









IP网段改变对(Hadoop、Hbase)集群的影响
1、集群现有的情况描述
版本信息
hadoop -2.7.6
zookeeper-3.4.5
hbase-0.96.2-hadoop2
1.1 三台虚拟机的ip地址
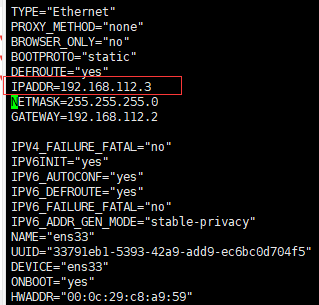
192.168.112.3 -->hadoop01
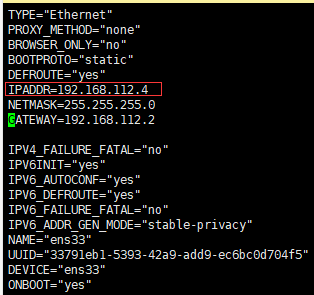
192.168.112.4 -->hadoop02
192.168.112.5 -->hadoop03
通过xshell连接,ping百度正常
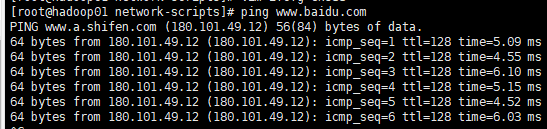
hadoop01(主) 192.168.112.3
hadoop02(从) 192.168.112.4
hadoop03(从) 192.168.112.5
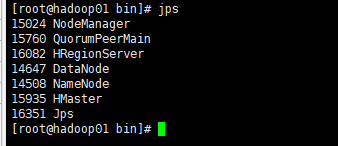
三台机器的进程为
hadoop01
43137 Jps
4627 QuorumPeerMain
4020 DataNode
3879 NameNode
42719 HMaster
42863 HRegionServer
hadoop02
3536 DataNode
3845 QuorumPeerMain
42714 HRegionServer
42877 Jps
hadoop03
3636 QuorumPeerMain
52406 Jps
3351 SecondaryNameNode
52234 HRegionServer
3243 DataNode
hadoop、zookeeper、hbase都已经启动
1.2 hadoop相关信息
vim /opt/modules/hadoop-2.7.6/etc/hadoop/hdfs-site.xml
在这个配置文件中,红线出的ip地址在更改集群的网段后,这里要做对应的更改,并且将此文件,复制到hbase/conf/ 下
cp hdfs-site.xml /opt/modules/hbase-0.96.2-hadoop2/conf
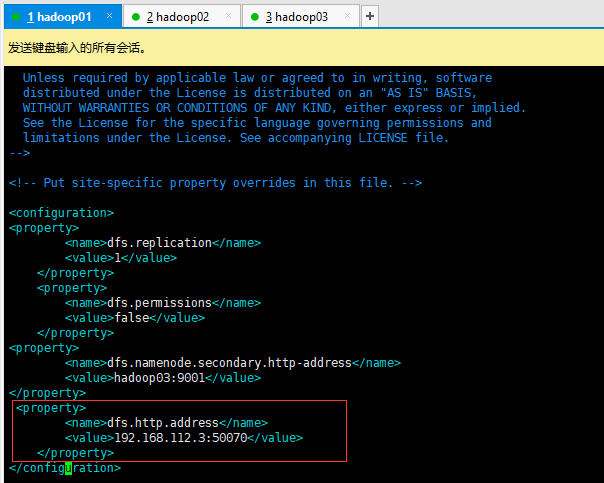
集群ip更改之前,192.168.112.3:50070可视化页面正常访问
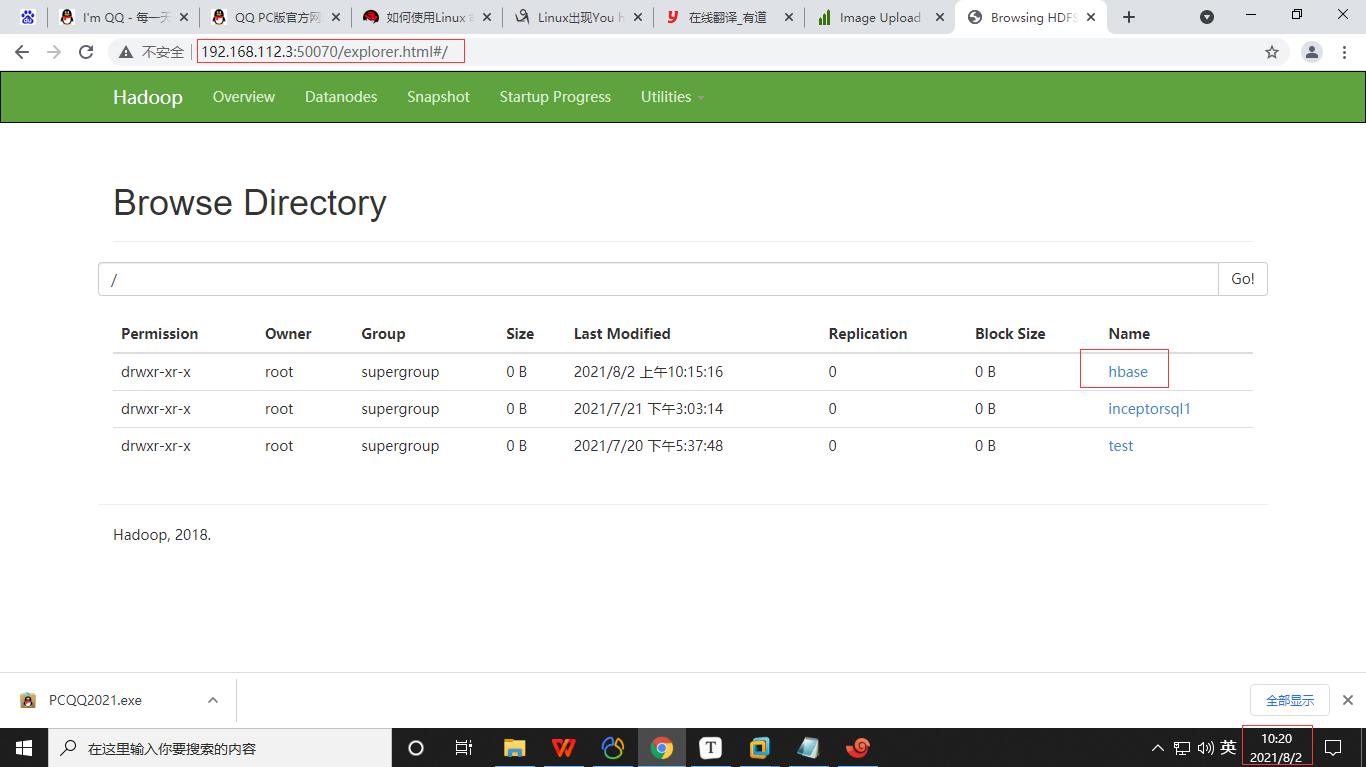
1.3 hbase相关信息
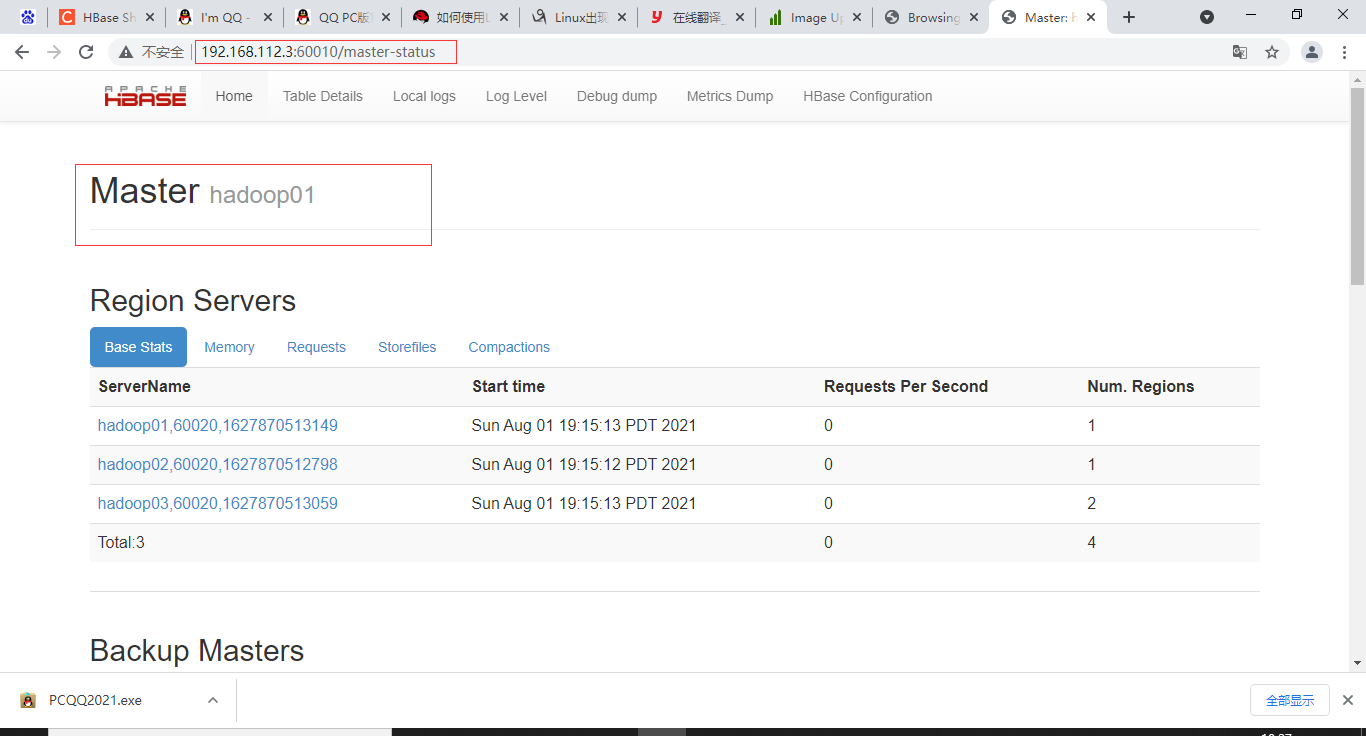
