







目标
学习多种信息的集成如文本和链接如何集成,主要参考triParty论文及其源码。
论文主要内容
论文标题:Tri-Party Deep Network Representation
作者:Shirui Pan , Jia Wu , Xingquan Zhu , Chengqi Zhang , Yang Wang
发表时间:2018-05-13
发表地点(会议或期刊名称):Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16)(第二十五届国际人工智能联合会议(IJCAI-16)会议记录)
文章背景: 信息网络挖掘往往需要对节点间的链接关系进行分析。近年来,网络表示已经出现以向量格式表示每个节点,来嵌入网络结构,因此可以直接应用现成的机器学习方法进行分析。现有的算法大多是简单的浅层算法,只使用节点信息的一个方面。此外,现有的任何一种方法都不能利用网络中的标签信息来表示。(就是当时大多数研究都是只是利用网络结构来学习网络表示network representation的embedding)
解决问题 : (1)网络结构、节点内容与标签信息的集成(如何将包含链接和丰富文本信息的网络学习节点嵌入,并进一步定制带有标记样本的学习任务的表示?) (2)神经网络建模(如何为网络数据设计有效的神经网络模型,以获得更深层次的网络表示结果)
创新点 :(1)利用多方、不同网络层次的网络表示法。(2)提出了一种新的用于深度网络表示学习的神经网络模型Tri-DRN(tri-party deep network representation model):一种基于耦合神经网络的算法来挖掘网络中的节点间关系(node-word correlation)、节点内容相关性(node content)和标记内容(node labels)对应关系,利用这三者信息来生成节点的embedding。
解决方案:
1.该模型的学习在3个层次上加强:
(1)在网络结构层次上,TriDNR利用节点间的关系,最大限度地观察随机游动中给定节点的周围节点的概率;
(2)在节点内容层次上,TriDNR通过最大化给定节点的词序列的共现性来捕获节点词的相关性。
(3)在节点标签层上,TriDNR通过最大化给定类标签的词序列概率来建立标签词对应模型。
2.TriDNR算法主要包括两个步骤: (1)“随机漫游序列生成”使用网络结构作为输入并随机生成节点上的一组漫游,每次遍历根节点Vi并每次随机跳转到其它节点。随机游动语料库可以捕获节点关系。(联想DeepWalk) (2)耦合神经网络模型学习将每个节点嵌入到连续空间中,通过考虑以下信息:(a)捕捉节点间关系的随机游动语料库。(b)建立节点内容相关性模型的文本语料库,(c)对标签节点对应进行编码的标签信息。
模型体系结构:

1.节点间关系建模—— 在假定所连接的节点彼此具有统计依赖性的情况下,Tri-DNR的上层学习来自随机行走序列的结构关系。(生成节点Vi的embedding Vvi)
2.节点-内容相关性评估—— Tri-DNR的下层模拟了文档中单词的上下文信息(语义相关性)。
3.用节点V1 连接1和2的模型,则V1 的embedding同时被1(随机游动序列)和2(节点内容信息)影响。
4.利用每个节点的标签信息,直接在节点标签和上下文之间建模,即利用每个document的标签作为输入,学习输入标签向量和输出单词向量。
TriDNR模型的目标是最大限度地实现以下目标似然函数:
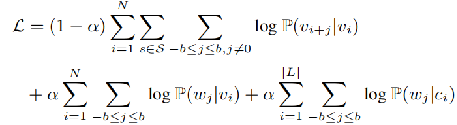
α是权重。第1项是random walk+skip-gram的概率表达,也就是在当前点vi作为输入时,输出的的到的向量要更大可能的表示他的邻居。第2项是在当前节点的输入下,输出的向量要更大可能的表示此节点的论文标题中的单词。第3项是在当前节点的label的输入下,输出的向量要更大可能的表示此节点的论文标题中的单词。
综合来看,也就是我们学习到的点的表达,不仅可以使得邻居节点的表达相似,也可以使得论文的文本相似的节点相似,当然是在label相似的前提下。
实验数据集
本文是在两个网络上报告实验结果。它们都是引文网络,将论文标题用作网络中每个节点的节点内容
1.DBLP数据集1由计算机科学中的参考书目数据组成,每一篇论文都可以引用或被其他论文引用,这自然形成了一个引文网络。DBLP网络由60,744篇论文(节点)组成,共有52,890条边。
2.CiteSeerM10是CiteSeerX数据2的子集,由来自10个不同研究领域的科学出版物组成。该数据集由10个多学科类组成,共有10 310份出版物和77 218条边。
Measures & Parameter Setting
(1)利用不同的比较方法得到节点向量后,从训练数据(节点)中训练出线性支持向量机(SVM)来预测未标记节点。
(2)TriDNR的默认参数设置如下:window size b=8, dimensions k =300,α = 0.8.
