









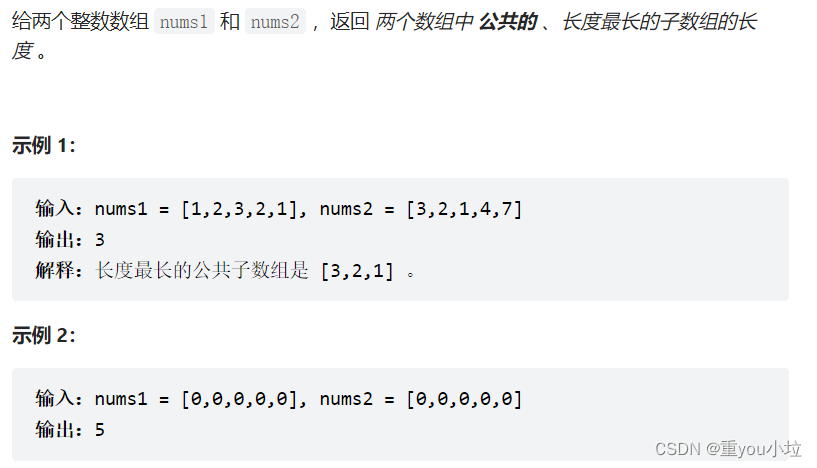

思路一:dp O(n*m)
dp[i][j]表示 nums1[0…i]与 nums2[0…j]的最长重复子数组
转移方程:
如果nums1[i] == nums2[j]:dp[i][j] = dp[i-1][j-1]+1
否则:dp[i][j] = 0
ans:dp数组中的最大值
class Solution {
public:
int findLength(vector<int>& nums1, vector<int>& nums2) {
int n = nums1.size(), m = nums2.size();
vector<vector<int>> dp(n + 1, vector<int>(m + 1));
int ans = 0;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < m; ++j) {
if (nums1[i] == nums2[j]) dp[i + 1][j + 1] = dp[i][j] + 1;
else dp[i + 1][j + 1] = 0;
ans = max(ans, dp[i + 1][j + 1]);
}
}
return ans;
}
};
//最长重复子序列的代码:
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
vector<vector<int>> dp(text1.size()+1, vector<int>(text2.size()+1));
int len1 = text1.size();
int len2 = text2.size();
for (int i = 0; i < len1; ++i) {
for (int j = 0; j < len2; ++j) {
if (text1[i] == text2[j]) {
dp[i + 1][j + 1] = dp[i][j] + 1;
}else {
dp[i + 1][j + 1] = max(dp[i + 1][j], dp[i][j + 1]);
}
}
}
return dp[len1][len2];
}
};
思路二:二分+字符串hash O(nlogm)
具体思路:二分长度k 然后判断是否存在长度为k的子数组(字符串hash)
class Solution {
public:
using ull = unsigned long long;
const int base = 131;
bool check(vector<ull>&hash1, vector<ull>& hash2, vector<ull>& pow,int mid) {
int n = hash1.size() - 1, m = hash2.size() - 1;
unordered_set<ull> uset;
auto get1 = [&](int l, int r) {return hash1[r]-hash1[l-1]*pow[r-l+1];}; //
auto get2 = [&](int l, int r) {return hash2[r]-hash2[l-1]*pow[r-l+1];};
for (int i = 0; i <= m - mid; ++i) {
uset.insert(get2(i + 1, i + mid)); //
}
for (int i = 0; i <= n - mid; ++i) {
if (uset.count(get1(i + 1, i + mid))) return true;
}
return false;
}
int findLength(vector<int>& nums1, vector<int>& nums2) {
if (nums1.size() < nums2.size()) swap(nums1, nums2);
int n = nums1.size(), m = nums2.size();
vector<ull> hash1(n + 1), hash2(m + 1);
vector<ull> pow(n + 1);
pow[0] = 1;
for (int i = 0; i < n; ++i) {
hash1[i + 1] = hash1[i] * base + nums1[i] + 1;
if (i < m) hash2[i + 1] = hash2[i] * base + nums2[i] + 1; //
pow[i + 1] = pow[i] * base;
}
int l = 0, r = m + 1;
while (l + 1 < r) {
int mid = l + (r - l) / 2;
if (check(hash1, hash2, pow, mid)) l = mid;
else r = mid;
}
return l;
}
};
代码上的易错点:
1:防止[0, 0] 跟 [0] 区分不开,因此0应该映射到1,因此hash2[i] * base + nums2[i]要 + 1
2:得[l, r]之间的hash值时,pow[r - l + 1] 不要写成了 (r - l+ 1)
3:get(l, r) 得到的是 [l - 1, r - 1]的hash值,而不是 [l, r] 。
错误思路三:把nums2所有的子数组放到hash里面,然后判断nums1中是否有子数组在hash里面存在。
注意的是:放到hash和hash查找均是O(n)的做法,总体是O(n^3)的做法,因此通过用字符串hash来优化到 O(n^2)
然而,当hash内的元素过多,查找和插入要再考虑10倍的复杂度O(10),有O(10^7)的复杂度。















 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