192.168.112.3:60010可视化页面正常
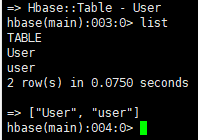
以及查看hbase里面的表信息,共有两个表 User,user,User是刚刚插入的表,我这里又插入了几条信息
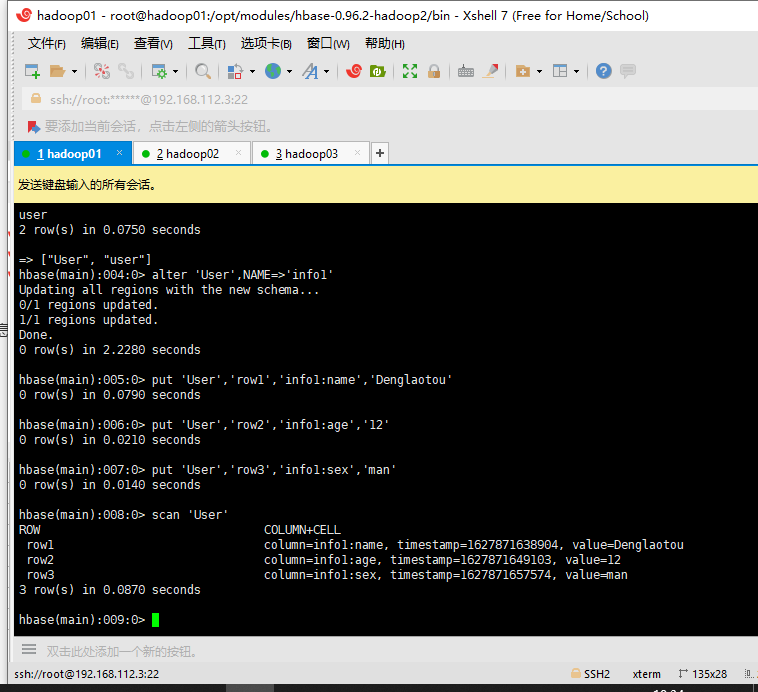
查看表内的信息,都正常,并且也要确保在更改集群ip之后,数据不会丢失或者改变。
1.4 zookeeper相关信息
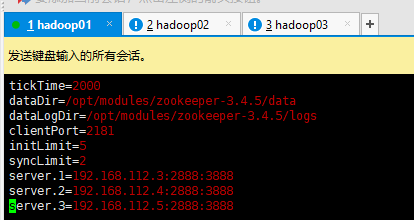
进入zkCli.sh正常,查看元数据列表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LXAxjMJx-1627963018022)(https://i.loli.net/2021/08/02/PNr5t7SWIZys8uq.png)]
zoo.cfg这个配置在更改了集群的网段之后,这里的配置也需要进行更改。
vim /opt/modules/zookeeper-3.4.5/conf/zoo.cfg
2、更改虚拟机的ip网段地址
2.1 关闭hadoop、zookeeper hbase集群
stop-all.shzkServer.sh stop #三台机器都要关闭./stop-hbase.sh
2.2 更改ip网段
不知道虚拟机开机更改ip会不会有影响,暂时先挂起虚拟机进行更改虚拟机的ip网段
2.2.1 更改子网的ip

将红线中的子网IP192.168.112.0 --> 192.167.111.0
重启三台虚拟机
目的首先保证网络能ping通,然后连接xshell进行接下来的操作
service network restartRestarting network (via systemctl): [ OK ]#但是ping 百度,失败 [root@hadoop01 ~]# ping www.baidu.comping: www.baidu.com: Name or service not known
需要更改 配置文件中的网络地址和对应的地址映射
2.2.2 更改虚拟机的配置文件
cd /etc/sysconfig/network-scriptsvim ifcfg-ens33#三台虚拟机都要更改hadoop01IPADDR=192.167.111.3GATEWAY=192.167.111.2hadoop02IPADDR=192.167.111.4GATEWAY=192.167.111.2hadoop03IPADDR=192.167.111.5GATEWAY=192.167.111.2#更改三台虚拟机下的/etc/hosts192.167.111.3 hadoop01192.167.111.4 hadoop02192.167.111.5 hadoop03
