









上篇博客对树结构的基本性质进行了讨论,并介绍了些二叉树的一些特性,接下来将会更深入的讨论二叉树的一些基本特性。
一、二叉树基础
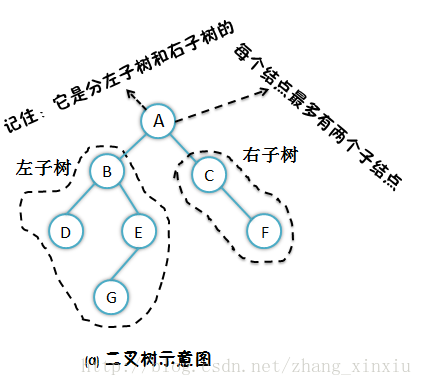
从上图能发现二叉树的哪些性质吗?对于这些很基础的性质就不在详述了,想想看。
1、二叉树的遍历
和树类似,二叉树能够遍历结点,但二叉树遍历的方式和树有点小小的差别,因为二叉树的特殊性,它分为左子树和右子树,在遍历时也是依照先左后右的原则遍历结点,另外二叉树在树的基础上增加了后序遍历,如下图。
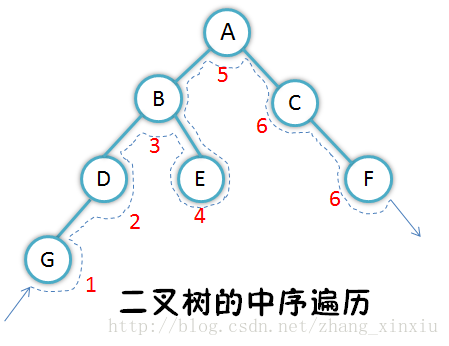
-
二叉树的中序遍历算法
void InOrder(BiTree root){
if(root !=null){
InOrder(root->child);/*中序遍历根结点的左子树*/
printf("%d",root->data);/*访问根结点*/
InOrder(root->rchild);/*中序遍历根结点的右子树*/
}/*if*/
} /*InOrder*/
二叉树的其它遍历算法(具体过程和上篇博客中树的遍历类似)
-
先序遍历
/*二叉树的先序遍历*/
void PreOrder(BiTree root){
if(root!=null){
printf("%d",root->data);/*访问根结点*/
PreOrder(root->lchild);/*先序遍历根结点的左子树*/
PreOrder(root->rchild);/*先序遍历根结点的右子树*/
}/*if*/
} /*PreOrder*/
-
后序遍历
void PostOrder(BiTree root){
if(root!=null){
PostOrder(root->lchild);/*后序遍历根结点的左子树*/
PostOrder(root->rchild);/*后序遍历根结点的右子树*/
printf("%d",root->data);/*后序根结点*/
}/*if*/
} /*PostOrder*/
-
层序遍历
/*二叉树的层序遍历*/
void LevelOrder(BiTree root){
Bitree p;
InitQueue(Q); /*创建一个空队列*/
EnQueue(Q,root); /*将根指针加入队列*/
while(!Empty(Q)){ /*队列不空*/
DeQueue(Q,p); /*队头元素出队,并使p取队头元素的值*/
printf("%d",p->data); /*访问结点*/
if(p->lchild)
EnQueue(p->lchild);
if(p->rchild)
EnQueue(p->rchild);
}/*while*/
} /*LevelOrder*/
-
二叉树的非递归遍历算法
int InOrderTraverse(BiTree root) /*二叉树的非递归遍历算法*/
{ BitTree p;
InitStack(St);
p=root; /*p指向树根结点*/
while(p!=NULL || !StackEmpty(St){
if(p!=NULL) /*不是空树*/
{
Push(St,p); /*根结点指针入栈*/
p=p->lchild; /*进入根的左子树*/
}
else{
q=Top(St); Pop(st); /*栈顶元素出栈*/
printf("%d",q->data); /*访问根结点*/
p=q->rchild; /*进入根的右子树*/
}/*if*/
}/*while*/
} /*InOrderTravers*/
二叉树是特殊的树结构,他们之间可以相互转换,那让我们看看如何将树转换为二叉树。
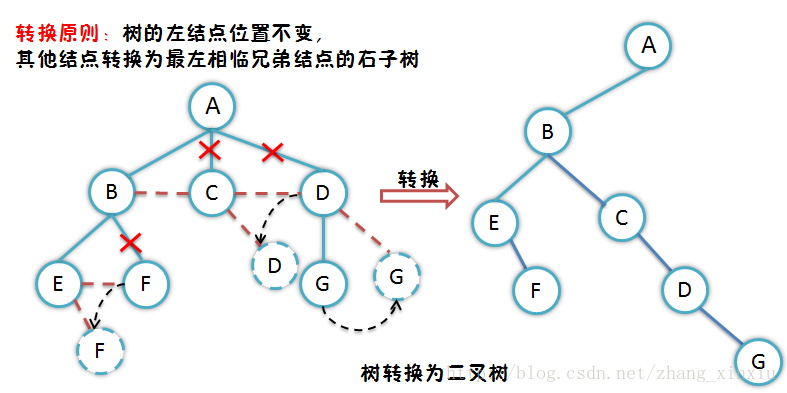
其实二叉树也被分为很多种的……
上面介绍了二叉树的一些基本概念和性质,其实二叉树的东西远非这些,只是把一些基础的和需要注意的讲解了一遍。
一些大神又把二叉树进行了细分,这些概念的划分可能是基于查找方便,最小浪费空间的原则,它们分别是二叉排序树、最优二叉树、平衡二叉树、线索二叉树,这些概念的划分中蕴含了大道理。
二、先从二叉排序树开始吧!
