







 博客提出统计三个文件中每个词出现次数的需求,给出了文件内容示例,包含'map'、'reduce'、'MapReduce'等词汇。同时介绍了实现该统计的类定义,定义了index1类、Index2类,且Index2输入为Index1输出,还定义IndexMain类将二者串联。
博客提出统计三个文件中每个词出现次数的需求,给出了文件内容示例,包含'map'、'reduce'、'MapReduce'等词汇。同时介绍了实现该统计的类定义,定义了index1类、Index2类,且Index2输入为Index1输出,还定义IndexMain类将二者串联。
需求:有如下3个文件,统计出每个词在这三个文件中出现的次数
文件1:a.txt
map
reduce
MapReduce
index Inverted index
Inverted index
倒排索引
大数据
hadoop MapReduce hdfs
Inverted index
......
文件2:b.txt
hadoop MapReduce hdfs
Inverted index
倒排索引
大数据
map
reduce
MapReduce
......
文件3:c.txt
Inverted index
倒排索引
大数据
hadoop MapReduce hdfs
Inverted index
hadoop MapReduce hdfs
Inverted index
map
reduce
MapReduce
......
1:定义index1类
package Index;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
import java.net.URISyntaxException;
public class Index1 {
public static void main(String[] args) throws ClassNotFoundException, URISyntaxException, InterruptedException, IOException {
args = new String[]{"E:\\bigdata_code\\index", "E:\\bigdata_code\\index\\out1"};
//这里把job重新定义到一个类了,使用时,只需要输入相关参数
MyDriver.run2(Index1.class, Index1Map.class, Text.class, IntWritable.class,
Index1Reduce.class, Text.class, IntWritable.class, args[0], args[1]);
}
}
/**
* 倒排索引Map
* 数据内容:hadoop MapReduce hdfs
* 输出数据:hadoop--a.txt
*/
class Index1Map extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable();
String name;
//初始化,获取文件名
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit inputSplit = (FileSplit) context.getInputSplit();
name = inputSplit.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//获取数据:hadoop MapReduce hdfs
String line = value.toString();
//切分数据
String[] split = line.split(" ");
//拼接,关键字和文件名
for(String s:split){
k.set(s + "--" + name);
v.set(1); //1,出现一次
context.write(k,v);
}
}
}
/**
* reduce
* 获取Map数据:hadoop--a.txt 1
* 输出结果:hadoop--a.txt 2
*/
class Index1Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
//定义计数器,并初始化
int sum = 0;
for(IntWritable iw:values){
sum += iw.get();
}
v.set(sum);
//输出
context.write(key,v);
}
}
2:定义Index2类,Index2的输入数据是Index1的输出数据
package Index;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.net.URISyntaxException;
public class Index2 {
public static void main(String[] args) throws ClassNotFoundException, URISyntaxException, InterruptedException, IOException {
args = new String[]{"E:\\bigdata_code\\index\\out1", "E:\\bigdata_code\\index\\out2"};
MyDriver.run2(Index2.class, Index2Map.class, Text.class, Text.class,
Index2Reduce.class, Text.class, Text.class, args[0], args[1]);
}
}
/**
* hadoop--a.txt 2
* hadoop--b.txt 1
* hadoop--c.txt 3
*/
class Index2Map extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//获取数据
String line = value.toString();
//切分数据 "--"
String[] split = line.split("--");
k.set(split[0]);
v.set(split[1]);
context.write(k,v);
}
}
/**
* Reduce
* 获取Map数据:hadoop [a.txt 2,b.txt 1,c.txt 3]
* 输出结果:hadoop a.txt-->2 b.txt-->1 c.txt-->3
*
*/
class Index2Reduce extends Reducer<Text, Text, Text, Text >{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
for(Text t:values){
//a.txt 3
String[] split = t.toString().split("\t");
//数据从新 --> 拼接
String s = split[0] + "-->" + split[1];
sb.append(s).append("\t");
}
//输出
context.write(key, new Text(sb.toString()));
}
}
3:定义了IndexMain类,并将Index1与Index2串联起来
package Index;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob;
import org.apache.hadoop.mapreduce.lib.jobcontrol.JobControl;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class IndexMain {
public static void main(String[] args) throws IOException, InterruptedException {
args = new String[]{"E:\\bigdata_code\\index",
"E:\\bigdata_code\\index\\out1",
"E:\\bigdata_code\\index\\out2"};
Configuration conf = new Configuration();
Job job1 = Job.getInstance(conf);
job1.setMapperClass(Index1Map.class);
job1.setReducerClass(Index1Reduce.class);
job1.setMapOutputKeyClass(Text.class);
job1.setMapOutputValueClass(IntWritable.class);
job1.setOutputKeyClass(Text.class);
job1.setOutputValueClass(IntWritable.class);
//判断输出路径是否存在
Path path = new Path(args[1]);
FileSystem fs = FileSystem.get(conf);
if(fs.exists(path)) {
fs.delete(path, true);
}
FileInputFormat.setInputPaths(job1, new Path(args[0]));
FileOutputFormat.setOutputPath(job1, path);
Job job2 = Job.getInstance(conf);
job2.setMapperClass(Index2Map.class);
job2.setReducerClass(Index2Reduce.class);
job2.setMapOutputKeyClass(Text.class);
job2.setMapOutputValueClass(Text.class);
job2.setOutputKeyClass(Text.class);
job2.setOutputValueClass(Text.class);
//判断输出路径是否存在
Path path1 = new Path(args[2]);
if(fs.exists(path1)) {
fs.delete(path1, true);
}
FileInputFormat.setInputPaths(job2, new Path(args[1]));
FileOutputFormat.setOutputPath(job2, path1);
//分别创建两个controlledJob对象,处理两个mapreduce程序。
ControlledJob ajob = new ControlledJob(job1.getConfiguration());
ControlledJob bjob = new ControlledJob(job2.getConfiguration());
//创建一个管理组control,用于管理创建的controlledJob对象,自定义组名
JobControl control = new JobControl("zhang");
//两个任务的关联方式
bjob.addDependingJob(ajob);
//addJob方法添加进组
control.addJob(ajob);
control.addJob(bjob);
//设置线程对象来启动job。通过start方法。
Thread thread = new Thread(control);
thread.start();
while(!control.allFinished()){
Thread.sleep(1000);
}
System.exit(0);
}
}
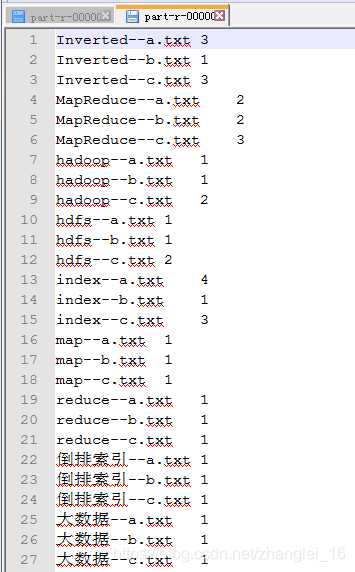
Index1的输出数据:
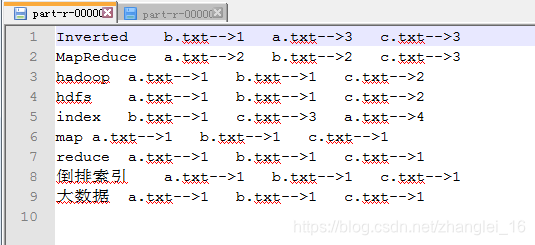
Index2的输出最终结果:

















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









