,且每天既有新数据插入,也会有旧数据修改的场景。
例如:编码字典表,品牌表,商品分类表,优惠表,活动表,商品表,加购表,SPU表等。
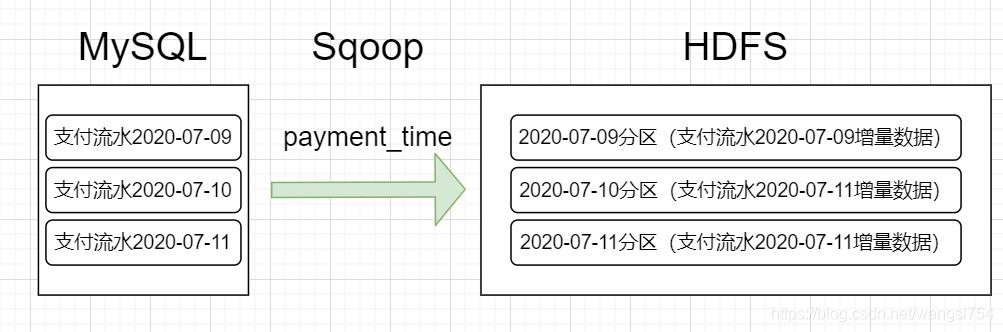
 2、增量同步策略
2、增量同步策略
应用场景:
1、一般在第一次全量建表以后,基本会选择增量同步策略,除非有所有数据需要更新之类的
2、每天存储一份增量数据,作为一个分区。适用于表数据量大,且每天只有新数据插入的场景。例如:退单表,订单状态表,支付流水表,订单详情表,商品评论表等。
 3、新增及变化策略
3、新增及变化策略
每日新增及变化,就是存储创建时间和操作时间都是今天的数据。适用场景为表的数据量大,既会有新增,又会有变化。例如用户表、订单表、优惠券领用表等。
4、特殊策略
1、客观世界维度
没变化的客观世界的维度(比如性别,地区,民族,政治成分,鞋子尺码)可以只存一份固定值。
2、日期维度
日期维度可以一次性导入一年或若干年的数据。
3、地区维度
省份表、地区表。
补充:
关心主键并且只关心部分数据,我们可以使用select查询语句同步数据
a、研发落表,都有主键id——针对MySQL来说
需求:将每天的增量数据与目标数据进行合并,作为下一步开发的原数据
-- 创建临时表,同步过来数据加载到临时表
load data local inpath "文件路径 " overwrite into table tmp
-- 增量数据和目标数据合并:
insert overwrite table target select * from tmp union all select * from target a left join tmp b on a.id=b.id where b.id is null
-- 将临时表删除——节省内存
drop table if exists tmp;
b、比如用户针对一个订单发生多次改派,只关心终态
只需要取最后一条数据
select * from (select *,row_number() over(partition by order_id order by updatetime desc) rank from target) t where t.rank=1;
2021.7.20-拉链表的逻辑,使用场景,回滚















 1996
1996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









