







MapReduce之计数器计数
模式描述
这是使用Mapreduce框架自身的计数器在不产生任何输出的情况下,在map端计算一个全局的计数,是得到大数据集计数概要的一种高效方法
适用场景
因为计数器信息都是存储在 JobTracker的内存中,每个map任务中的计数器被序列化,并通过状态更新同步到 JobTracker,为了JobTracker正常工作产生影响,计数器的数目族号在几十个内,所以适用场景为
- 在一个大数据集上收集计数或汇总
- 需要创建的计数器数目很小
问题描述
数据集中包含用户的ID以及用户所在的州的名称,这次只用map作业来完成统计数据中每个州的用户数。
样例输入
创建输入文档的代码如下:
import java.io.*;
import java.util.Random;
public class create {
// 美国的51个州和没有归属地Unknown
public static String getStates() {
String[] states={"Alabama","Alaska","Arizona","Arkansas","California",
"Colorado","Connecticut","Delaware","District of Columbia","Florida",
"Georgia","Hawaii","Idaho","Illinois","Indiana","Iowa","Kansas","Kentucky",
"Louisiana","Maine","Maryland","Massachusetts","Michigan","Minnesota","Mississippi",
"Missouri","Montana","Nebraska","Nevada","New Hampshire","New Jersey","New Mexico","New York",
"North Carolina","North Dakota","Ohio","Oklahoma","Oregon","Pennsylvania","Rhode Island","South Carolina",
"South Dakota","Tennessee","Texas","Utah","Vermont","Virginia","Washington","West Virginia","Wisconsin",
"Wyoming","Unknow" };
Random random=new Random();
StringBuffer buffer=new StringBuffer();
buffer.append(states[random.nextInt(52)]);
return buffer.toString();
}
public static void main(String[] args) throws IOException{
String path="input/file.txt";
File file=new File(path);
if(!file.exists()){
file.getParentFile().mkdirs();
}
file.createNewFile();
FileWriter fw=new FileWriter(file,true);
BufferedWriter bw=new BufferedWriter(fw);
//生成1000行数据
for(int i=0;i<1000;i++){
int id=(int)(Math.random()*1000+1000);
bw.write("< id="+id+" location="+getStates()+" >\n");
}
bw.flush();
bw.close();;
fw.close();;
}
}
运行结果如下

样例输出
数据集随即生成,在控制台显示的结果可能不一样
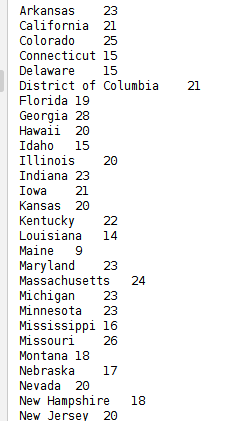
mapper阶段任务
map阶段的代码获取每个用户所在的位置信息,使用分组和名称对计数器进行表示,如果被表示到,则这个州的计数器就加1
mapper阶段编码如下
public static class CountNumMapper extends Mapper<Object,Text,Text,Text>{
//分组
public static final String STATE_COUNTER_GROUP="State";
public static final String UNKNOWN_COUNTER="Unknown";
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
String line=value.toString();
String state=line.substring(20,line.length()-2);
boolean unknown=true;
if(state!="Unknown"){
unknown=false;
}
context.getCounter(STATE_COUNTER_GROUP,state).increment(1);
if(unknown){
context.getCounter(STATE_COUNTER_GROUP,UNKNOWN_COUNTER).increment(1);
}
}
}
reducer阶段任务
无
完整代码如下
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Counter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.omg.IOP.IOR;
import java.io.IOException;
public class CountNum {
public static class CountNumMapper extends Mapper<Object,Text,Text,Text>{
public static final String STATE_COUNTER_GROUP="State";
public static final String UNKNOWN_COUNTER="Unknown";
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
String line=value.toString();
String state=line.substring(20,line.length()-2);
boolean unknown=true;
if(state!="Unknown"){
unknown=false;
}
context.getCounter(STATE_COUNTER_GROUP,state).increment(1);
if(unknown){
context.getCounter(STATE_COUNTER_GROUP,UNKNOWN_COUNTER).increment(1);
}
}
}
public static void main(String[] args) throws Exception{
FileUtil.deleteDir("output");
Configuration configuration=new Configuration();
String[] otherArgs=new String[]{"input/file.txt","output"};
if(otherArgs.length!=2){
System.err.println("参数错误");
System.exit(2);
}
Job job=new Job(configuration,"CountNum");
job.setJarByClass(CountNum.class);
job.setMapperClass(CountNumMapper.class);
job.setOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
FileInputFormat.addInputPath(job,new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
int code=job.waitForCompletion(true)?0:1;
if(code==0){
for(Counter counter:job.getCounters().getGroup(CountNumMapper.STATE_COUNTER_GROUP)){
System.out.println(counter.getDisplayName()+"\t"+counter.getValue());
}
}
System.exit(code);
}
}
写在最后
计数器模式只适合计数器小而且快速查询的情况















 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









