






前言:Pytorch是目前学术界使用较为广泛的一种深度学习框架,要想能够熟练使用这个工具,就需要对它有一个全面系统的了解,本专栏就是为了带领大家系统地梳理Pytorch工具中的一些重要知识点,欢迎各位读者批评指正。
目录
1、Pytorch的数据读取机制
1.1数据
深度学习项目主要由数据、模型、损失函数、优化器以及迭代训练五个模块组成。很明显本小节要讲的Pytorch数据读取机制就是数据模块主要分支中的一个,数据模块包含的内容如下图1所示。Pytorch有一套自己的数据读取方式,就是通过DataLoader来完成的。
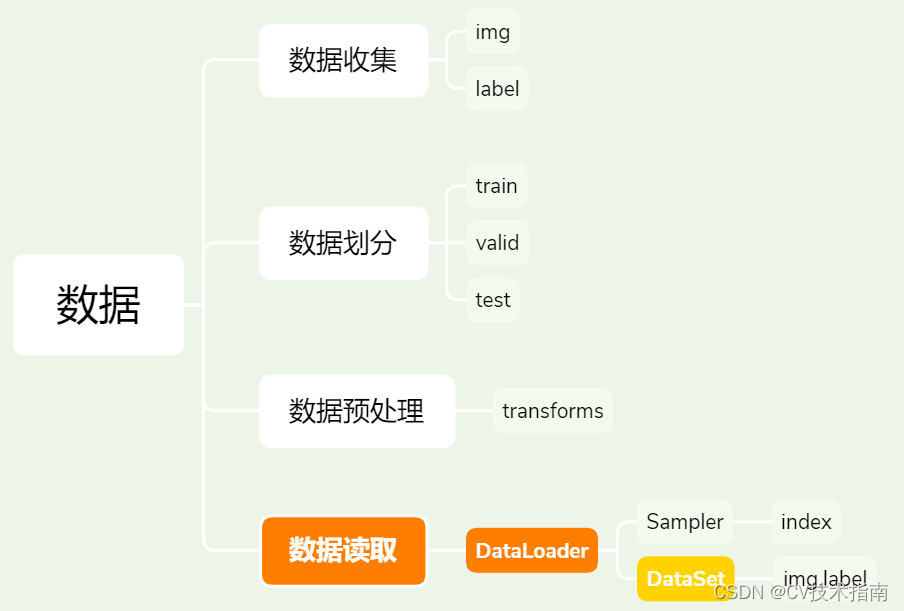
图1
1.2 DataLoader
torch.utils.data.DataLoader():构建可迭代的数据装载器, 我们在训练的时候,每一个for循环,每一次iteration,就是从DataLoader中获取一个batch_size大小的数据的。

DataLoader中常用的参数主要有下面5个:
①dataset: 继承于Dataset类, 决定数据从哪读取以及如何读取
②bathsize: 批大小
③num_works: 是否多进程读取机制
④shuffle: 每个epoch是否乱序
⑤drop_last: 当样本数不能被batchsize整除时, 是否舍弃最后一批数据
DataLoader数据读取机制的逻辑是按这3个问题进行下去的:
1)读哪些数据? 我们每一次迭代要去读取一个batch_size大小的样本,那么读哪些样本呢?
