







转换列表是一个很常见的需求,因此Python提供了一个工具。可以尽可能毫不费力第完成这种转换。工具名称:列表推导(list comprehension)设计列表推导是为了减少将一个列表转换为另一个列表时所需编写的代码量。

一些例子:
>>> mins = [1,2,3]
>>> secs = [m*60 for m in mins]
>>> secs
[60, 120, 180]
>>> lower = ["I","don't","like","spam"]
>>> upper = [s.upper() for s in lower]
>>> upper
['I', "DON'T", 'LIKE', 'SPAM']
>>> dirty = ['2-22','2:33','2.22']
>>> clean = [nester.sanitize(t) for t in dirty]
>>> clean
['2.22', '2.33', '2.22']
>>> clean = [float(s) for s in clean]
>>> clean
[2.22, 2.33, 2.22]上一篇博客中的代码可用列表推导修改为:
print(sorted([float(nester.sanitize(t)) for t in james_list]))
[2.01, 2.01, 2.22, 2.34, 2.34, 2.45, 3.01, 3.1, 3.21]=============================================================
那么如何拿到排名前三的数据项,而且保证没有重复呢?
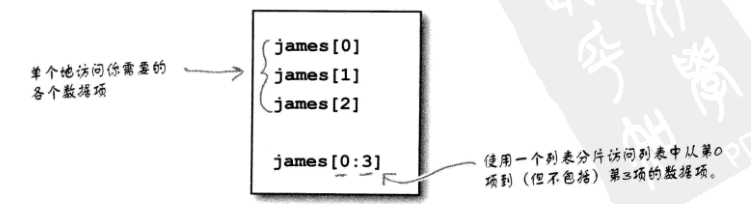
迭代删除重复项
重复项删除过滤器需要在列表创建过程中检查所创建的列表,这对于列表推导来说是无法做到的。
为了满足这个新需求,你需要求助于常规的列表迭代代码。
james_new_list = sorted([float(nester.sanitize(t)) for t in james_list])
james_unique_list = []
for each_t in james_new_list:
if each_t not in james_unique_list:
james_unique_list.append(each_t)
print(james_unique_list[0:3])运行结果:
[2.01, 2.22, 2.34]用集合删除重复项
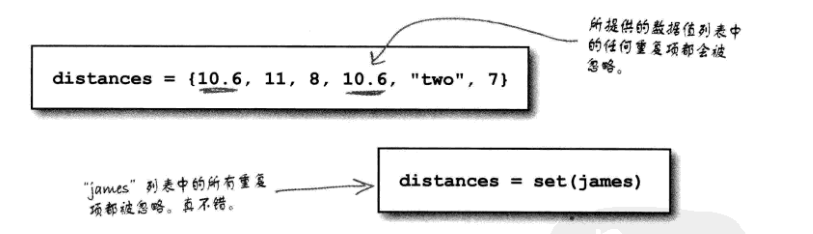
Python中集合最突出的特性是结合中的数据项是无序的,而且不允许重复。如果试图向一个集合增加一个数据项,而该集合中已经包含有这个数据项,Python就会将其忽略。
使用set()BIF创建一个空集合,这是工厂函数的一个例子:
distances = set()
>>> james_unique_list = set(james_new_list)
>>> james_unique_list
{2.22, 3.1, 3.21, 2.01, 3.01, 2.34, 2.45}
>>> print(sorted(james_unique_list)[0:3])
[2.01, 2.22, 2.34]















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









