




 本文介绍XPath的基本用法及实战技巧,包括属性定位、层级索引定位、逻辑运算、模糊匹配等,并通过实例展示如何使用lxml库进行节点选取、文本获取等操作。
本文介绍XPath的基本用法及实战技巧,包括属性定位、层级索引定位、逻辑运算、模糊匹配等,并通过实例展示如何使用lxml库进行节点选取、文本获取等操作。
XPath常用规则

小技巧
生成xpath,只需右键COPY选择COPY XPath即可,截图截不下来,自行尝试
属性定位:
#找到class属性值为song的div标签
//div[@class=“song”]
层级&索引定位:
#找到class属性值为tang的div的直系子标签ul下的第二个子标签li下的直系子标签a
//div[@class=“tang”]/ul/li[2]/a
逻辑运算:
#找到href属性值为空且class属性值为du的a标签
//a[@href="" and @class=“du”]
模糊匹配:
//div[contains(@class, “ng”)]
//div[starts-with(@class, “ta”)]
取文本:
# /表示获取某个标签下的文本内容
# //表示获取某个标签下的文本内容和所有子标签下的文本内容
//div[@class=“song”]/p[1]/text()
//div[@class=“tang”]//text()
取属性:
//div[@class=“tang”]//li[2]/a/@href
//title[@lang='english'] 代表选择所有名称为title,属性值为english的节点
from lxml import etree
text='''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text) #构造一个XPath解析对象
result = etree.tostring(html) #修正text中的代码
print(type(result))
print(result.decode('utf-8'))
'''
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser()) #解析当前文件夹下的文件
result = etree.tostring(html)
print(result.decode('utf-8'))
'''
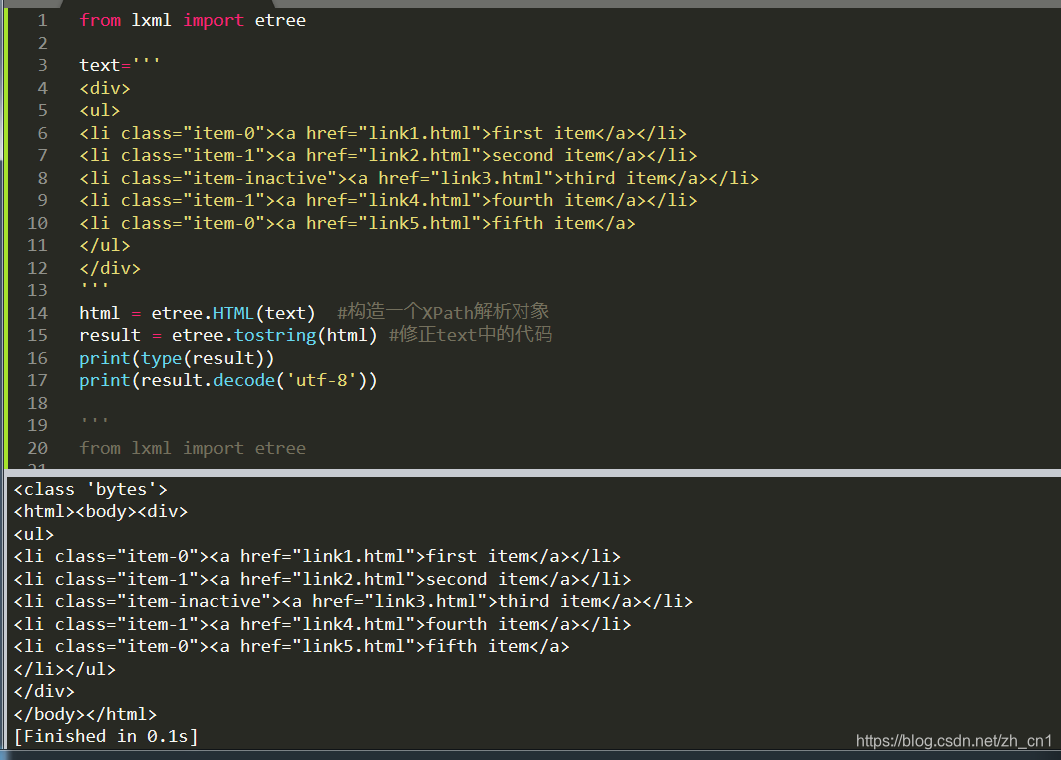
获取所有节点
from lxml import etree
text='''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text) #html = etree.parse('./test.html',etree.HTMLParse()) 记得括号
result = html.xpath('//*') #获取所有节点html、li等
print(result)
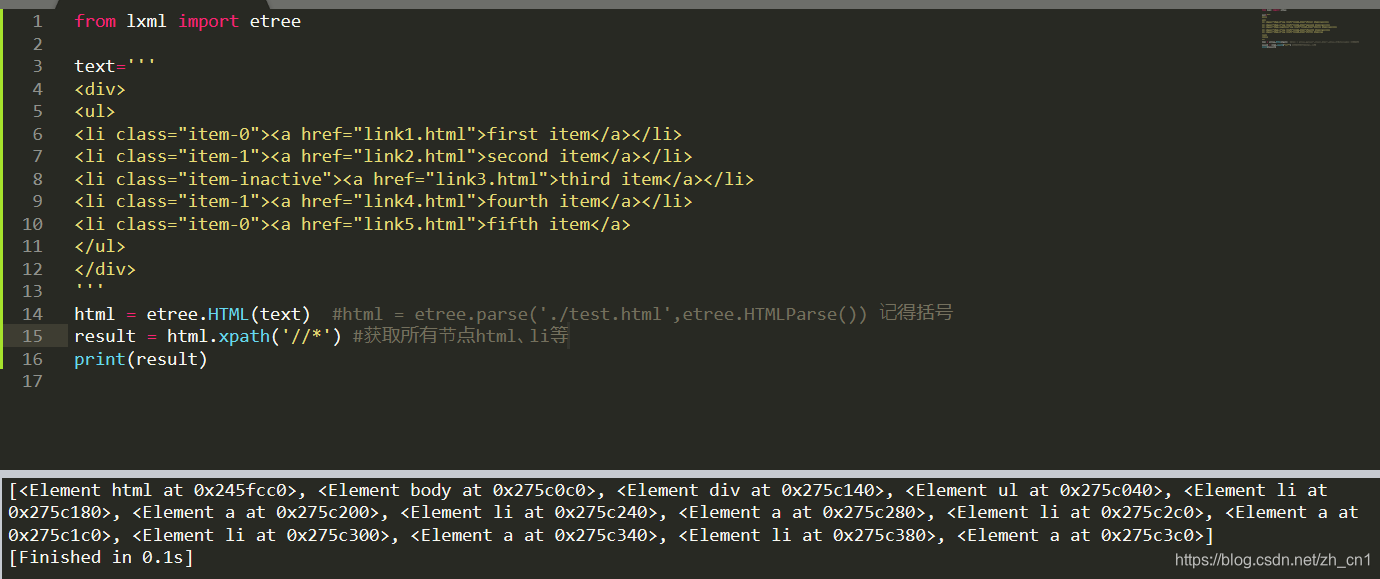
子节点
# /获取子节点 //获取子孙节点
from lxml import etree
text='''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text) #html = etree.parse('./test.html',etree.HTMLParse()) 记得括号
result = html.xpath('//li/a') #获取li节点下的a节点
print(result)
result1 = html.xpath('//ul/a')
print(result1)
result2 = html.xpath('//ul//a')
print(result2)
父节点
from lxml import etree
text='''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text) #html = etree.parse('./test.html',etree.HTMLParse()) 记得括号
#result = html.xpath('//a[@href="link4.html"]/../@class')
result = html.xpath('//a[@href="link4.html"]/parent::*/@class')
print(result)

