









图数据结构
首先我们先看看什么是图数据结构。
图数据结构它从数据上来看是点和边的集合,边则由点与点之间进行构造。
让我们通过一个例子来理解这一点。在 facebook 上,所有东西都是一个节点。这包括用户,照片,相册,事件,组,页面,评论,故事,视频,链接,注释… 任何有数据的都是一个节点。
每个关系都是从一个节点到另一个节点的边。无论你发布一张照片,加入一个群组,等等,就会创建一个新的边。
facebook里所有的数据都是这些节点和边缘的集合。这是因为 facebook 使用图数据结构来存储数据。图是一种数据结构(V,E) ,它由
顶点集合V,边的集合E(表示为顶点的有序对(u,v))
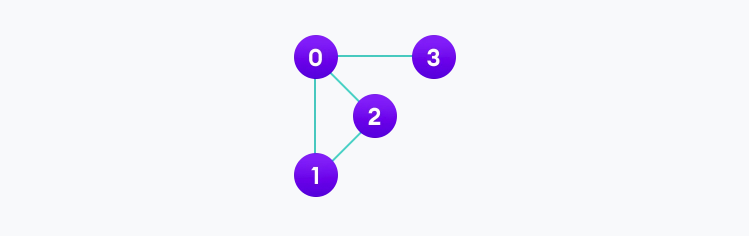
在上面这张图里的表示:
V = {0, 1, 2, 3}
E = {(0,1), (0,2), (0,3), (1,2)}
G = {V, E}
图用到的一些术语
-
邻接: 如果一个顶点与另一个顶点之间有一条边相连,那么这个顶点就是与另一个顶点就是相邻的。比如上面的图里面,顶点2和3不相邻,因为它们之间没有边。
-
路径: 允许你从顶点 A 到顶点 B 的一系列边称为路径。0-1,1-2和0-2是从顶点0到顶点2的路径。
-
有向图: 边(u,v)不一定意味着也有边(v,u)的图。这种图中的边用箭头表示,以显示边的方向。
图的表示方法
图有两种常见的表示方法:邻接表和邻接矩阵
1 邻接矩阵
邻接矩阵是由 V x V 顶点组成的二维数组,每一行和每一列代表一个顶点。
如果任何元素 a [ i ][ j ]的值为1,则表示存在连接顶点 i 和顶点 j 的边。
上面的图对应我们的邻接矩阵:
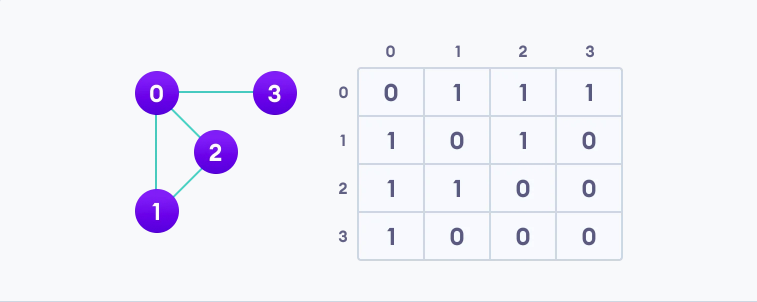
由于它是一个无向图,对于 edge (0,2) ,我们还需要对应生成对点的新边 edge (2,0) ,使邻接矩阵对角对称。
边查找(检查顶点 a 和顶点 b 之间是否存在边)在邻接矩阵上查找会非常快,但是我们必须为所有顶点(V x V)之间的每个可能的边进行存储,所以它需要比较大的存储空间。
2 邻接表
邻接表是将图表示为链表数组。
数组的索引表示一个顶点,其链表中的每个元素表示与该顶点形成边的其他顶点。
我们在第一个示例中创建的图的邻接列表如下:
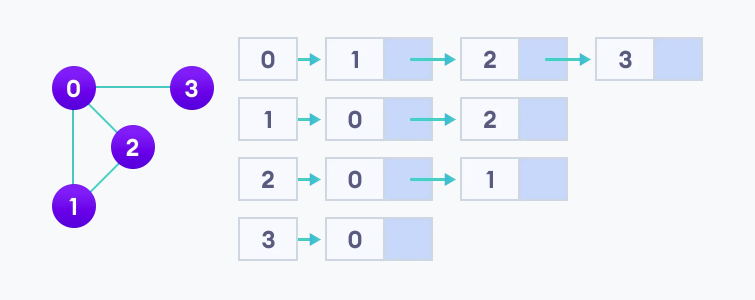
在存储方面,邻接列表从存储空间角度来看是更有效的,因为我们只需要存储边的值。对于一个有数百万个顶点的图来说,这意味着节省了大量的空间。
图的最基本操作
最常见的图上面的基础操作有:
向图中添加元素(顶点、边)
检查某个元素是否出现在图中,检查某个边是否存在
图的点的个数,度的个数,
某个点的出边
邻接矩阵代码表示法
邻接矩阵是一种将图表示为布尔矩阵(0和1)的方法。基本图可以在计算机上以矩阵的形式表示,其中矩阵的布尔值表示两个顶点之间是否有直接连接的路径。还是下面这个图:看看它的邻接矩阵表示:
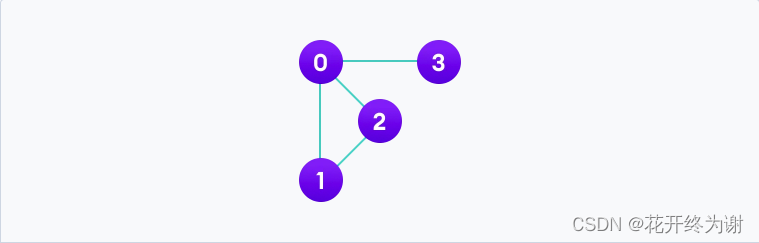