重启虚拟机,重启网络使更改的ip地址生效
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jGelh2Q6-1627963018024)(https://i.loli.net/2021/08/02/JPoFlrpmvHyzw1G.png)]
ping百度成功

依次对hadoop02和hadoop03进行操作,最后就可以使用xshell连接
12点00分
2.2.3 免密设置
生成公钥和私钥
#1ssh-keygen#2cd /root/.ssh#3ssh-copy-id hadoop01ssh-copy-id hadoop02ssh-copy-id hadoop03#测试ssh hadoop02
3、更改后ip后的集群设置
3.1 hadoop集群
3.1.1 尝试启动hadoop
启动发先namenode进程没有启动
查看log日志 发先异常
HttpServer.start() threw a non Bind IOExceptionjava.net.BindException: Port in use: 192.168.112.3:50070
初步认为是因为配置文件没有更改导致,需要更改配置文件 hdfs-site.xml
cd /opt/modules/hadoop-2.7.6/etc/hadoopvim hdfs-site.xml将Ip地址改为我们修改的网段的地址 <property> <name>dfs.http.address</name> <value>192.167.111.3:50070</value> </property>
hadoop02和hadoop03不需更改,因为他们的这个配置是
<property> <name>dfs.http.address</name> <value>0.0.0.0:50070</value></property>
发先resourcemanager没有正常在hadoop02启动,在Hadoop02上手动启动
yarn-daemone.sh start resourcemanager
3.1.2 将hdfs-site.xml 复制到Hbase的conf目录
3.1.3 重启hadoop集群
先关闭集群,然后重启