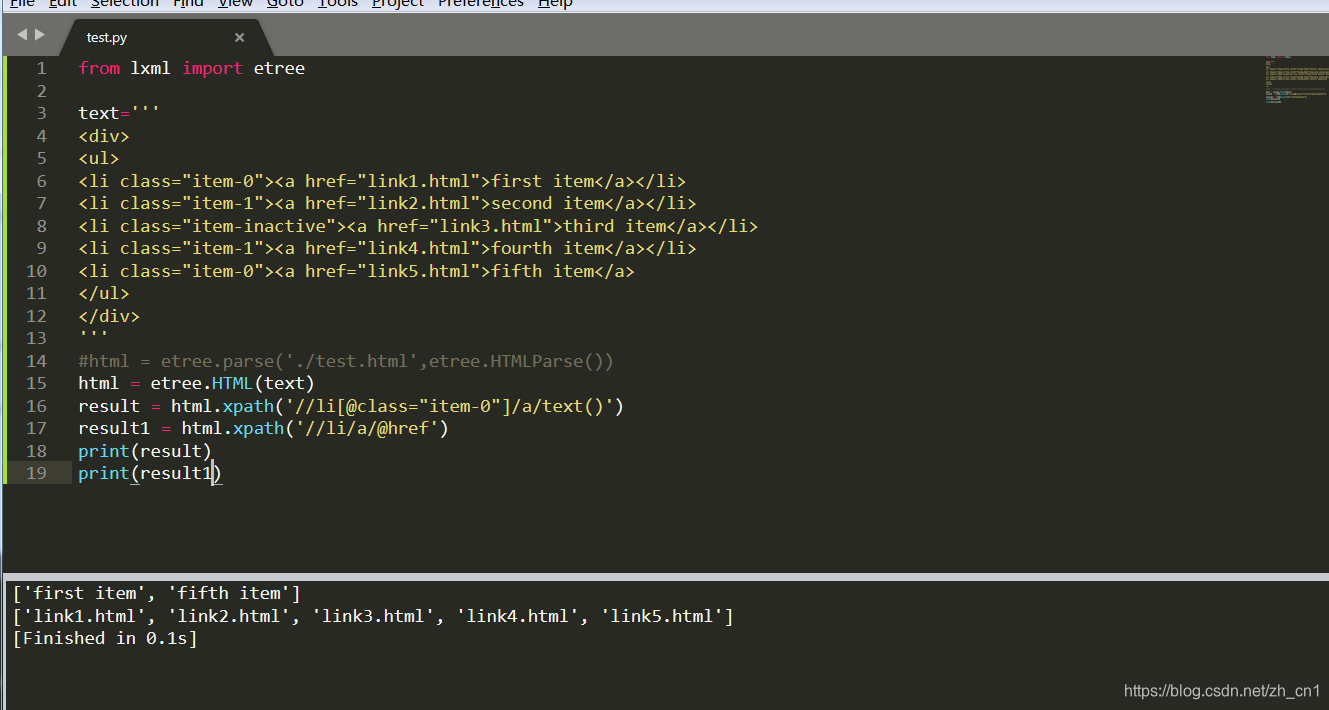
文本获取text()
from lxml import etree
text='''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
#html = etree.parse('./test.html',etree.HTMLParse())
html = etree.HTML(text)
result = html.xpath('//li[@class="item-0"]/a/text()')
result1 = html.xpath('//li/a/@href')
print(result)
print(result1)
属性多值匹配
from lxml import etree
text='''
<li class="li li-firsr"><a href="link.html">first item</a></li>
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,"li")]/a/text()')
print(result)


















 58万+
58万+




 到【灌水乐园】发言
到【灌水乐园】发言







