







我们知道DataNode一个重要的功能就是管理磁盘存储的数据块,DataNode将这个功能切分为2个部分:管理与组织磁盘目录,由DataStorage实现;管理与组织数据块及其元数据,这部分由FSDatasetImpl实现。
在这里,我们先分析DataStorage:
StorageInfo:用于描述存储的基本信息
核心字段:
publicint layoutVersion;
publicint namespaceID;
public StringclusterID;
publiclong cTime;
NodeType:DataNode/NameNode/JournalNode
protectedfinal NodeType storageType;
这些定义的信息都存储在VERSION文件里
StorageState:一个枚举类,列出了存储空间所有可能出现的状态,比如在升级,回滚,升级提交等操作的时候,节点的存储空间可能出现各种异常,列入断点,宕机等,这个时候存储空间就可能处于某种中间状态。有利于从HDFS从错误中恢复过来。
StorageDirectory:我们知道DataNode和 NameNode可以定义多个多个存储目录来存储数据,StorageDirectory定义了管理存储目录的通用方法,简而言之,就是StorageDirectory可以用于管理DataNode或者NameNode定义的存储目录。
有几个比较重要的字段:
//存储根目录
final Fileroot;
//目录是否是共享目录,因为对于HDFSFederation或者HA,他们可能会共享一些存储目录
finalboolean isShared;
//存储目录类型
finalStorageDirType dirType;
//独占锁,支持Data Node或者 Name Node独占某个存储目录
FileLocklock;
//该存储目录的唯一标识符
private StringstorageUuid = null;
比较重要的方法:
StorageDirectroy方法主要分为三类:
获取文件夹相关操作
getCurrentDir、getPreviousDir
加锁/解锁操作
tryLock/unLock
存储状态恢复
比如DataNode在执行升级,提交,回滚操纵的时候,有可能会遇到一些特殊情况,比如断点,宕机等,在DataNode重启的时候,我们又该如何恢到上一次中断的操作呢?StorageDirectory会首先调用analyzeStorage方法分析当前节点所处的状态,然后调用doRecover进行恢复。
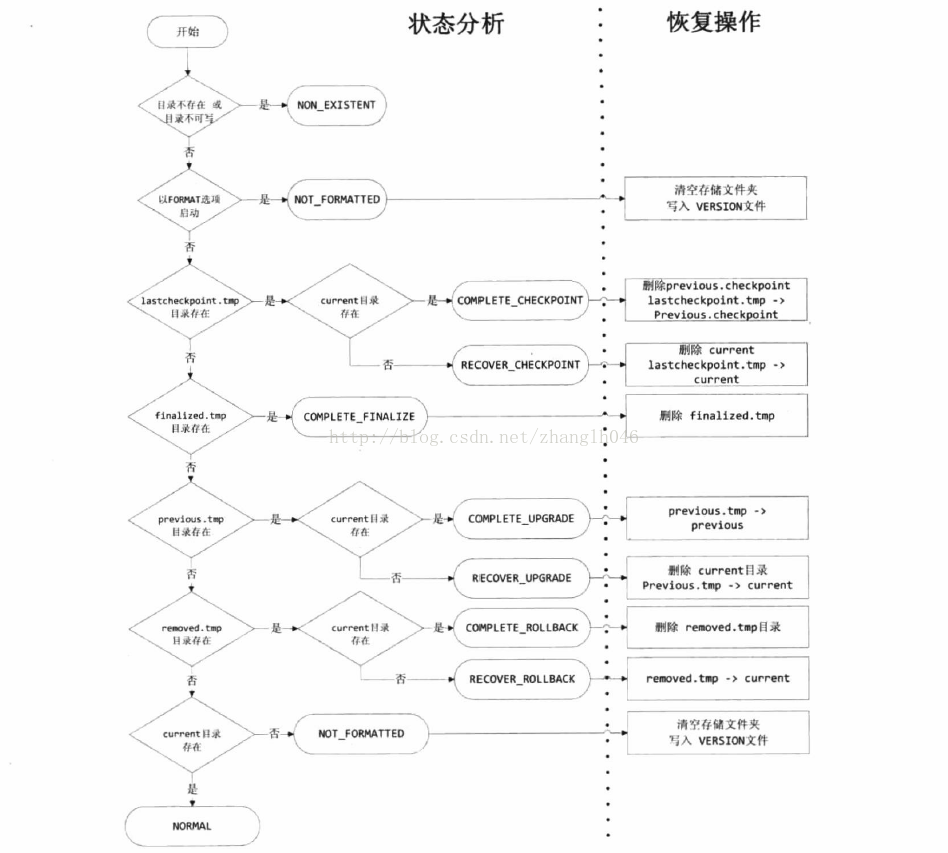
Storage:
是一个抽象类,为NameNode,DataNode提供抽象的存储服务。管理着当前节点所有存储的目录,每一个目录都是由StorageDirectory
来管理,storageDirs代表着这个Storage所管理的所有的StorageDirectory,并通过DirIterator进行遍历。
本地存储信息是存储在VERSION文件里的,它包含了节点类型,layout版本,namespaceId,clusterId
本地存储可以存储在多个存储目录里面,每一个目录都包含相同的VERSION文件,hadoop启动的时候会会读取这些本地存储的文件信息
DataNode 对每一个存储目录持有一个锁,用于防止多个DataNode启动而修改这个共享存储目录
DataStorage:继承自Storage类,提供管理存储空间的功能。
在HDFS 联盟的模式下,一个DataNode可以保存多个命名空间的数据块,每一个命名空间在DataNode磁盘上都有一个独立的BlockPool
这个Pool会分布在DataNode所有存储目录下,他们共同保存了这个Pool在当前DataNode上的所有数据块。 HDFS定义了Block
PoolSliceStorage用于管理单个BlockPool的存储空间,DataStorage类定义了bpStorageMap字段保存DataNode上所有BlockPool的
BlockPoolSliceStorage对象的引用
DataNode在启动的时候,会调用DataStorage提供的方法初始化Data
Node的存储空间,在HDFS联盟架构中,DataNode会保存多个命名空间的数据块,对于每一个命名空间,DataNode都会构造一个BPOfferService类维护与这个命名空间NameNode的通信,当BPOfferService中的BPServiceActor类与该命名空间的NameNode握手成功以后,就会调用initBlockPool初始化该命名空间的BlockPool
















 292
292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











