







这个代码比较老旧,请移步最新实现link:https://blog.csdn.net/zh_JNU/article/details/81018352,可在本文查看数据说明和在末尾下载数据集,谢谢~~~~~
接触深度学习3个月以来,从当初的小白零基础学习,过程十分艰苦,看了几章大牛 YoshuaBengio 写的deep learning一书,粗略了解了基本常用的神经网络以及梯度更新策略,参数优化,也了解以及简单的使用常用的深度学习开发框架caffe,tensorflow,theano,sklearn机器学习库,目前keras比较火,所以使用keras来简单的进行图片识别分类。
数据集准备:
看caffe博客的时候看到的数据集,然后就下载使用,数据集可以在最后下载。
数据集一共有5类图片,一共500张,每类图片100张,训练集400张,每类80张,测试集100张,每类20张
第一步:
数据集进行处理:
使用opencv对图片进行处理,缩放图片大小为128×128大小,通道为单通道灰度图像
#coding:utf8
import os
import cv2.cv as cv
import cv2
# 遍历指定目录,显示目录下的所有文件名
width_scale = 192 #缩放尺寸宽度
height_scale = 128#缩放尺寸高度
write_path = "/home/zhanghao/data/classification/test_scale/"#要写入的图片路径
#遍历每一张图片进行处理
def eachFile(filepath):
pathDir = os.listdir(filepath)
for allDir in pathDir:
child = os.path.join('%s%s' % (filepath,allDir))
write_child = os.path.join('%s%s' % (write_path,allDir))
image = cv.LoadImage(child,0)
des_image = cv.CreateImage((width_scale,height_scale),image.depth,1)
cv.Resize(image,des_image,cv2.INTER_AREA)
# cv.ShowImage('afe',des_image)
cv.SaveImage(write_child,des_image)
# break
if __name__ == '__main__':
filePathC = "/home/zhanghao/data/classification/test/"
eachFile(filePathC)