2)从哪读数据? 也就是在硬盘当中该怎么去找数据,在哪设置这个参数。
3)怎么读数据?也就是通过什么方式来读取到数据。
针对第一个问题, DataLoader是通过自动调用Pytorch内部自带的sampler.py文件来获取每个batch要读取样本的索引的;
针对第二,第三个问题,DataLoader是通过调用Dataset类中的函数来实现的,这里我们必须写一个类来继承Pytorch中的Dataset类,并且必须覆盖重写__init__(),__getitem__(),__len__()三个方法。
1.3 Dataset
dataset(继承于Dataset)是DataLoader实例化的一个参数,是需要我们自己用代码实现的一个类,这个类中主要包括__init__(),__getitem__(),__len__()这三个函数:
1)__init__():相当于Java中类的构造函数,主要解决从哪里读取数据的问题,也就是说该函数里面会定义存放数据的路径;
2)__getitem__():这个函数主要解决怎么读取数据的问题,就是通过传入的索引Index来读取;
3)__len__():这个函数主要用来获取数据集中样本的总个数,要不然没法根据batchsize去确定一共有多少批数据。
讲到这里,Pytorch的DataLoader数据读取机制思路基本上理清楚了,接下来谈一谈图像预处理模块(transforms)。
2、图像预处理模块(transforms)
transforms中包含了各种常用的图像预处理方法,存放在torchvision这个计算机视觉工具包中,具体见Pytorch官网
https://pytorch.org/vision/stable/index.html
,主要包括以下方法:
2.1图像变换
①transforms.Pad(padding, fill=0, padding_mode=‘constant’): 对图片边缘进行填充
②transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0):调整亮度、对比度、饱和度和色相, 这个是比较实用的方法, brightness是亮度调节因子, contrast对比度参数, saturation饱和度参数, hue是色相因子。
③transfor.RandomGrayscale(num_output_channels, p=0.1): 依概率将图片转换为灰度图, 第一个参数是通道数, 只能1或3, p是概率值,转换为灰度图像的概率
④transforms.RandomAffine(degrees, translate=None, scale=None, shear=None, resample=False, fillcolor=0): 对图像进行仿射变换, 反射变换是二维的线性变换, 由五中基本原子变换构成,分别是旋转,平移,缩放,错切和翻转。 degrees表示旋转角度, translate表示平移区间设置,scale表示缩放比例,fill_color填充颜色设置, shear表示错切
⑤transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False): 这个也比较实用, 对图像进行随机遮挡, p概率值,scale遮挡区域的面积, ratio遮挡区域长宽比。 随机遮挡有利于模型识别被遮挡的图片。value遮挡像素。 这个是对张量进行操作,所以需要先转成张量才能做
⑥transforms.Lambda(lambd): 用户自定义的lambda方法, lambd是一个匿名函数。lambda [arg1 [, arg2…argn]]: expression
⑦
transforms.Resize
方法改变图像大小
⑧
transforms.ToTensor
方法是将图像转换成张量,同时会进行归一化的一个操作,将张量的值从0-255转到0-1
⑨
transforms.Normalize
方法是将数据进行标准化
2.2图像裁剪