二叉排序树是一种特殊的排好序的树结构,它需要结点的权值大于左子树的所有结点权值,并小于右子树的所有结点的权值。所以它的每一个左右子树又是一棵二叉排序树。
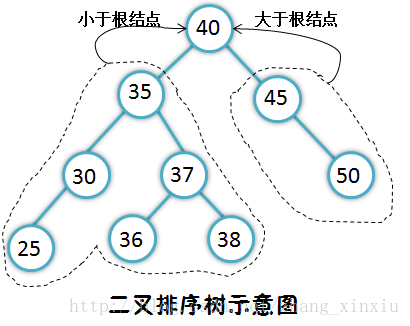
从上图中能看出二叉排序树的一些特性吗?
设二叉排序树采用二叉链表存储,结点的类型定义如下:
Typedef struct Tnode{
int data;/*结点的关键字值*/
struct Tnode *lchild,*rchild;/*指向左、右子树的指针*/
}Tnode,*Bitree;
1、需要关心的是二叉排序树的操作
这些操作和线性结构相同,包括基本的查找、插入和删除操作,但是操作过程却和线性结构有着很大的区别。
1.1 查找
查找操作分为静态查找和动态查找两种,从字面意思上能够看出这两种查找方式是不同的,静态查找其实是一种对比法,它每次利用结点值和给定值进行比较。而动态查找是为插入和删除需要而使用的查找,动态的查找每次都会改变表结构。
根据排序树的特殊情况,它会根据情况分配结点的子树。如果给定的键值大于根结点,下一步到根结点的左子树中进行查找,否则到根结点的右子树进行查找,然后继续依照情况分配下去。
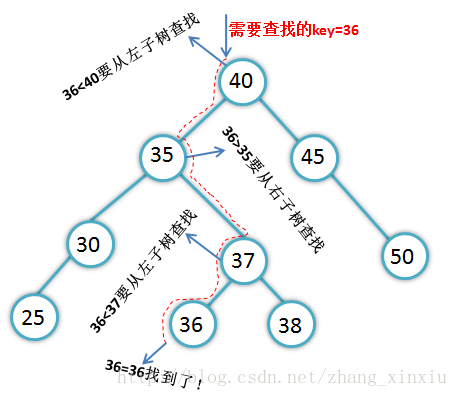
上图是查找成功的一个案例,如果将上面的36换成35最终会查找失败,因为树中没有关键字为35的结点。这种查找方法理解起来很简单,但这种查找和分序排列的思想却很重要,其中二分法查找就是利用了二叉排序树的这种查找思想进行查找的。
-
二叉排序树的查找算法:
Bitree SearchBST(Bitree root,int key,Bitree *father)
/*在root指向根的二叉排序树中查找键值为key的结点*/
/*若找到,则返回该结点的指针;否则返回空指针NULL*/
{
Bitree p=root;
*father=null;
while(p&&p->data!=key){
*father=p;
if(key<p->data){
p=p->lchild;
}
else{
p=p->rchild;
}/*if*/
}/*while*/
return p;
}/*SearchBST*/
二分法查找小介:把结点按照关键字大小顺序排列并确定中间值(中间值类似于二叉排序树中的根结点),把要查找的键值和中间值比较,如果大于中间值将会转入右子表中比较查询,反之进入左子表,然后继续去中间值分配区间的操作。
2.2 插入
上面的查找理解了,那对于它的插入操作就很简单了,插入操作是建立在查找基础上的,每次插入的新结点都是二叉排序树上新的叶子结点。也就是说如果要插入某一个关键字首先会使用查找的方法确定要在哪个结点上插入(如果大于根结点则在左子树上插入,如果小于根结点则在右子树上),然后增加一个新的结点,另外插入操作是在叶子结点上进行的,所以不会改动其它结点。具体操作如下图:
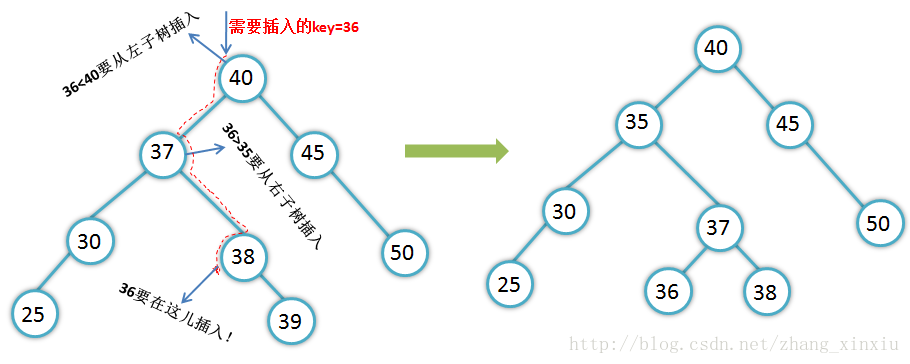
- 插入算法:
int InsertBST(Bitree *root,int e)
/*在*root指向根的二叉排序树中插入一个键值为e的结点,若插入成功返回0,否则返回-1*/
{
Bitree s,p,f;
s=(Bitree)malloc(sizeof(Tnode));
if(s==null)
retrun -1;
s->data=e;
s->lchild=null;
s->rchild=null;
p=SearchBST(*root,e,&f);/*寻找插入位置*/
if(p!=null)/*键值为e的结点已在树中,不再插入*/
return -1;
if(f==null)/*若为空树,键值为e的结点为树根*/
*root=s;
else
if(e<f->data)
f->lchild=s; /*作为父结点的左孩子插入*/
else
f->rchild=s;/*作为父结点的右孩子插入*/
return 0;
} /*InsertBST*/
3.3 删除
分析完了排序树的查找和插入操作后是不是感觉很容易?其实上面两个操作都是建立在查找操作基础上的,只不过每次插入的结点都是在树的叶子结点上进行,而且每次插入一个记录后不需要移动其它记录,想一想是不是特别类似于线性结构的链表类型,所以二叉排序树适用于使用链表结构存储。但是对于接下来的插入操作却有不同的操作。
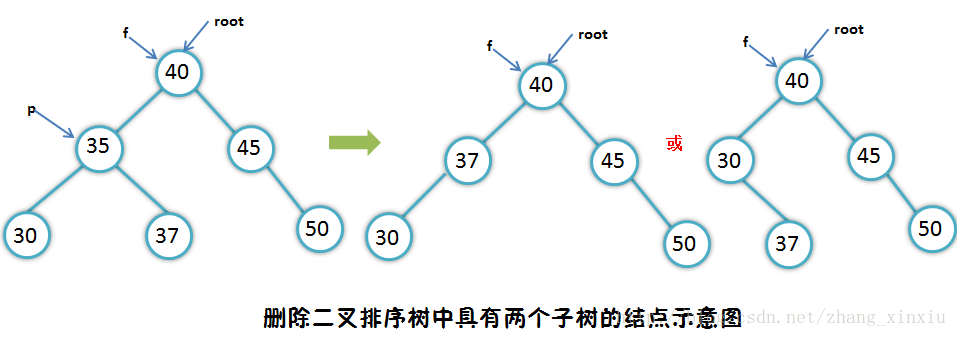
假设二叉排序树需要删除结点*p,*f为其双亲结点,则操作可分为三种情况:*p为叶子结点;*p结点只有左子树或只有右子树;*p同时具有左右子树。
-
*p为叶子结点,这种情况很简单,只需要将双亲结点的子结点值为空即可:f->lchild(f->rchild)=null;
-
*p有左子树或右子树,这种情况也不复杂,删除后要把*p的子树变为*f的子树。
f->lchild(或f->rchild)=p->lchild;/*p如果有左子树*/
f->lchild(或f->rchild)=p->rchild;/*p如果有右子树*/
-
*p同时拥有左右子树,一是用*p的中序直接前驱(或后继)结点*s代替*p结点,然后删除*s结点;二是领*p的左子树为*f的左子树(若*p是*f的左子树,否则为右子树),而将*p的右子树下接到中序遍历时*p的直接前驱结点*s(*s结点是*p的左子树中最右下方的结点)的右孩子指针上。
三、结语
上面把二叉树结构的基本特性进行了探讨,但为什么没有将二叉树有关的存储结构拿出来探讨呢?主要是因为二叉树的存储结构其实和树是差不多的,即使说了用处也不大,尽量减少记忆量。然后加上了些有关二叉树遍历的一些算法,这些算法可以不用掌握,主要是为了对以后学习算法的时候不至于感觉很难,这儿介绍的一些算法也是为了以后学习算法打下基础。另外对二叉排序树的基本特性进行了探讨,其中主要是二叉排序树的动态查找的一些算法。
接下来进入最优二叉树部分。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