实验效果——数据集M10
10310 documents、10 classes、train y: , test y: 2062 :8248 Training_Percent=0.2
| model | Accuracy | macro_f1 | micro_f1 |
| DeepWalk | 0.4704 | 0.3719 | 0.4704 |
| Doc2Vec | 0.6037 | 0.5629 | 0.6037 |
| DeepWalk + Doc2Vec | 0.6309 | 0.5920 | 0.6309 |
| TriDNR | 0.6579 | 0.6258 | 0.6579 |
从实验结果可以看出,DeepWalk算法在引用网络上的性能最差。这主要是因为网络结构比较稀疏,只包含有限的信息。 Doc2Vec比DeepWalk要好得多,这是因为文本内容(标题)与网络结构相比具有丰富的信息。 当连接来自DeepWalk和Doc2Vec的嵌入时,网络表示得到了很大的改进。 TriDNR是这些结果中最好的。
结论
实验结果表明,使用标签信息学习网络嵌入的DNRL(仅使用TriDNR模型的较低层)已经优于两种神经网络模型(DW+D2V)的简单组合。 TRIDDNR利用标签信息,显著提高了表示能力,从而实现了良好的分类性能。
总结和思考
1.本文提出了一种Tri-DNR算法。现有的算法大多是简单的浅层算法,只使用节点信息的一个方面。此外,现有的任何一种方法都不能利用网络中的标签信息来表示。相应地,本论文提出了一种基于耦合神经网络的算法来利用网络中的节点间关系、节点内容相关性和标签内容对应去了解网络中每个节点的最佳表示。 2.该论文的主要贡献有两点: (1)利用多方、不同网络层次的网络表示法, (2)提出了一种新的网络深度表示学习神经网络模型。
代码深思
1.读取数据。数据M10数据集
文件夹包括三个文本:(1)adjedges.txt 邻接表 (2)doc.txt 文章题目编号——文章标题 (当作文本内容)(3)标签信息
from collections import namedtuple
from gensim.models import Doc2Vec, Word2Vec
from random import shuffle
from deepwalk import graph
import gensim
import random
import gensim.utils as ut
#使用gensim中的Word2vec和doc2vec
NetworkSentence=namedtuple('NetworkSentence', 'words tags labels index')
Result = namedtuple('Result', 'alg trainsize acc macro_f1 micro_f1')
AlgResult = namedtuple('AlgResult', 'alg trainsize numfeature mean std')
def readNetworkData(dir, stemmer=0): #dir, directory of network dataset
allindex={}
alldocs = []
labelset = set()
with open(dir+'/docs.txt','r',encoding='UTF-8') as f1, open(dir + '/labels.txt','r',encoding='UTF-8') as f2:
for l1 in f1:
#tokens = ut.to_unicode(l1.lower()).split()
if stemmer == 1:
l1 = gensim.parsing.stem_text(l1)
else:
l1 = l1.lower()
tokens = ut.to_unicode(l1).split()
words = tokens[1:]
tags = [tokens[0]] # ID of each document, for doc2vec model
index = len(alldocs)
allindex[tokens[0]] = index # A mapping from documentID to index, start from 0
l2 = f2.readline()
tokens2 = gensim.utils.to_unicode(l2).split()
labels = tokens2[1] #class label
labelset.add(labels)
alldocs.append(NetworkSentence(words, tags, labels, index))
return alldocs, allindex, list(labelset)
def coraEdgeFileToAdjfile(edgefile, adjfile, nodoc):
edgeadj = {str(n): list() for n in range(nodoc)}
with open(edgefile, 'r') as f:
for l in f:
tokens = l.split()
edgeadj[tokens[0]].append(tokens[1])
wf = open(adjfile, 'w')
for n in range(nodoc):
edgestr = ' '.join(map(str, edgeadj[str(n)]))
wf.write(str(n) + ' ' +edgestr +'\n')
wf.close()
def cora10groupdataset():
groupindex = {}
groupmap = {}
with open('data2/Cora/CoraHierarchyTree.txt', 'r') as f:
for l in f:
tokens = l.split('\t')
if(len(tokens) <= 2):
continue
elif(len(tokens) == 3):
currentindex = len(groupindex)
groupindex[tokens[1]] = currentindex
elif(len(tokens) == 5):
#print l
groupmap[tokens[3]] = currentindex
elif(len(tokens)==6):
#print tokens[3]
groupmap[tokens[4]] = currentindex
else:
pass
# All class 0 as a separate class
groupmap['0'] = len(groupindex) + 1
print('number of classes: %d ' % len(groupmap))
wf = open('data2/Cora/labels.txt', 'w')
with open('data2/Cora/paper_label.txt') as f1:
for l in f1:
tokens = l.split()
wf.write(tokens[0] + ' ' + str(groupmap[tokens[1]]) + '\n')
wf.close()
def getdeepwalks(dir, number_walks=50, walk_length=10, seed=1):
G = graph.load_adjacencylist(dir+'/adjedges.txt')
print("Number of nodes: {}".format(len(G.nodes())))
num_walks = len(G.nodes()) * number_walks
print("Number of walks: {}".format(num_walks))
print("Walking...")