进入到192.167.111.3:50070页面成功
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GS8O75tB-1627963018025)(https://i.loli.net/2021/08/02/h6IeUYstfPAS3RH.png)]
3.3.4 查看hadoop01启动日志是否有error
hadoop01
more hadoop-root-namenode-hadoop01.log 无异常和错误 tail -n 50 hadoop-root-datanode-hadoop01.log 无异常和错误 tail -n 50 yarn-root-resourcemanager-hadoop01.log #端口问题导致resouremanager启动异常 Cannot assign requested address; #调低端口释放后的等待时间 sysctl -w net.ipv4.tcp_fin_timeout=30 #重启一下试试,再次查看是否有异常 问题解决,启动正常
hadoop02和hadoop03的日志也查看一下是否有异常
hadoop02的文件并无异常
tail -n 50 hadoop-root-datanode-hadoop02.logtail -n 50 yarn-root-nodemanager-hadoop02.logtail -n 50 yarn-root-resourcemanager-hadoop02.log
hadoop03
tail -n 50 hadoop-root-datanode-hadoop03.logtail -n 50 hadoop-root-secondarynamenode-hadoop03.log Inconsistent checkpoint fields.错误 原因是data-node上的namesecondary/和name-node/name/的clusterID不匹配导致 hadoop01的namenode的clusterID=CID-012cddf9-ec17-420a-b4a3-51c771949e21 hadoop03的datanode的clusterID=CID-012cddf9-ec17-420a-b4a3-51c771949e21 hadoop03的namesecondary的clusterID=CID-7deedf35-d519-4d8e-9bbd-589e810ff7dc 发先确实是不一致,更改为namenode的clusterID 