







一、问题描述
客户生产环境监控发现在所有主机夜间2-3点,/home/t4目录磁盘使用率会暴涨后回落,由于时间范围比较固定,疑似某服务或主机设置定时任务导致,但和客户沟通在此时间段并未设置定时计划任务,和产研确认产品在此时间段也未设置定时计划任务。如此一来,就需要我们自己通过脚本抓取/home/t4下具体哪个目录导致的磁盘增长。
二、问题原因
1、通过脚本抓取到是/home/t4/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/目录下的某个数字目录变化导致的磁盘使用率增长回落,这里存储的是OverlayFS,每个数字目录都对应该主机上的pod

OverlayFS,也被称为 联合文件系统 或 联合挂载,它可让你使用2个目录挂载文件系统:“下层”目录(只读层)和“上层”目录(可写层)。
基本上:
文件系统的下层目录是只读的,
文件系统的上层目录可以读写
当进程“读取”文件时,OverlayFS 文件系统驱动将在上层目录中查找并从该目录中读取文件(如果存在)。否则,它将在下层目录中查找。
当进程“写入”文件时,OverlayFS 会将其写入上层目录,也就是可写层。
具体可参考链接:Docker原理之 - OverlayFS设计与实现-腾讯云开发者社区-腾讯云 <OverlayFS设计与实现>
2、通过排查对应的pod发现服务虽然没有设置定时计划任务,但是通过logrotate做了日志切割,logrotate参数
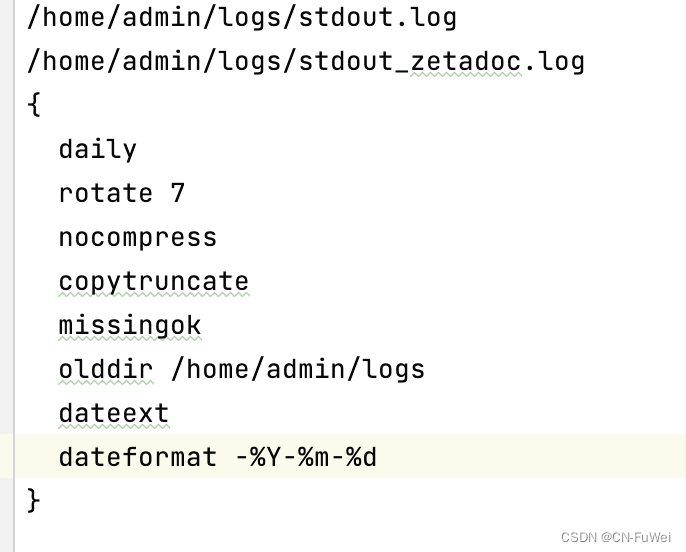
而其中copytruncate参数会有拷贝的动作,如果日志过大就会导致磁盘使用率突增。

三、解决方案
3.1. 脚本抓取增涨目录
脚本不限达到目的即可,测试环境调试好
#!/bin/bash
directory="/home/t4" # 替换为您要监视的目录路径
while true; do
current_time=$(date +"%Y-%m-%d %H:%M:%S")
echo "当前时间:$current_time"
echo "/home/t4:"
du -sh "$directory" --max-depth=1 # 显示目录占用空间
echo "/home/t4/containerd:"
du -sh "$directory"/containerd --max-depth=1 | sort -hr | head # 显示目录占用空间
sleep 5 # 等待5秒
done
nohup {脚本} & #后台运行,输出记录到当前目录下的文件nohup.out中根据日志nohup.out发现此目录下的某个数字目录会在凌晨磁盘使用变化较大,可以确认是这个目录的变化导致的告警

3.2. 确认容器ID
根据脚本抓到是/home/t4/containerd/io.containerd.snapshotter.v1.overlayfs/snapshots/目录下的某个数字目录名
mount|grep containerd.snapshotter.v1.overlayfs | grep {目录名} #下图高亮为容器ID3.3. 确认服务容器
1、可以根据当前主机运行容器确认
ctr -n k8s.io c list #会列出当前主机所有容器id和使用镜像
ctr -n k8s.io c list | grep [podID] #筛选到对应的容器ID,可以确认目录对应的服务2、如果通过容器ID无法确认是哪个服务

如图,镜像ID没有明确标注是哪个服务,可执行
mount | grep {容器ID} #找到容器映射的主机目录
或
df -h | grep {容器ID} #找到容器映射的主机目录

然后可以根据目录结构确认是哪个服务
3、根据yaml文件确认服务
kubectl get pod -A -owide | grep 100.88.161.35 #查看该主机上的所有服务POD
kubectl get pod -n 名称空间 POD名 -oyaml | grep b5a1ed372362e7948d711330f59b8ca26161c657b8ee8dbeaf9233538c3ea923 #根据容器ID筛选主机服务POD的yaml文件如果主机POD很多,可用如下脚本
kubectl get pod -A -owide | grep 100.88.161.35 | awk '{print $1" "$2}' > 20231118_pod.txt #将名称空间 和 POD名称 输入文件20231118_pod.txt
for i in `cat 20231118_pod.txt`;do kubectl get pod -n $i -oyaml | grep -C5 b5a1ed372362e7948d711330f59b8ca26161c657b8ee8dbeaf9233538c3ea923;done
#根据容器ID筛选主机所有POD的yaml文件
找到对应服务,我们就可以分析具体是什么原因导致的。
本次通过分析对应pod,发现被切割日志过大有40+G,logrotate设置的参数copytruncate会有拷贝动作,会导致磁盘使用率突增,所以需要增加minisize参数限制被切割日志的大小。
















 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