第二步
把图片集制作成keras识别的数据集
#制作数据集
def data_label(path,count):
data = np.empty((count,1,128,192),dtype = 'float32')#建立空的四维张量类型32位浮点
label = np.empty((count,),dtype = 'uint8')
i = 0
pathDir = os.listdir(path)
for each_image in pathDir:
all_path = os.path.join('%s%s' % (path,each_image))#路径进行连接
image = cv2.imread(all_path,0)
mul_num = re.findall(r"\d",all_path)#寻找字符串中的数字,由于图像命名为300.jpg 标签设置为0
num = int(mul_num[0])-3
# print num,each_image
# cv2.imshow("fad",image)
# print child
array = np.asarray(image,dtype='float32')
data[i,:,:,:] = array
label[i] = int(num)
i += 1
return data,label
第三步
构建卷积神经网络进行训练和测试
#构建卷积神经网络
def cnn_model(train_data,train_label,test_data,test_label):
model = Sequential()
model.add(Convolution2D(
nb_filter = 12,
nb_row = 3,
nb_col = 3,
border_mode = 'valid',
dim_ordering = 'th',
input_shape = (1,128,192)))
model.add(Activation('relu'))#激活函数使用修正线性单元
model.add(MaxPooling2D(
pool_size = (2,2),
strides = (2,2),
border_mode = 'valid'))
model.add(Convolution2D(
24,
3,
3,
border_mode = 'valid',
dim_ordering = 'th'))
model.add(Activation('relu'))
#池化层 24×29×29
model.add(MaxPooling2D(
pool_size = (2,2),
strides = (2,2),
border_mode = 'valid'))
model.add(Convolution2D(
48,
3,
3,
border_mode = 'valid',
dim_ordering = 'th'))
model.add(Activation('relu'))
model.add(MaxPooling2D(
pool_size = (2,2),
strides =(2,2),
border_mode = 'valid'))
model.add(Flatten())
model.add(Dense(20))
model.add(Activation(LeakyReLU(0.3)))
model.add(Dropout(0.5))
model.add(Dense(20))
model.add(Activation(LeakyReLU(0.3)))
model.add(Dropout(0.4))
model.add(Dense(5,init = 'normal'))
model.add(Activation('softmax'))
adam = Adam(lr = 0.001)
model.compile(optimizer = adam,
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
print '----------------training-----------------------'
model.fit(train_data,train_label,batch_size = 12,nb_epoch = 35,shuffle = True,show_accuracy = True,validation_split = 0.1)
print '----------------testing------------------------'
loss,accuracy = model.evaluate(test_data,test_label)
print '\n test loss:',loss
print '\n test accuracy',accuracy
第四步
调用上述函数进行训练预测
train_path = '/home/zhanghao/data/classification/train_scale/'
test_path = '/home/zhanghao/data/classification/test_scale/'
train_count = getnum(train_path)
test_count = getnum(test_path)
train_data,train_label = data_label(train_path,train_count)
test_data,test_label = data_label(test_path,test_count)
train_label = np_utils.to_categorical(train_label,nb_classes = 5)
test_label = np_utils.to_categorical(test_label,nb_classes = 5)
cnn_model(train_data,train_label,test_data,test_label)
用到的头文件
import re
import cv2
import os
import numpy as np
import cv2.cv as cv
from keras.models import Sequential
from keras.layers.core import Dense,Activation,Flatten
from keras.layers.convolutional import Convolution2D,MaxPooling2D
from keras.optimizers import Adam
from keras.layers.advanced_activations import LeakyReLU
from keras.utils import np_utils
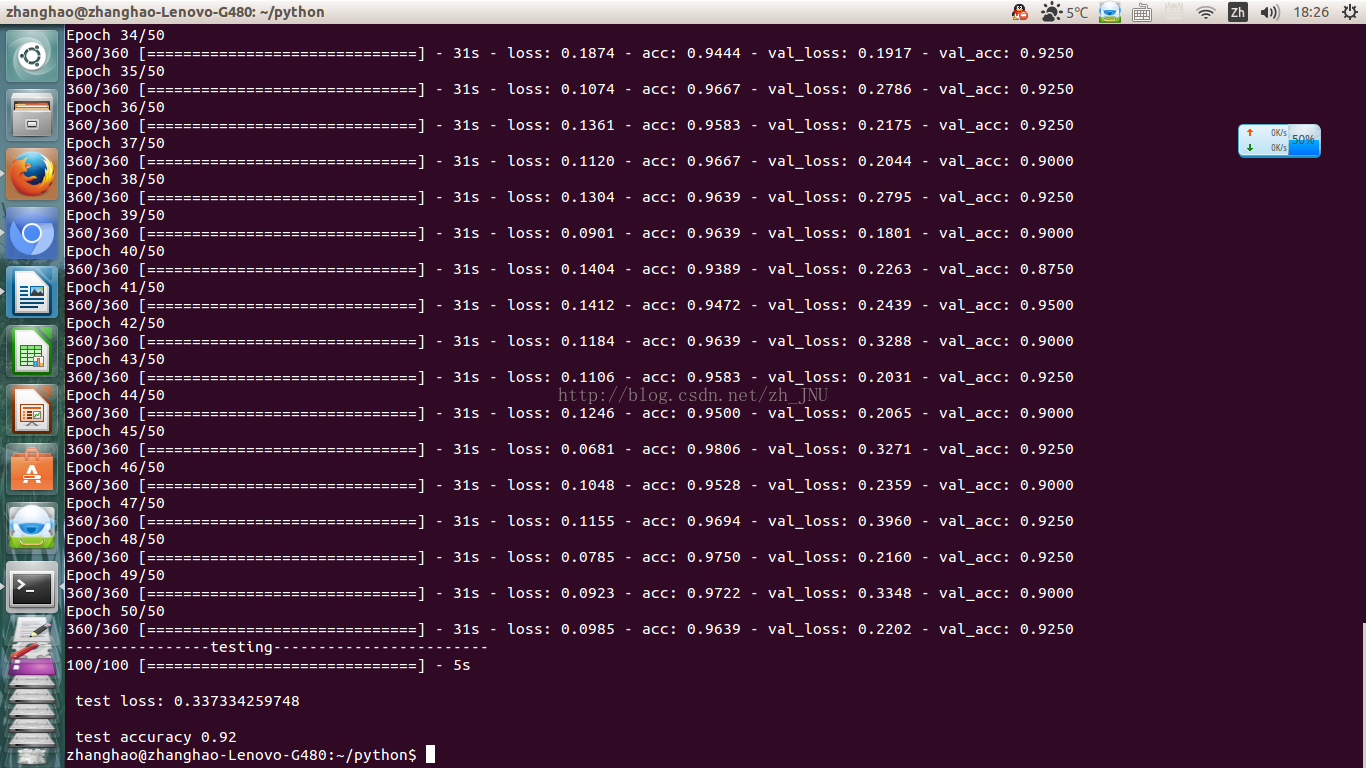
cpu运行,迭代50次,预测准确率达到92%,还算可以的准确率
具体实现代码:https://github.com/zhanghao-JNU/keras-training
路漫漫其修远兮,吾将上下而求索
数据集网盘链接链接:https://pan.baidu.com/s/1boDvWTL 密码:vxrb
有什么问题可以发邮件联系(zhanghao-jnu@qq.com)共同讨论进步,这个代码太老啦太low啦,有什么错误不要介意!!!!

















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