关闭secodarynamenode,再重启一下查看日志是否有错误 修改之后,启动等待一两分钟,这个错误又出现了 尝试关闭集群,此异常是配置hadoop.tmp.dir参数引起的,在hdfs-site.xml中增加此参数,重新启动集群即可暂时没有解决,可以先尝试一下hbase的启动tail -n 50 yarn-root-nodemanager-hadoop03.log无异常
3.2 zookeeper的启动
3.2.1 更改三台的配置文件zoo.cfg
修改为我们的ip地址
然后分发到另外两个节点
cd /opt/modules/zookeeper-3.4.5/confscp -r zoo.cfg hadoop02:`pwd`scp -r zoo.cfg hadoop03:`pwd`
三台虚拟机都启动zookeeper
进程都正常
查看/data/version-2并无启动报错
3.3hbase集群
在主节点直接启动Hbase集群
cd /opt/modules/hbase-0.96.2-hadoop2/bin./start-hbase.sh
在主节点HMaster启动失败
由于之前将zookeeper关闭了,忘记zookeeper以及关闭了,
因为Hbase是需要依赖zookeeper去管理元数据信息的,没有zookeeper是不可以的。
3.3.1 进入hbase shell
查看之前创建的表信息是否还存在
查看表名还存在,查看表内的数据是否还存在
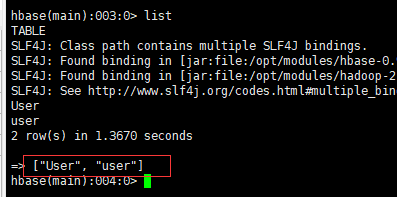
发先表内的数据还存在。

4、总结
通过更改虚拟机的子网ip,来更改虚拟机的网段,来查看对原集群的影响
更改之后,对集群相应的配置文件进行修改,重新启动集群,文件还都存在。
1.虚拟机需要更改的配置文件
三台虚拟机都要操作
/etc/hosts
/etc/sysconfig/network-scripts/ifcfg-en33
2.hadoop需要更改的配置文件:
三台虚拟机都要操作
hadoop01的/etc/hadoop/hdfs-site.xml
zookeeper需要更改的配置文件:
三台虚拟机都要操作
zookeeper_home/cong/zoo.cfg
hbase无需要更改的配置文件:
在Hadoop01上操作就可以
只需要将更改过的hdfs-site.xml,覆写到hbase/conf/下















 847
847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