①transforms.CenterCrop(size): 图像中心裁剪图片, size是所需裁剪的图片尺寸,如果比原始图像大了, 会默认填充0。
②transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant): 从图片中位置随机裁剪出尺寸为size的图片, size是尺寸大小,padding设置填充大小(当为a, 上下左右均填充a个像素, 当为(a,b), 上下填充b个,左右填充a个,当为(a,b,c,d), 左,上,右,下分别填充a,b,c,d个), pad_if_need: 若图像小于设定的size, 则填充。 padding_mode表示填充模型, 有4种,constant像素值由fill设定, edge像素值由图像边缘像素设定,reflect镜像填充, symmetric也是镜像填充, 这俩镜像是怎么做的看官方文档吧。镜像操作就类似于复制图片的一部分进行填充。
③transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(3/4, 4/3), interpolation): 随机大小,长宽比裁剪图片。 scale表示随机裁剪面积比例,ratio随机长宽比, interpolation表示插值方法。
④FiveCrop, TenCrop: 在图像的上下左右及中心裁剪出尺寸为size的5张图片,后者还在这5张图片的基础上再水平或者垂直镜像得到10张图片。
2.3图像翻转与旋转
①RandomHorizontalFlip(p=0.5), RandomVerticalFlip(p=0.5): 依概率水平或者垂直翻转图片, p表示翻转概率
②RandomRotation(degrees, resample=False, expand=False, center=None):随机旋转图片, degrees表示旋转角度 , resample表示重采样方法, expand表示是否扩大图片,以保持原图信息。
另外,
transforms.Compose
方法是将一系列的transforms方法进行有序的组合包装,具体实现的时候,依次的用包装的方法对图像进行操作,其它更多的图像预处理方法还得参照Pytorch官网。图像预处理模块(transforms)的功能函数一般在__getitem__()方法中实现,在根据索引Index读取到图片数据后,就可以对图像进行相应的预处理工作了。
3、用Pytorch构造自己的数据集(代码实现)
3.1准备数据
以KolektorSDD数据集为例,下载好该数据集,其存放格式如下图2所示,并将数据集划分为分Train_OK,Train_NG,Test三个文件夹分别保存。

图2
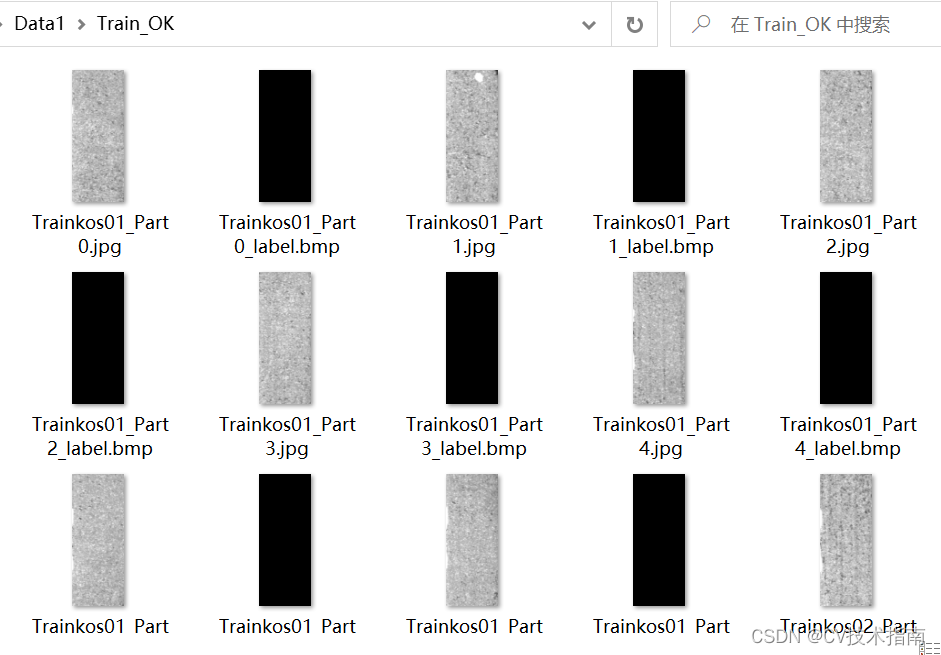
Train_OK

Train_NG
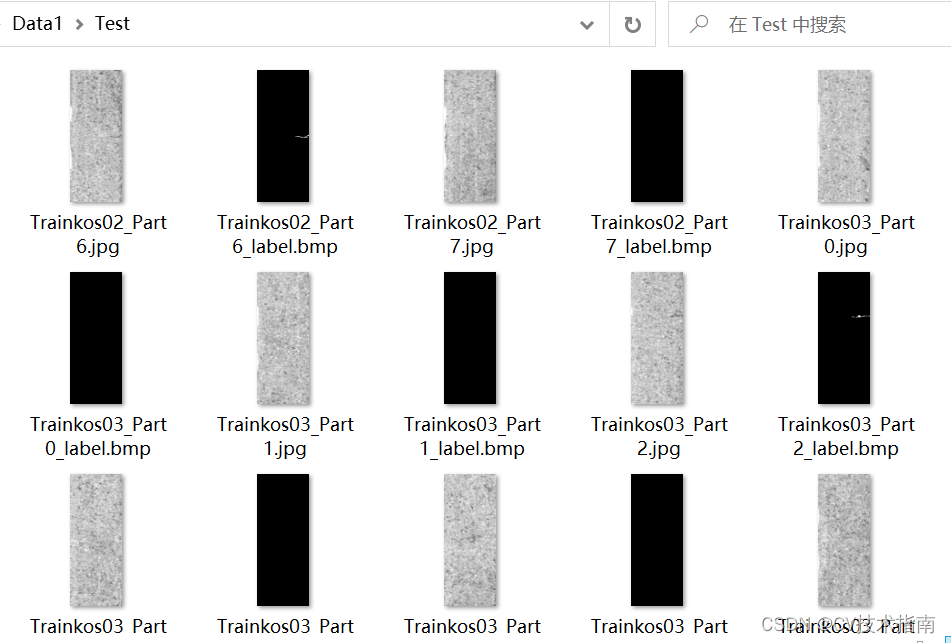
Test
3.2读取数据并进行图像预处理
该过程代码实现如下:
import cv2
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
import torchvision.transforms.functional as VF
class KolektorDataset(Dataset):
def __init__(self, dataRoot, transforms_=None, transforms_mask=None, subFold="Train_NG", isTrain=True):
self.isTrain = isTrain
if transforms_mask == None:
self.maskTransform = transforms.Compose([transforms.ToTensor()])
# transforms.Compose作用是组合几个变换方法,按顺序变换相应数据。
# 转换一个PIL库的图片或者numpy的数组为tensor张量类型
else:
self.maskTransform = transforms_mask
if transforms_ == None:
self.transform = self.maskTransform
else:
self.transform = transforms_
self.imgFiles = sorted(glob.glob(os.path.join(dataRoot, subFold) + "/*.jpg"))
#sorted() 函数对所有可迭代的对象进行排序操作。
#sort 与 sorted 区别:sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
#list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,
# 而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
if isTrain:
# self.labelFiles = sorted(glob.glob(os.path.join(dataRoot, subFold) + "/*.jpg"))原代码是这样写的
self.labelFiles = sorted(glob.glob(os.path.join(dataRoot, subFold) + "/*.bmp"))
self.len = len(self.imgFiles)
def __getitem__(self, index):
idx = index % self.len#这条语句存在的意义是:坏样本数量少于好样本,在交替训练时会训一轮好样本需要训多轮坏样本,
# 下面的水平垂直翻转也是因为这个原因,增加样本的多样性
if self.isTrain == True:
img = Image.open(self.imgFiles[idx]).convert("RGB")
# mask = Image.open(self.labelFiles[idx]).convert("RGB")
mat = cv2.imread(self.labelFiles[idx], cv2.IMREAD_GRAYSCALE)
#此处进行形态学膨胀操作作用就是扩大label的白色区域面积,图像增强
kernel = np.ones((5, 5), np.uint8)
matD = cv2.dilate(mat, kernel)
#dilate()函数可以对输入图像用特定结构元素进行膨胀操作,该结构元素确定膨胀操作过程中的邻域的形状,
#各点像素值将被替换为对应邻域上的最大值:
mask = Image.fromarray(matD) # image2 is a PIL image
#就是实现array到image的转换
if np.random.rand(1) > 0.5:#np.random.rand返回一个或一组服从“0~1”均匀分布的随机样本值。
mask = VF.hflip(mask)#hflip()函数功能是实现水平翻转
img = VF.hflip(img)
if np.random.rand(1) < 0.5:
mask = VF.vflip(mask)#vflip()函数功能是实现垂直翻转
img = VF.vflip(img)
img = self.transform(img)
mask = self.maskTransform(mask)
return {"img": img, "mask": mask}
else:
img = Image.open(self.imgFiles[idx]).convert("RGB")
img = self.transform(img)
return {"img": img}
def __len__(self):
return len(self.imgFiles)















 1454
1454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