矩阵中的每个单元格都表示为 Aij,其中 i 和 j 是顶点。Aij 的值取决于顶点 i 到顶点 j 之间是否有边,取决于1或0。
如果有一条从 i 到 j 的路径,那么 Aij 的值为1,否则为0。例如,有一条从顶点1到顶点2的路径,所以 A12是1,没有从顶点1到3的路径,所以 A13是0。
对于无向图,矩阵对角线是对称的,因为每个边(i,j)都有一个边(j,i)。
邻接矩阵优点
-
基本的操作,比如添加一个边,移除一个边,以及检查是否有一个边从顶点 i 到顶点 j 是非常有效的时间,恒定的时间操作。
-
如果图形密集且边数很多,那么邻接矩阵应该是第一选择。即使图和邻接矩阵是稀疏的,我们也可以用稀疏矩阵的数据结构来表示它。
-
然而,最大的优势来自于矩阵的使用。硬件方面的最新进展使我们能够在 GPU 上执行甚至是昂贵的矩阵运算。
-
通过对邻接矩阵进行运算,我们可以深入了解图的本质及其顶点之间的关系。
邻接矩阵的缺点:
-
邻接矩阵的 VxV 空间要求让它占用大量内存。通常图没有太多的连接(是相对稀疏的),这种情况邻接表是其实是更好地选择。
-
虽然邻接矩阵基本操作很容易,但是使用邻接矩阵表示时,像 inEdges 和 outEdges 这样的操作代价很高。
邻接表的代码实现:
public class GraphMatrixDemo {
// 邻接矩阵
private int adj[][];
// 顶点个数
private int V;
public GraphMatrixDemo(int V) {
this.V = V;
adj = new int[V][V];
}
public void addEdge(int i, int j) {
adj[i][j] = 1;
adj[j][i] = 1;
}
public String toString() {
StringBuilder s = new StringBuilder();
for (int i = 0; i < V; i++) {
s.append(i).append(": ");
for (int j : adj[i]) {
s.append(j == 1 ? 1 : 0).append(" ");
}
s.append("\n");
}
return s.toString();
}
public static void main(String[] args) {
GraphMatrixDemo g = new GraphMatrixDemo(4);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(1, 2);
g.addEdge(2, 0);
g.addEdge(0, 3);
System.out.print(g.toString());
}
}
















 6086
6086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