walks = graph.build_deepwalk_corpus(G, num_paths=number_walks, path_length=walk_length, alpha=0, rand=random.Random(seed))
networksentence = []
raw_walks = []
for i, x in enumerate(walks):
sentence = [gensim.utils.to_unicode(str(t)) for t in x]
s = NetworkSentence(sentence, [sentence[0]], None, 0) # label information is not used by random walk
networksentence.append(s)
raw_walks.append(sentence)
return raw_walks, networksentence
def trainDoc2Vec(doc_list=None, buildvoc=1, passes=20, dm=0,
size=100, dm_mean=0, window=5, hs=1, negative=5, min_count=1, workers=4):
model = Doc2Vec(dm=dm, size=size, dm_mean=dm_mean, window=window,
hs=hs, negative=negative, min_count=min_count, workers=workers) #PV-DBOW
if buildvoc == 1:
print('Building Vocabulary')
model.build_vocab(doc_list) # build vocabulate with words + nodeID
print('Iteration')
for epoch in range(passes):
#print('Iteration %d ....' % epoch)
shuffle(doc_list) # shuffling gets best results
model.train(doc_list,total_examples=model.corpus_count,epochs=model.epochs)
return model
def trainWord2Vec(doc_list=None, buildvoc=1, passes=20, sg=1, size=100,
dm_mean=0, window=5, hs=1, negative=5, min_count=1, workers=4):
model = Word2Vec(size=size, sg=sg, window=window,
hs=hs, negative=negative, min_count=min_count, workers=workers)
if buildvoc == 1:
print('Building Vocabulary')
model.build_vocab(doc_list) # build vocabulate with words + nodeID
print('Iteration')
for epoch in range(passes):
#print('Iteration %d ....' % epoch)
shuffle(doc_list) # shuffling gets best results
model.train(doc_list,total_examples=model.corpus_count,epochs=model.epochs)
return model
def toMatFile(directory, tfidf=1): #convert the file to a matlab file, using TF-IDF or Binary format
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_selection import SelectKBest, chi2
alldocs, allsentence, classlabels = readNetworkData(directory)
corpus = [' '.join(doc.words) for doc in alldocs]
vectorizer = TfidfVectorizer(min_df=3)
## Feature Vector
new_vec = vectorizer.fit_transform(corpus)
print("n_samples: %d, n_features: %d" % new_vec.shape)
## Label
y = [doc.labels for doc in alldocs]
## Vector
读取包含文本,标签,结构信息的`directory`中的数据,并从Doc2Vec和DeepWalk模型初始化TriDNR,然后使用文本,标签和结构信息迭代更新模型
将监督信息添加到训练数据中,使用标签信息进行学习,具体来说,doc2vec算法使用tag信息作为文档ID,并学习每个标签(ID)的矢量表示。将类标签添加到tag中,所以每个类标签都将作为一个ID,用于学习潜在的表示#使用gensim中的Word2vec和doc2vec
#Deepwalk(word2vec)表示节点的随机游走信息,即利用网络结构信息,首先是随机游走得到相邻节点,最大化相邻节点的概率
#doc2vec模拟 文本内容相似性
from sklearn.model_selection import train_test_split
from gensim.models.doc2vec import Doc2Vec
import networkutils as net
from random import shuffle
import Evaluation
'''读取包含文本,标签,结构信息的`directory`中的数据,并从Doc2Vec和DeepWalk模型初始化TriDNR,然后使用文本,标签和结构信息迭代更新模型'''
class TriDNR:
"""
`train_size`: Percentage of training data in range 0.0-1.0, if train_size==0, it becomes pure unsupervised network
representation
`text_weight`: weights for the text inforamtion 0.0-1.0
`size` is the dimensionality of the feature vectors.
`dm` defines doc2vec the training algorithm. (`dm=1`), 'distributed memory' (PV-DM) is used.
