







背景
自己在同步mysql数据到hive(hdfs)的时候 发现设置的channel数与最终实际跑的task数不一致,查看官网文档 也没找到自己想要的答案,就决定查看源码
1.本地如何调试datax
1.下载datax源码
https://github.com/alibaba/DataX.git
2.对datax进行编译打包
进入刚刚下载好的datax源码根目录
cd {DataX_source_home}
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 08:33 min
[INFO] Finished at: 2024-08-31T10:20:56+08:00
[INFO] ------------------------------------------------------------------------
3.配置启动参数
datax启动类是com.alibaba.datax.core.Engine
vm option
地址就是你打包后的地址
-Ddatax.home=/Users/IdeaProjects/DataX/target/datax/datax
program args
-mode standalone -jobid -1 -job /Users/temp/datax_test_db_table_test.json

tips
有些人的vm option找不到 需要点击旁边的 Modify options 将vm option展示出来

配置好以上 就可以对datax进行本地断点调试了
2.源码阅读
这里我主要为了解决背景中提出的问题,所以直奔目的,找到datax split 逻辑那段代码了,其他有自己想了解的也可以慢慢进行调试摸索
split核心代码流程
Engine.start()-->JobContainer.start()-->JobContainer.split()
-->this.doReaderSplit(this.needChannelNumber)
this.needChannelNumber = this.configuration.getInt(CoreConstant.DATAX_JOB_SETTING_SPEED_CHANNEL);
也就是自己设置的channel数(再没设置byte和record情况下)
-->MysqlReader.split(int adviceNumber)
-->ReaderSplitUtil.doSplit(Configuration originalSliceConfig, int adviceNumber)
-->eachTableShouldSplittedNumber = (int) Math.ceil(1.0 * adviceNumber / tableNumber);
eachTableShouldSplittedNumber = eachTableShouldSplittedNumber * splitFactor;
splitFactor 默认是5
核心代码片段详解
table 模式
在源码 com.alibaba.datax.plugin.rdbms.reader.util.ReaderSplitUtil 下
Integer splitFactor = originalSliceConfig.getInt(Key.SPLIT_FACTOR, Constant.SPLIT_FACTOR);
eachTableShouldSplittedNumber = eachTableShouldSplittedNumber * splitFactor;
其中 eachTableShouldSplittedNumber = 1.0* channel / tableNumber(并且向上取整)
task数 = (channel * splitFactor)
而分sql的时候 还会有一个null 判断
task数 = (channel * splitFactor)+1
而多表则是 (Math.ceil(1.0 * channel / tableNumber) * splitFactor) +tableNumber
要设置 channel与task一致 也就是最终hdfs文件个数,需要在reader中加上参数"splitFactor":1
并且 splitPk一定要有,且是字符串或者数字类型 否则只会起一个线程抽数
其实最终目的就是将表中的数据 划分成多个sql 进行抽数,如下图,channel =2 ,splitFactor =1, tableNum = 1 最终3个task




querySql模式
而querysql模式 则需要用几个sql拼接起来用,隔开 代码中会将字符串转成list数组,达到并发抽取,channel 无效
(table 模式设置channel就是系统根据splitpk去切分sql,最终和自己写querysql一样)

总结
1.table模式
1.有splitPk键,为数字类型或者字符串
2.设置channel>1
3.没有设置byte和record限制
4.设置splitFactor(默认5)
task数 (Math.ceil(1.0 * channel / tableNumber) * splitFactor) +tableNumber
2.quesql模式
与channel无关,由json中 querySql数组中 有几个querysql决定
3.hive导出mysql
由导出的hive表有多少文件决定
datax并发运行的数量
由min(channelNum,taskNum) 决定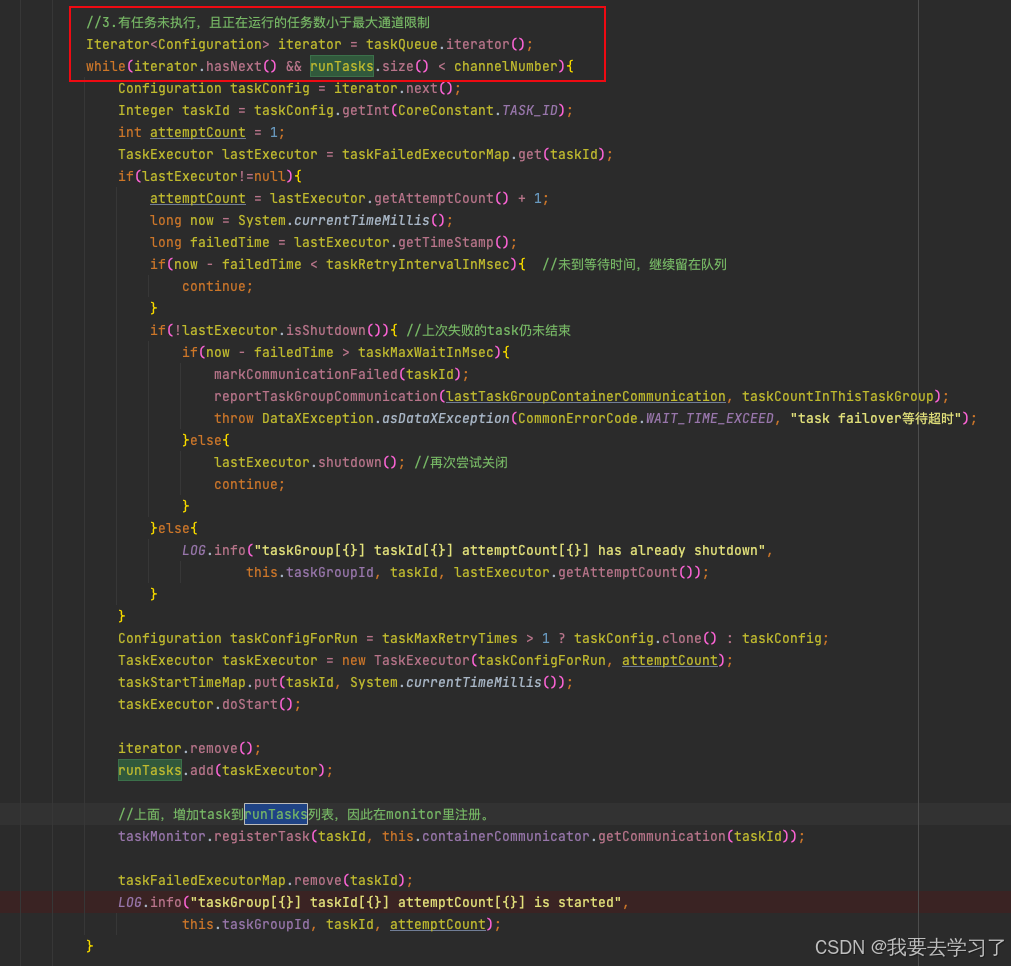
如有写的不准确的地方 欢迎指出,有不懂的地方也欢迎留言提问,谢谢


















 1718
1718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









