







spark之非唯一键下TopN算法
什么是非唯一键,假设所有给定的
(
K
,
V
)
(K,V)
(K,V)中,
K
K
K不唯一,所以必须增加额外的步骤来确保在TopN算法中键是唯一的,
举个例子,假设有三个Web服务器(服务器1,服务器2,服务器3),每个服务器采取以下形式收集URL:
(URL,count)
对应各个Web服务器的(URL,count)如下
| 服务器1 | 服务器2 | 服务器3 |
|---|---|---|
| (A,2) | (A,1) | (A,2) |
| (B,2) | (B,1) | (B,2) |
| (C,3) | (C,3) | C,1) |
| (D,2) | (E,1) | (D,2) |
| (E,1) | (F,1) | (E,1) |
| (G,2) | (G,2) | (F,1) |
| (G,2) |
假设希望获取最常访问的2个URL,如果先得到各个服务器的本地Top2,然后再计算所得到的3个本地Top2列表中的Top2,这个结果并不一定正确,原因是所有web服务器上的所有URL并不唯一。要想得到相同的结果,受邀要使得所有输入创建衣服唯一的URL,然后这些唯一的URL分区到 M ( > 0 ) M(>0) M(>0)个分区,接下来得到对应的各个分区的本地TopN,最后在本地TopN列表中确定最后topN,如下所示
聚集 (URL,count)对
(A,5)
(B,5)
(C,7)
(D,4)
(E,3)
(F,2)
(G,6)
假设被分到两个分区以后,如下所示
| 分区1 | 分区2 |
|---|---|
| (A,5) | (D,4) |
| (B,4) | (E,3) |
| (C,7) | (F,2) |
| (G,6) |
完整代码如下
package TopN
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.SortedMap
object TopNunUnique {
def main(args: Array[String]): Unit={
//初始化spark
val sparkConf=new SparkConf().setAppName("TopN").setMaster("local")
val sc=new SparkContext(sparkConf)
//将top广播到所有集群节点
val N=sc.broadcast(2)
val path="input/topNunUnique.txt"
//创建一个RDD
val input=sc.textFile(path)
//将输入映射到(key,value)
val kv = input.map(line => {
val tokens = line.split(",")
(tokens(0), tokens(1).toInt)
})
//归约重复键盘
val uniqueKeys=kv.reduceByKey(_+_)
//创建本地TopN
val parations=uniqueKeys.mapPartitions(itr=>{
var sortedMap=SortedMap.empty[Int,String]
itr.foreach{tuple=>
{
sortedMap+=tuple.swap
if(sortedMap.size>N.value){
sortedMap=sortedMap.takeRight(N.value)
}
}
}
sortedMap.takeRight(N.value).toIterator
})
//分布式下进行聚合操作
val createCombiner=(v : Int)=>v
val mergeValue=(a: Int,b: Int)=>(a+b)
val moreApproach=kv.combineByKeyWithClassTag(createCombiner,mergeValue,mergeValue)
.map(_.swap)
.groupByKey()
.sortByKey(false)
.take(N.value)
moreApproach.foreach{
case(k,v)=>println(s"$k \t ${v.mkString(",")}")
}
}
}
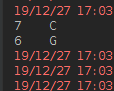
运行结果如下














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