Otherwise, `distributed bag of words` (PV-DBOW) is employed.
`min_count`: minimum number of counts for words
"""
def __init__(self, directory=None, train_size=0.3, textweight=0.8, size=300, seed=1, workers=1, passes=10, dm=0, min_count=3):
# Read the data
alldocs, docindex, classlabels = net.readNetworkData(directory)
print('%d documents, %d classes, training ratio=%f' % (len(alldocs), len(classlabels), train_size))
print('%d classes' % len(classlabels))
#Initilize Doc2Vec
if train_size > 0: #label information is available for learning
print('Adding Label Information')
train, test = train_test_split(alldocs, train_size=train_size, random_state=seed)
"""
Add supervised information to training data, use label information for learning
Specifically, the doc2vec algorithm used the tags information as document IDs,
and learn a vector representation for each tag (ID). We add the class label into the tags,
so each class label will acts as a ID and is used to learn the latent representation
"""
alldata = train[:]
for x in alldata:
x.tags.append('Label_'+x.labels)
alldata.extend(test)
else: # no label information is available, pure unsupervised learning
alldata = alldocs[:]
d2v = net.trainDoc2Vec(alldata, workers=workers, size=size, dm=dm, passes=passes, min_count=min_count)
raw_walks, netwalks = net.getdeepwalks(directory, number_walks=20, walk_length=8)
w2v = net.trainWord2Vec(raw_walks, buildvoc=1, passes=passes, size=size, workers=workers)
if train_size > 0: #Print out the initial results
#print('Initialize Doc2Vec Model With Supervised Information...')
Evaluation.evaluationEmbedModelFromTrainTest(d2v, train, test, classifierStr='SVM')
#print('Initialize Deep Walk Model')
Evaluation.evaluationEmbedModelFromTrainTest(w2v, train, test, classifierStr='SVM')
self.d2v = d2v
self.w2v = w2v
self.train(d2v, w2v, directory, alldata, passes=passes, weight=textweight)
if textweight > 0.5:
self.model = d2v
else:
self.model = w2v
def setWeights(self, orignialModel, destModel, weight=1):
if isinstance(orignialModel, Doc2Vec):
#print('Copy Weights from Doc2Vec to Word2Vec')
# destModel.reset_weights()
doctags = orignialModel.docvecs.doctags
keys = destModel.wv.vocab.keys()
for key in keys:
if not doctags.__contains__(key):
continue
#index = doctags[key].index # Doc2Vec index
index = list(doctags.keys()).index(key)
#print('index',index)
#print(type(index))
id = destModel.wv.vocab[key].index # Word2Vec index
id = int(id)
destModel.wv.syn0[id] = (1-weight) * destModel.wv.syn0[id] + weight * orignialModel.docvecs.doctag_syn0[index]
#destModel.syn0_lockf[id] = orignialModel.docvecs.doctag_syn0_lockf[index]
destModel.trainables.vectors_lockf[id] = orignialModel.trainables.vectors_docs_lockf[index]
else: # orignialModel is a word2vec instance only
#print('Copy Weights from Word2Vec to Doc2Vec')
assert isinstance(destModel, Doc2Vec)
doctags = destModel.docvecs.doctags
keys = orignialModel.wv.vocab.keys()
for key in keys:
if not doctags.__contains__(key):
continue
index = list(doctags.keys()).index(key) # Doc2Vec index
id = orignialModel.wv.vocab[key].index # Word2Vec index
destModel.docvecs.doctag_syn0[index] = (1-weight) * destModel.docvecs.doctag_syn0[index] + weight * orignialModel.wv.syn0[id]
#destModel.docvecs.doctag_syn0_lockf[index] = orignialModel.syn0_lockf[id]
destModel.trainables.vectors_docs_lockf[index] = orignialModel.trainables.vectors_lockf[id]
def train(self, d2v, w2v, directory, alldata, passes=10, weight=0.9):
raw_walks, walks = net.getdeepwalks(directory, number_walks=20, walk_length=10)
for i in range(passes):
#print('Iterative Runing %d' % i)
self.setWeights(d2v, w2v, weight=weight)
#Train Word2Vec
shuffle(raw_walks)
#print("Update W2V...")
w2v.train(raw_walks,total_examples=w2v.corpus_count,epochs=w2v.epochs)
self.setWeights(w2v, d2v, weight=(1-weight))
#print("Update D2V...")
shuffle(alldata) # shuffling gets best results
d2v.train(alldata,total_examples=d2v.corpus_count,epochs=d2v.epochs)















 1206
1206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









